Viterbi解码器的HDL代码生成
这个例子展示了对Viterbi Decoder块的HDL代码生成支持。金宝app它展示了如何检查、生成和验证从定点Viterbi Decoder模型生成的HDL代码。本例还讨论了可用于更改生成的HDL代码的设置。
简介
该模型展示了用于软决策卷积译码的定点维特比译码器块的HDL代码生成。要了解有关Viterbi Decoder的HDL金宝app支持的更多信息,请参阅HDL代码生成文档中的块页部分。
打开模型,执行以下命令:
modelname =“hdlcoder_commviterbi”;open_system (modelname);

在这个模型中,顶层子系统维特比解码器子系统包含维特比解码器块。使用实例打开该子系统。
Systemname = [modelname ./维特比解码器子系统];open_system (systemname);

维特比译码算法
维特比解码算法有三个主要组成部分。它们是分支度量计算(BMC)、添加-比较-选择(ACS)和回溯解码。下图展示了维特比译码算法中的三个单元:

重整化方法
维特比解码器通过在每个时间步中减去状态度量的最小值来防止ACS组件中的状态度量溢出,如下图所示:

在一个时钟周期内获得所有状态度量元素的最小值将导致电路的时钟频率较差。增加管道寄存器可以提高电路的性能。但是,简单地从状态度量中减去管道寄存器延迟的最小值仍然可能导致溢出。硬件结构对重整方法进行了改进,分三步避免了状态度量溢出。首先,该体系结构根据网格结构和软决策位的数量计算阈值和步长参数的值。其次,将延迟最小值与阈值进行比较。最后,如果最小值大于或等于阈值,则实现从状态度量中减去步长值;否则不进行调整。修改后的重整化方法如下图所示:

最佳状态度量字长计算
硬件实现计算状态度量的最佳字长,并将其与您为块指定的值进行比较。如果该值小于您指定的值,则硬件体系结构将使用最佳值。在HDL代码生成期间,将显示一条消息来显示该值。如果计算值大于指定的值,则报告错误消息,并显示最优值。
如果您指定的值太大,则在硬件实现中应用计算出的最佳状态度量字长可能会显著减少硬件资源。例如,如果您设置16位作为状态度量字长,但实现相同的数值结果只需要9位,那么在硬件架构中应用计算出的最佳状态度量字长可以节省大约40%的寄存器资源。计算出的一些典型格架的最优状态度量字长如下表所示:

定点维特比模型的检查和生成代码
该模型对DVB速率1/2,约束长度7,(171,133)的卷积码进行3位软决策解码。解码器以连续模式运行,回溯深度为32。状态度量字长设置为16位。为了验证Viterbi Decoder块的参数设置,可以运行以下命令:
Workingdir = tempname;
checkhdl (systemname TargetDirectory, workingdir);
运行checkhdl会生成以下消息:
的默认值TracebackStagesPerPipeline.有关此参数的更多信息可以在本节中找到流水线基于寄存器的回溯单元,
HDL代码中使用的状态度量字长与块掩码上设置的字长相比,
管道寄存器相对于原始Viterbi块引入的总延迟。
为包含Viterbi Decoder块的子系统生成HDL,运行以下命令:workingdir = tempname;makehdl (systemname TargetDirectory, workingdir);
顶级VHDL文件名与模型中块的名称相匹配。中生成的Viterbi_Decoder组件Viterbi_Decoder.vhd包含三个组件:BranchMetric、ACS和Traceback。ACS和Traceback组件分别实例化ACSUnit和TracebackUnit组件多次。数据类型定义包含在包文件中Viterbi_Decoder_Subsystem_pkg.vhd.
为包含Viterbi Decoder块的子系统生成一个测试平台,运行以下命令:makehdltb(systemname,'TargetDirectory',workingdir);
回溯单元的优化
它们是优化回溯单元的两种方法:流水线化基于寄存器的回溯或使用基于ram的回溯体系结构。
流水线基于寄存器的回溯单元
Viterbi Decoder块通过您为块定义的回溯深度来对每个位进行解码。由于块对每个决策位都实现了完整的回溯,因此使用寄存器在回溯解码单元中存储最小状态索引和分支决策。为了提高所生成电路的性能,这个单元可以被流水线化。通过指定每个管道寄存器的回溯阶段数,可以将管道寄存器添加到回溯单元。可以通过设置TracebackStagesPerPipeline在HDL块属性对话框中的Viterbi解码器的实现参数。右击维特比解码器块以导航到HDL块属性菜单。

将属性值设置为4会导致为模型中的每四个回溯单元插入一个管道寄存器,如下图所示:

TracebackStagesPerPipeline实现参数为您提供了一种基于系统需求平衡电路性能的方法。参数值越小,表示需要添加更多寄存器来提高回溯电路的速度。增加寄存器的数量会导致寄存器的使用减少,同时电路速度也会降低。在我们的实验中,速率为1/2,约束长度为7,(171,133)卷积码,将TracebackStagesPerPipeline参数从4调整为8,将管道寄存器的使用减少一半,电路速度从173MHz更改为94 MHz。
基于ram的回溯
您可以选择使用ram来保存幸存分支信息,而不是使用寄存器。这可以通过将Viterbi Decoder块的HDL Architecture属性设置为基于ram的Traceback来实现。

基于寄存器的回溯体系结构和基于ram的回溯体系结构之间有两个主要区别。
首先,基于寄存器的实现将回溯和解码操作合并到一个步骤中,并使用从最小操作中找到的最佳状态作为解码初始状态。基于ram的实现通过一组数据进行回溯,以找到解码前一组数据的初始状态。
其次,基于寄存器的实现在完成trackback后解码一位;而基于ram的实现可以追溯到米样本,解码之前米位逆序排列,并在每个时钟周期按顺序释放一位。
由于两种回溯算法的不同,基于ram的实现与基于寄存器的回溯产生不同的数值结果。建议在基于ram的回溯中使用更长的回溯深度,例如约束长度的10倍,以实现与基于寄存器的实现类似的误码率(BER)。
实现所需的RAM大小取决于网格和回溯深度。下表总结了一些典型网格结构的RAM使用情况。
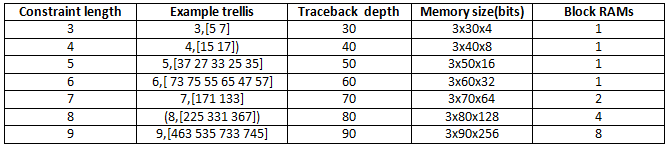
我们对速率1/2,约束长度7,(171,133)卷积码的实验表明,在合成中使用类似时钟约束的基于ram的回溯单元比基于寄存器的回溯单元少使用90%的寄存器(每4阶段流水线一次)。这两种实现提供了一种寄存器- ram折衷方案,可以根据单独的设计进行调整。
选择引用
克拉克,G. C. Jr.,比布·凯恩,数字通信纠错编码,纽约,全会出版社,1981年。
G. Feygin和P. G. Gulak,“Viterbi解码器中幸存者序列内存管理的架构权衡”,IEEE通讯汇刊,第41卷,no。3, 1993年3月,第425-429页。
您也可以从以下列表中选择一个网站: