总结
显示矢量误差校正(VEC)模型的估计结果
描述
例子
估计VEC模型
考虑以下七个宏观经济系列的VEC模型,然后将模型与数据拟合。
国内生产总值(GDP)
GDP隐性价格平减指数
员工薪酬
所有人的非农业务部门工作时间
实际联邦基金利率
个人消费支出
国内私人投资总额
假设协整秩为4和一个短期项是合适的,即考虑VEC(1)模型。
加载Data_USEconVECModel数据集。
负载Data_USEconVECModel
有关数据集和变量的更多信息,请输入描述在命令行。
通过在单独的图上绘制序列来确定是否需要对数据进行预处理。
图;次要情节(2、2、1)情节(FRED.Time FRED.GDP);标题(“本地生产总值”);ylabel (“指数”);包含(“日期”);次要情节(2 2 2)情节(FRED.Time FRED.GDPDEF);标题(“GDP平减指数”);ylabel (“指数”);包含(“日期”);次要情节(2,2,3)情节(FRED.Time FRED.COE);标题(“已付雇员补偿”);ylabel (“数十亿美元”);包含(“日期”);次要情节(2,2,4)情节(FRED.Time FRED.HOANBS);标题(“非农业行业营业时间”);ylabel (“指数”);包含(“日期”);

图;次要情节(2、2、1)情节(FRED.Time FRED.FEDFUNDS);标题(“联邦基金利率”);ylabel (“百分比”);包含(“日期”);次要情节(2 2 2)情节(FRED.Time FRED.PCEC);标题(“消费支出”);ylabel (“数十亿美元”);包含(“日期”);次要情节(2,2,3)情节(FRED.Time FRED.GPDI);标题(“国内私人投资总额”);ylabel (“数十亿美元”);包含(“日期”);
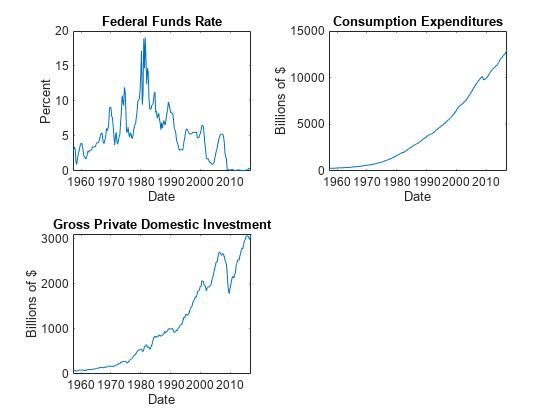
通过应用对数变换,稳定除联邦基金利率外的所有系列。将生成的系列按100缩放,以便所有系列都在相同的比例上。
弗雷德。GDP = 100*log(FRED.GDP);弗雷德。GDPDEF = 100*log(FRED.GDPDEF);弗雷德。COE = 100*log(FRED.COE);弗雷德。HOANBS = 100*log(FRED.HOANBS);弗雷德。PCEC = 100*log(FRED.PCEC); FRED.GPDI = 100*log(FRED.GPDI);
使用简写语法创建VEC(1)模型。指定变量名。
Mdl = vecm(7,4,1);Mdl。SeriesNames = FRED.Properties.VariableNames
Mdl = vecm与属性:说明:“7维秩= 4 VEC(1)模型与线性时间趋势”SeriesNames:“GDP”“GDPDEF”“COE”…和4更NumSeries: 7等级:4 P: 2常数:[7×1的向量nan]调整:[7×4矩阵nan)协整:[7×4矩阵nan)影响:[7×7矩阵nan] CointegrationConstant:[4×1的向量nan] CointegrationTrend:[4×1的向量nan]短期的:{7×7矩阵nan}在滞后[1]的趋势:[7×1的向量nan]β:协方差矩阵[7×0]:[7×7矩阵nan)
Mdl是一个结果模型对象。所有属性包含南值对应于给定数据要估计的参数。
使用整个数据集和默认选项估计模型。
EstMdl =估计(Mdl,FRED.Variables)
EstMdl = vecm属性:描述:“7维Rank = 4 VEC(1)模型”SeriesNames:“GDP”“GDPDEF”“COE”…和4更多NumSeries: 7排名:4 P: 2常量:[14.1329 8.77841 -7.20359…调整:[7×4矩阵]协整:[7×4矩阵]影响:[7×7矩阵]协整常量:[-28.6082 109.555 -77.0912…and 1 more]' CointegrationTrend: [4×1 vector of zero] ShortRun: {7×7 matrix} at lag[1]趋势:[7×1 vector of zero] Beta: [7×0 matrix]协方差:[7×7 matrix]
EstMdl是估计的结果模型对象。它是完全指定的,因为所有参数都有已知值。默认情况下,估计通过从模型中去除协整趋势项和线性趋势项,对H1 Johansen VEC模型形式施加约束。从估计中排除参数相当于将相等约束施加到零。
显示评估的简短摘要。
结果= summary (EstMdl)
结果=带字段的结构:描述:“7维Rank = 4 VEC(1)模型”模型:“H1”SampleSize: 238 NumEstimatedParameters: 112 LogLikelihood: -1.4939e+03 AIC: 3.2118e+03 BIC: 3.6007e+03 Table: [133x4 Table]协方差:[7x7 double]相关性:[7x7 double]
的表格领域的结果是一个表的参数估计和相应的统计。
比较几种VEC模型拟合
中的模型和数据估计VEC模型以及这四种可供选择的VEC模型:VEC(0)、VEC(1)、VEC(3)和VEC(7)。使用历史数据,估计四个模型中的每一个,然后使用得到的贝叶斯信息准则(BIC)比较模型的拟合。
加载Data_USEconVECModel数据集和预处理数据。
负载Data_USEconVECModel弗雷德。GDP = 100*log(FRED.GDP);弗雷德。GDPDEF = 100*log(FRED.GDPDEF);弗雷德。COE = 100*log(FRED.COE);弗雷德。HOANBS = 100*log(FRED.HOANBS);弗雷德。PCEC = 100*log(FRED.PCEC); FRED.GPDI = 100*log(FRED.GPDI);
在循环中:
使用简写语法创建VEC模型。
估计VEC模型。保留的最大值p作为预先观察。
存储估计结果。
Numlags = [0 1 3 7];P = numlags + 1;Y0 = FRED{1:max(p),:};Y = FRED{((max(p) + 1):end),:};为j = 1:数字(p) Mdl = vecm(7,4,numlag (j));EstMdl =估计(Mdl,Y,“Y0”, Y);results(j) = summary (EstMdl);结束
结果是一个4乘1结构数组,包含每个模型的估计结果。
从每组结果中提取BIC。
BIC = [results.]BIC)
BIC =1×4103.× 5.3948 5.4372 5.8254 6.5536
所考虑的模型中,最低BIC对应的模型拟合最好。因此,VEC(0)模型是最佳拟合模型。
输入参数
输出参数
参考文献
[1]约翰森,S。协整向量自回归模型中的似然推理。牛津:牛津大学出版社,1995年。
版本历史
您也可以从以下列表中选择一个网站: