工作流程
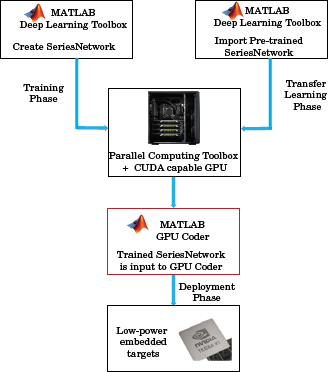
在典型的卷积神经网络(CNN)工作流程中,您从使用Deep Learning Toolbox™构建CNN体系结构开始,然后与Parallel Computing Toolbox™一起训练网络。或者,您可以导入Convnet已经在大型数据集上进行了培训,并传输了学习的功能。转移学习意味着对一组分类问题进行了培训的CNN,并将其重新训练以对不同的类别进行分类。在这里,CNN的最后几层重新学习。同样,在学习阶段使用并行计算工具箱。您还可以从Caffe或Matconvnet等其他框架中导入训练有素的CNN网络中系列网络目的。
获得训练的网络后,您可以使用GPU CODER™生成C ++或CUDA®代码并在使用NVIDIA的多个嵌入式平台上部署CNN®或手臂®GPU处理器。生成的代码通过使用您在输入中指定的体系结构,图层和参数来实现CNN系列网络(深度学习工具箱)或者dagnetwork(深度学习工具箱)目的。
代码生成器利用NVIDIA CUDA深神经网络库(CUDNN),NVIDIA TENSORRT™高性能推理库,用于NVIDIA GPU和ARM计算库用于手臂Mali GPU的计算机视觉和机器学习。
生成的代码可以作为源代码,静态或动态库或可执行文件集成到您的项目中,您可以将其部署到各种NVIDIA和ARM MALI GPU平台中。为了对ARM Mali GPU目标进行深入学习,您可以在主机开发计算机上生成代码。然后,要构建并运行可执行程序,将生成的代码移至ARM目标平台。
也可以看看
功能
对象
coder.gpuconfig|Coder.CodeConfig|Coder.embeddedCodeConfig|coder.gpuenvconfig|Coder.CudnnConfig|coder.tensorrtconfig
相关话题
- 预处理的深神经网络(深度学习工具箱)
- 开始转移学习(深度学习工具箱)
- 创建简单的深度学习网络进行分类(深度学习工具箱)
- 金宝app支持的网络,层和类
- 加载预告片的网络以生成代码
- 使用Cudnn的深度学习网络代码生成
- 深度学习网络的代码生成
- 针对ARM MALI GPU的深度学习网络的代码生成
您还可以从以下列表中选择一个网站:
美洲
- AméricaLatina(Español)
- 加拿大(英语)
- 美国(英语)