创建简单的深度学习网络进行分类
这个例子展示了如何创建和训练一个简单的卷积神经网络来进行深度学习分类。卷积神经网络是深度学习的基本工具,尤其适用于图像识别。
这个例子演示了如何:
加载和浏览图像数据。
定义网络体系结构。
指定培训选项。
培训网络。
预测新数据的标签,计算分类精度。
加载和浏览图像数据
将数字样本数据作为图像数据存储加载。imageDatastore根据文件夹名自动标记图像,并将数据存储为ImageDatastore对象。图像数据存储使您能够存储大型图像数据,包括不适合存储在内存中的数据,并在训练卷积神经网络时有效地读取成批图像。
digitDatasetPath = fullfile (matlabroot,“工具箱”,“nnet”,“nndemos”,…“nndatasets”,“DigitDataset”);IMDS = imageDatastore(digitDatasetPath,…“IncludeSubfolders”,真的,“LabelSource”,“foldernames”);
在数据存储中显示一些图像。
数字;烫发= randperm(10000,20);为i = 1:20 subplot(4,5,i);imshow (imds.Files{烫发(i)});结束

计算每个类别中的图像数量。labelCount是一个包含标签和具有每个标签的图像数量的表。对于总共10000个图像,数据存储中每个数字0-9都包含1000个图像。可以将网络的最后一个完全连接层中的类数指定为OutputSize论点。
labelCount = countEachLabel (imd)
labelCount =10×2表1 . Label Count标签数量1 . Label Count标签数量2 . Label Count标签数量3 . Label Count标签数量
您必须在网络的输入层中指定图像的大小。检查第一个图像的大小digitData。每个图像都是28×28×1像素。
img = readimage (imd, 1);大小(img)
ans =1×228日28日
指定培训和验证集
将数据划分为训练和验证数据集,这样训练集中的每个类别包含750个图像,验证集包含来自每个标签的其余图像。splitEachLabel将数据存储digitData变成两个新的数据存储,trainDigitData和valDigitData。
numTrainFiles = 750;[imdsTrain,imdsValidation] = splitEachLabel(IMDS,numTrainFiles,“随机”);
定义网络体系结构
定义卷积神经网络体系结构。
layer = [imageInputLayer([28281]) convolution2dLayer(3,8,“填充”,'相同'maxPooling2dLayer(2,“步”,2)convolution2dLayer(3,16,“填充”,'相同'maxPooling2dLayer(2,“步”32岁的,2)convolution2dLayer (3“填充”,'相同')batchNormalizationLayer reluLayer fullyConnectedLayer(10)softmaxLayer classificationLayer];
图像输入层一个imageInputLayer是指定图像大小的地方,在本例中是28×28×1。这些数字对应于高度、宽度和通道大小。数字数据由灰度图像组成,因此通道大小(颜色通道)为1。对于彩色图像,通道大小为3,对应于RGB值。您不需要重新洗牌数据,因为trainNetwork默认情况下,在训练开始洗牌的数据。trainNetwork还可以自动洗牌数据在每一个纪元开始时的训练。
卷积的层在卷积层中,第一个参数是filterSize,即训练函数在扫描图像时使用的滤波器的高度和宽度。在本例中,数字3表示过滤器大小为3×3。您可以为过滤器的高度和宽度指定不同的大小。第二个参数是过滤器的数量,numFilters,即连接到输入信号相同区域的神经元的数量。这个参数决定了特征图的数量。使用“填充”名称-值对,用于向输入功能映射添加填充。对于默认步长为1的卷积层,'相同'填充确保了空间输出大小是一样的输入大小。您还可以使用的名称 - 值对的参数定义该层的步幅和学习率convolution2dLayer。
批归一化层批处理规范化层对在网络中传播的激活和梯度进行规范化,使网络训练成为一个更简单的优化问题。在卷积层和非线性层之间使用批量归一化层,如ReLU层,加快网络训练,降低对网络初始化的敏感性。使用batchNormalizationLayer创建批标准化层。
RELU层批处理归一化层之后是一个非线性激活函数。最常见的激活函数是整流线性单元(ReLU)。使用reluLayer创建一个ReLU层。
马克斯池层卷积层(带有激活函数)之后,有时会进行降采样操作,以减小特征图的空间大小,并删除冗余的空间信息。下采样使得在不增加每层所需的计算量的情况下增加更深层次的卷积层中的过滤器的数量成为可能。向下采样的一种方法是使用最大池,您可以使用它来创建maxPooling2dLayer。max pooling层返回输入矩形区域的最大值,由第一个参数指定,poolSize。在这个例子中,矩形区域的大小是[2,2]。的“步”名称-值对参数指定训练函数在扫描输入时所采取的步长。
完全连接层卷积和下采样层,接着通过一个或多个完全连接层。正如其名称所暗示的,一个完全连接层是其中神经元连接到所有神经元前述层中的层。该层结合了所有的功能通过在图像的前面的层学会了识别较大的图案。最后完全连接层结合的特征对图像进行分类。因此,OutputSize最后一个全连接层中的参数等于目标数据中的类数。在本例中,输出大小为10,对应于10个类。使用fullyConnectedLayer创建完全连接层。
Softmax层softmax激活函数对全连接层的输出进行规范化。softmax层的输出由正的数字组成,这些数字的和为1,然后可以被分类层用作分类概率。使用。创建一个softmax层softmaxLayer功能后的最后一个完全连接层。
分类层最后一层是分类层。该层使用softmax激活函数为每个输入返回的概率将输入分配给一个互斥类并计算损失。要创建分类层,请使用classificationLayer。
指定培训选项
定义网络结构之后,指定培训选项。使用具有动量的随机梯度下降(SGDM)训练网络,初始学习率为0.01。将最大的epoch数量设置为4。epoch是整个训练数据集上的完整训练周期。通过指定验证数据和验证频率来监视训练期间的网络准确性。在每个历元中重新洗牌数据。软件根据训练数据对网络进行训练,并在训练期间定期计算验证数据的准确性。验证数据不用于更新网络权重。打开训练进度图,关闭命令窗口输出。
选择= trainingOptions (“个”,…“InitialLearnRate”,0.01,…“MaxEpochs”4…“洗牌”,“每个历元”,…“ValidationData”imdsValidation,…'ValidationFrequency'30,…“详细”,假,…“阴谋”,“训练进步”);
利用训练数据训练网络
培养使用由限定的体系结构的网络层、培训数据和培训选项。默认情况下,trainNetwork使用GPU(如果可用)(需要并行计算工具箱™和启用CUDA®GPU计算能力3.0或更高版本)。否则,它使用一个CPU。您也可以通过指定执行环境“ExecutionEnvironment”的名-值对参数trainingOptions。
训练进度图显示了小批量的损失和准确性,确认损失和准确性。有关训练进度情节的详细信息,请参阅监控深度学习培训的进展。损失就是交叉熵损失。准确率是指网络正确分类图像的百分比。
净= trainNetwork(imdsTrain,层,选项);
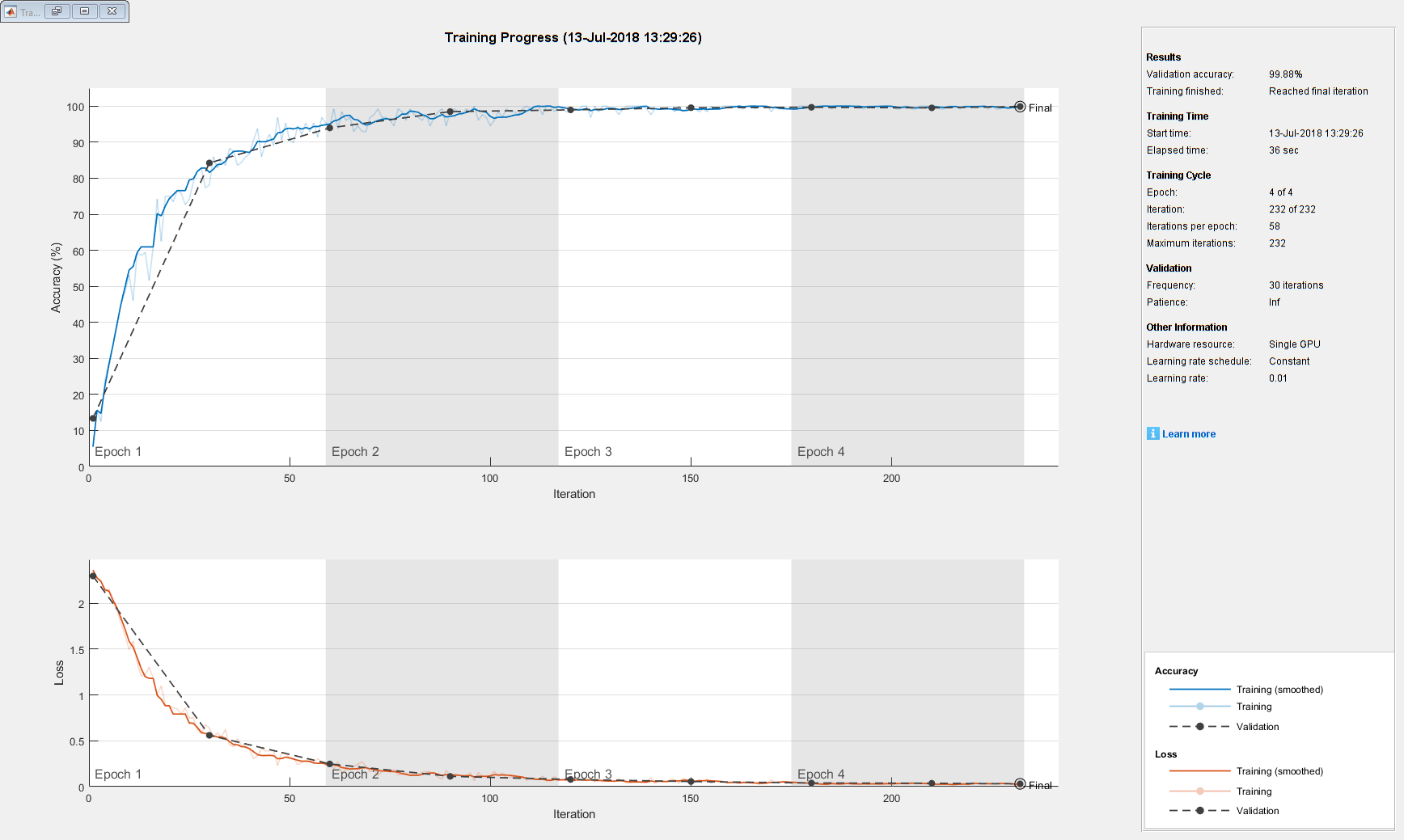
对验证图像进行分类并保证计算的准确性
预测用训练网络验证数据的标签,并计算出最终验证准确性。准确性是标签,网络正确地预测分数。在这种情况下,预测标签的99%以上匹配验证集的真实标签。
YPred =分类(净,imdsValidation);YValidation = imdsValidation.Labels;准确率= sum(YPred == YValidation)/numel(YValidation)
精度= 0.9988
另请参阅
深层网络设计师|analyzeNetwork|trainNetwork|trainingOptions
相关话题
你也可以从以下列表中选择一个网站:
