主要内容
在Simulink中预测和更新网络状态金宝app
这个例子展示了如何在Simulink®中使用金宝app有状态的预测块。这个例子使用了预先训练的长短期记忆(LSTM)网络。
负载净化网络
负载JapaneseVowelsNet,在[1]和[2]所述的日语元音数据集上训练的长短期记忆网络。该网络在按序列长度排序的序列上进行训练,最小批大小为27。
负载JapaneseVowelsNet
查看网络架构。
Net.Layers.
ans x1 = 5层阵列层:1“sequenceinput”序列输入序列输入12维度2的lstm lstm lstm 100隐藏单位3 fc的完全连接9完全连接层4的softmax softmax softmax 5 classoutput的分类输出crossentropyex ' 1 ', 8其他类
负载测试数据
加载日语元音测试数据。XTest.是包含370个长度为12的可变序列的单元数组。欧美为标签“1”,“2”,…“9”,对应9个发言者。
[xtest,ytest] =日本韦沃尔斯特迪塔x = xtest {94};numtimesteps = size(x,2);
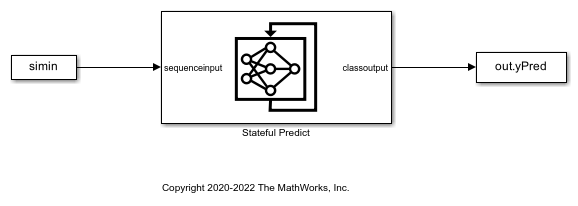
金宝app预测反应的Simulink模型
用于预测金宝app响应的Simulink模型包含一个有状态的预测块来预测分数和MATLAB函数块以按时间步骤加载输入数据序列。
open_system (“StatefulPredictExample”);
配置仿真模型
为输入块设置模型配置参数有状态的预测块。
set_param (“StatefulPredictExample /输入”,“价值”,“X”);set_param (“StatefulPredictExample /指数”,“uplimit”,“numTimeSteps-1”);set_param (“StatefulPredictExample /状态预测”,'networkfilepath','Japanesevowelsnet.mat');set_param (“StatefulPredictExample”,“SimulationMode”,“正常”);
运行仿真
来计算响应JapaneseVowelsNet网络,运行模拟。预测分数保存在MATLAB®工作空间中。
= sim卡(“StatefulPredictExample”);
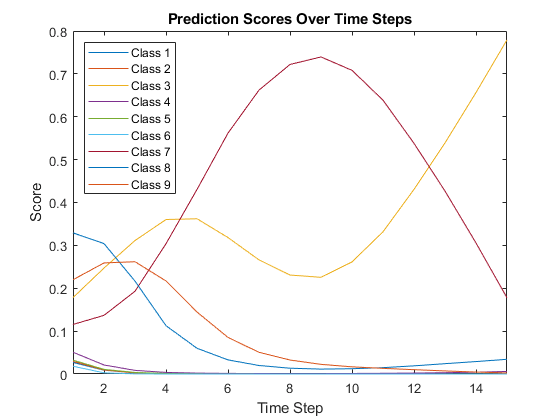
绘制预测得分。该图显示了预测分数在时间步间的变化。
成绩=挤压(out.yPred.Data (:,: 1: numTimeSteps));一会=字符串(net.Layers(结束). class);Figure lines = plot(scores');传说numTimeSteps xlim ([1]) (“类”+类名,'地点',“西北”)Xlabel(“时间步”)ylabel(“分数”)标题(“预测分数随时间的变化”)
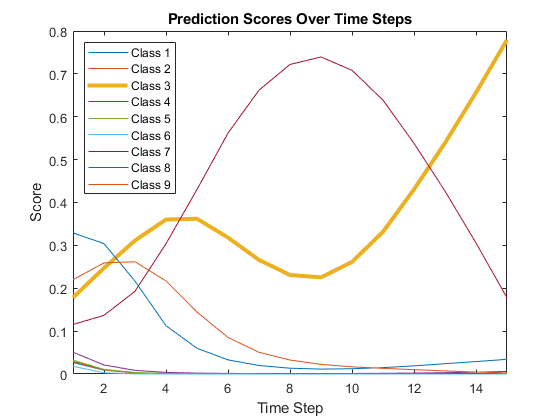
突出显示正确类随时间步长的预测得分。
trueLabel =欧美(94);行(trueLabel)。线宽= 3;
在条形图中显示最后的时间步长预测。
图酒吧(分数(:,结束))标题(“最终预测评分”)Xlabel(“类”)ylabel(“分数”)

参考
[1] M. Kudo,J. Toyama和M. Shimbo。“使用过度区域的多维曲线分类。”模式识别的字母。第20卷,第11-13期,第1103-1111页。
[2]UCI机器学习存储库:日语元音数据集。https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
另请参阅
相关话题
你也可以从以下列表中选择一个网站:
