预先训练的深度神经网络
你可以使用一个已经学会从自然图像中提取强大且信息丰富的特征的预先训练的图像分类网络,并将其作为学习新任务的起点。大多数预先训练的网络都是在ImageNet数据库的一个子集上训练的[1],用于ImageNet大规模视觉识别挑战赛(ILSVRC)[2].这些网络已经训练了超过100万幅图像,并可以将图像分为1000个对象类别,如键盘、咖啡杯、铅笔和许多动物。使用带有迁移学习的预先训练的网络通常比从头开始训练网络更快、更容易。
你可以使用以前训练过的网络来完成以下任务:
| 目的 | 描述 |
|---|---|
| 分类 | 将预先训练好的网络直接应用于分类问题。要对新图像进行分类,请使用 |
| 特征提取 | 利用层激活作为特征,使用预先训练的网络作为特征提取器。您可以使用这些激活作为特征来训练另一个机器学习模型,例如支持向量机(SVM)。金宝app有关更多信息,请参见特征提取.例如,请参见利用预训练网络提取图像特征. |
| 转移学习 | 从一个在大数据集上训练过的网络中提取层次,并对一个新的数据集进行微调。有关更多信息,请参见转移学习.有关一个简单的示例,请参见开始迁移学习.尝试更多的预先训练的网络,看训练深度学习网络对新图像进行分类. |
比较Pretrained网络
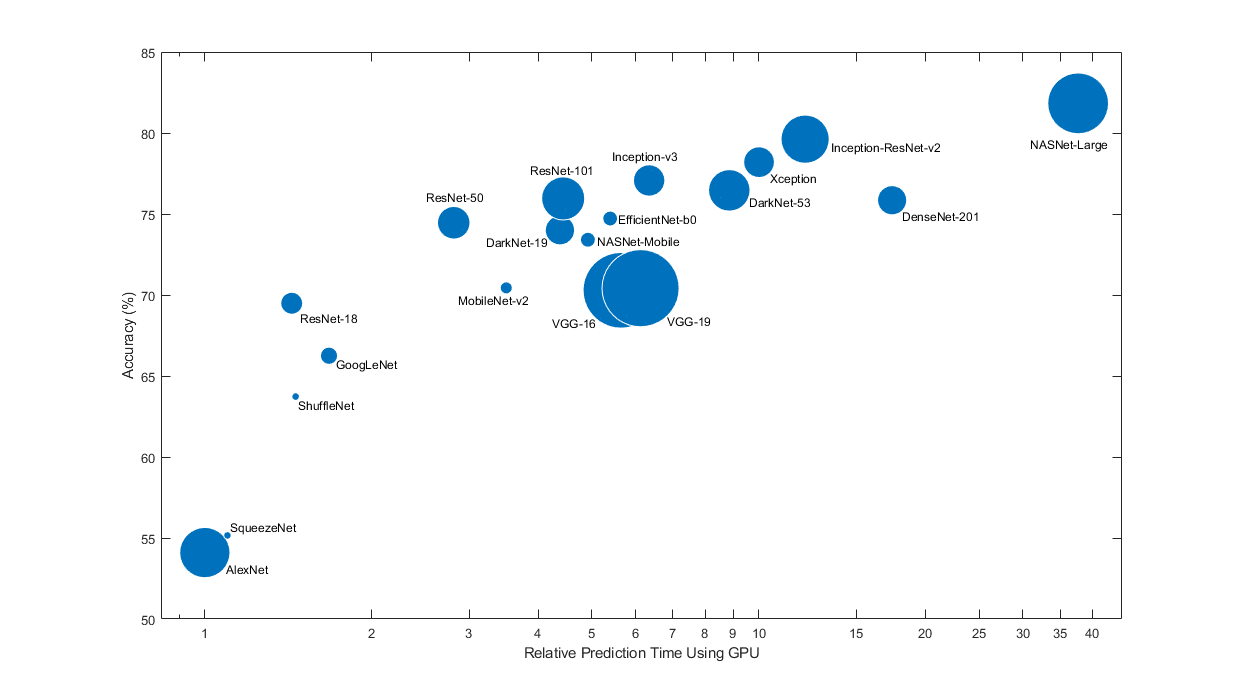
预先训练的网络有不同的特点,这在选择网络应用于你的问题时很重要。最重要的特征是网络的准确性、速度和大小。选择一个网络通常是在这些特征之间的权衡。使用下面的图来比较ImageNet验证的准确性和使用网络进行预测所需的时间。
提示
要开始迁移学习,试着选择一个速度较快的网络,如SqueezeNet或GoogLeNet。然后,您可以快速迭代并尝试不同的设置,如数据预处理步骤和培训选项。一旦你感觉哪种设置比较好,尝试更精确的网络,如Inception-v3或ResNet,看看是否能改善你的结果。
笔记
上图仅显示了不同网络的相对速度。准确的预测和训练迭代时间取决于您使用的硬件和小批量大小。
一个好的网络具有较高的准确性和速度。该图显示了使用现代GPU (an英伟达®特斯拉®P100)和128个小批量。预测时间是相对于最快的网络进行测量的。每个标记的面积与磁盘上的网络大小成比例。
ImageNet验证集上的分类准确性是衡量在ImageNet上训练的网络的准确性最常用的方法。在ImageNet上准确的网络,在使用迁移学习或特征提取将它们应用到其他自然图像数据集时,通常也是准确的。这种泛化是可能的,因为网络已经学会从自然图像中提取强大的、信息丰富的特征,从而泛化到其他类似的数据集。然而,ImageNet上的高精度并不总是直接传输到其他任务,因此尝试多个网络是一个好主意。
如果您想使用受限的硬件或通过Internet分发网络来执行预测,那么也要考虑磁盘和内存中网络的大小。
网络的准确性
在ImageNet验证集上有多种方法来计算分类精度,不同的来源使用不同的方法。有时使用多个模型的集合,有时使用多个作物对每个图像进行多次评估。有时引用的是前5位精度而不是标准(前1)精度。由于这些差异,通常不可能直接比较来自不同来源的准确性。深度学习工具箱™中预训练网络的精度是标准的(top-1)精度,使用单一模型和单一中心图像裁剪。
负载Pretrained网络
要加载SqueezeNet网络,输入squeezenet在命令行。
网= squeezenet;
对于其他网络,请使用以下功能:googlenet从Add-On Explorer获取下载预先训练过的网络的链接。
下表列出了在ImageNet上训练的可用预训练网络及其一些属性。网络深度定义为从输入层到输出层的路径上顺序卷积层或全连接层的最大数量。所有网络的输入都是RGB图像。
| 网络 | 深度 | 大小 | 参数(百万) | 图像输入大小 |
|---|---|---|---|---|
squeezenet |
18 | 5.2 MB |
1.24 | 227年- 227年 |
googlenet |
22 | 27 MB |
7 | 224乘224 |
接收v3 |
48 | 89MB |
23.9 | 299乘299 |
densenet201 |
201 | 77MB |
20 | 224乘224 |
mobilenetv2 |
53 | 13MB |
3.5 | 224乘224 |
resnet18 |
18 | 44 MB |
11.7 | 224乘224 |
resnet50 |
50 | 96MB |
25.6 | 224乘224 |
resnet101 |
101 | 167 MB |
44.6 | 224乘224 |
xception |
71 | 85 MB |
22.9 | 299乘299 |
接收resnetv2 |
164 | 209MB |
55.9 | 299乘299 |
沙夫林 |
50 | 5.4 MB | 1.4 | 224乘224 |
nasnetmobile |
* | 20MB | 5.3 | 224乘224 |
纳斯内特拉格 |
* | 332 MB | 88.9 | 331乘331 |
darknet19 |
19 | 78MB | 20.8 | 256年- 256年 |
darknet53 |
53 | 155 MB | 41.6 | 256年- 256年 |
效率ETB0 |
82 | 20MB | 5.3 | 224乘224 |
阿列克斯内特 |
8. | 227MB |
61.0 | 227年- 227年 |
vgg16 |
16 | 515 MB |
138 | 224乘224 |
vgg19 |
19 | 535 MB |
144 | 224乘224 |
*NASNet移动网络和NASNet大型网络不包含模块的线性序列。
古格内特在365号地点接受训练
标准的GoogLeNet网络是在ImageNet数据集上训练的,但您也可以加载在Places365数据集上训练的网络[3][4]. 在地点365上训练的网络将图像分为365个不同的地点类别,如场地、公园、跑道和大厅。要加载在Places365数据集上训练过的预训练GoogLeNet网络,请使用googlenet(“重量”、“places365”).在执行迁移学习以执行新任务时,最常见的方法是使用在ImageNet上预先训练的网络。如果新任务类似于对场景进行分类,那么使用在Places365上训练的网络可以获得更高的准确率。
可视化预训练网络
您可以加载和可视化预先训练的网络使用深层网络设计师.
deepNetworkDesigner (squeezenet)
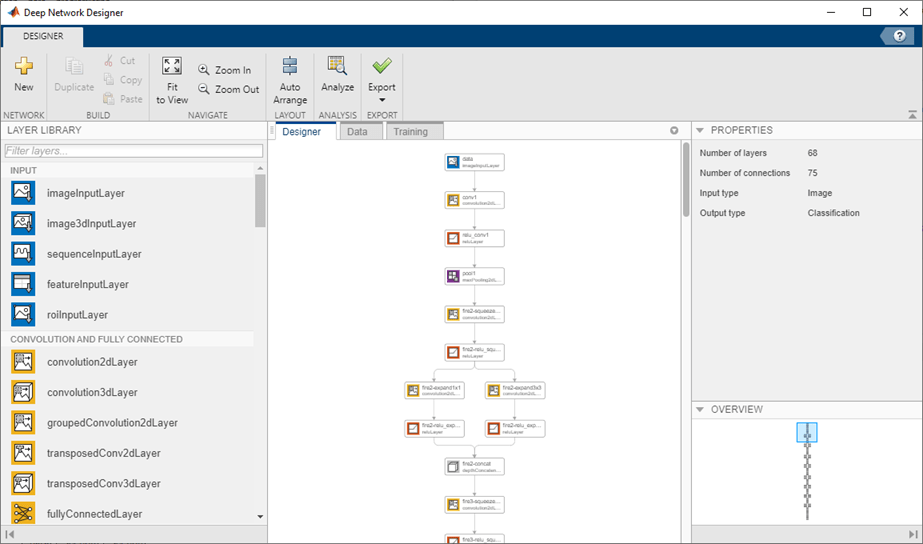
要查看和编辑图层属性,选择一个图层。单击图层名称旁边的帮助图标获取有关图层属性的信息。
探索其他预先训练的网络在深度网络设计师通过点击新.
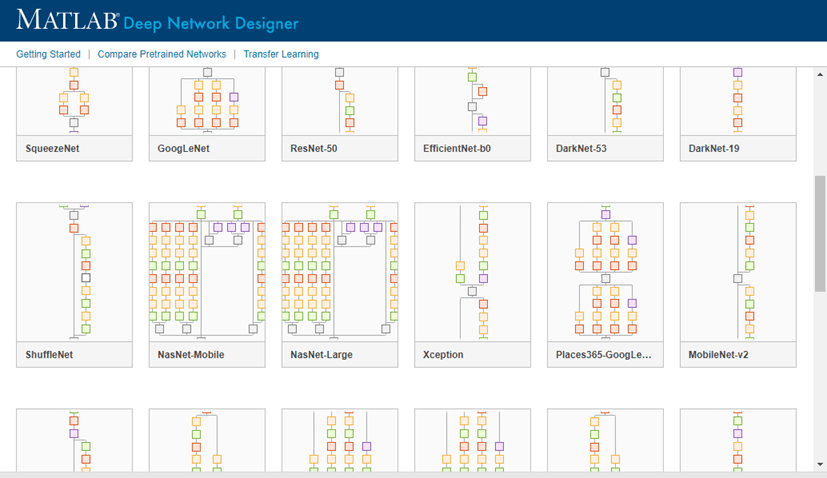
如果需要下载网络,请单击安装打开加载项资源管理器。
特征提取
特征提取是一种使用深度学习力量的简单而快速的方法,无需投入时间和精力来训练整个网络。因为它只需要对训练图像进行一次遍历,所以如果你没有GPU,它特别有用。你使用预先训练的网络提取学习的图像特征,然后使用这些特征来训练分类器,例如使用支持向量机金宝appfitcsvm(统计和机器学习工具箱).
当新数据集非常小时,尝试特征提取。由于您只需对提取的特征训练一个简单的分类器,因此训练速度很快。由于可供学习的数据很少,因此对网络更深层次的微调也不太可能提高准确性。
如果您的数据与原始数据非常相似,那么从网络深处提取的更具体的特征可能对新任务有用。
如果您的数据与原始数据非常不同,则在网络中提取的更深层次的特征可能对您的任务不太有用。尝试在从早期网络层提取的更一般的特征上训练最终分类器。如果新数据集很大,那么您也可以尝试从头开始训练网络。
resnet通常是很好的特性提取器。有关如何使用预训练网络进行特征提取的示例,请参见利用预训练网络提取图像特征.
转移学习
您可以通过使用预先训练过的网络作为起点,在新的数据集中训练网络,从而对网络中的更深层次进行微调。用迁移学习对一个网络进行微调通常比构建和训练一个新网络更快、更容易。网络已经学习了一组丰富的图像特性,但是当您对网络进行微调时,它可以学习特定于新数据集的特性。如果你有一个非常大的数据集,那么迁移学习可能不会比从头开始训练更快。
提示
对网络进行微调通常可以获得最高的精度。对于非常小的数据集(每个类少于20张图像),尝试特征提取。
微调网络比简单的特征提取更慢,需要更多的努力,但由于网络可以学习提取不同的特征集,最终的网络通常更精确。只要新数据集不是很小,微调通常比特征提取效果更好,因为这样网络就有数据可以从中学习新特征。有关如何执行迁移学习的示例,请参见使用深度网络设计师进行迁移学习和训练深度学习网络对新图像进行分类.
![]()
进出口网络
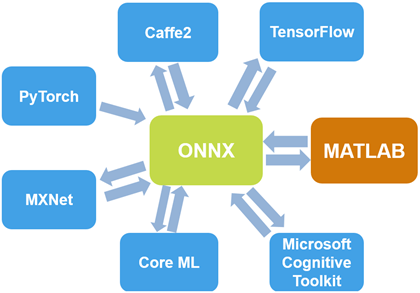
您可以从TensorFlow导入网络和网络架构®-Keras、Caffe和ONNX™(Open Neural Network Exchange)模型格式。您还可以将训练过的网络导出为ONNX模型格式。
从Keras进口
使用从TensorFlow Keras导入预训练网络进口卡拉斯网络. 您可以从相同的HDF5(.h5)文件或单独的HDF5和JSON(.JSON)文件导入网络和权重。有关详细信息,请参阅进口卡拉斯网络.
使用从TensorFlow Keras导入网络架构importKerasLayers. 可以导入网络体系结构(带权重或不带权重)。您可以从相同的HDF5(.h5)文件或单独的HDF5和JSON(.JSON)文件导入网络体系结构和权重。有关详细信息,请参阅importKerasLayers.
从咖啡进口
导入预先训练的网络从Caffe使用进口咖啡网函数。在咖啡模型动物园有许多预先训练过的网络可用[5]. 下载所需的.prototxt和.caffemodel文件和使用进口咖啡网将预训练网络导入MATLAB®. 有关详细信息,请参阅进口咖啡网.
您可以导入Caffe网络的网络架构。下载所需的.prototxt文件和使用进口咖啡机将网络层导入MATLAB。有关更多信息,请参见进口咖啡机.
出口和进口ONNX
通过使用ONNX作为中间格式,您可以与支持ONNX模型导出或导入的其他深度学习框架进行互操作,如TensorFlow、PyTorch、Caffe2、Microsoft金宝app®Cognitive Toolkit (CNTK)、Core ML和Apache MXNet™。
使用exportONNXNetwork作用然后,您可以将ONNX模型导入到支持ONXX模型导入的其他深度学习框架中。金宝app
使用ONNX导入预先训练好的网络进口网络并使用导入带权重或不带权重的网络体系结构importONNXLayers.
音频应用的预训练网络
通过使用深度学习工具箱和音频工具箱™,将预先训练好的网络用于音频和语音处理应用程序。
音频工具箱提供了经过预训练的VGISH和YAMNet网络。使用VGISH(音频工具箱)和yamnet(音频工具箱)功能直接与预先训练的网络交互。的classifySound(音频工具箱)函数对YAMNet执行所需的预处理和后处理,以便您可以将声音定位并分类到521个类别中的一个。控件可以探索YAMNet本体yamnetGraph(音频工具箱)函数。的vggishFeatures(音频工具箱)函数对VGGish进行必要的预处理和后处理,以便提取特征嵌入,输入到机器学习和深度学习系统。有关在音频应用程序中使用深度学习的更多信息,请参见音频应用的深度学习简介(音频工具箱).
使用VGGish和YAMNet执行迁移学习和特征提取。例如,请参见基于预训练音频网络的迁移学习(音频工具箱).
工具书类
[1]ImageNet.http://www.image-net.org
[2] Russakovsky,O.,Deng,J.,Su,H.,等,“ImageNet大规模视觉识别挑战。”国际计算机视觉杂志(IJCV). 第115卷,2015年第3期,第211-252页
[3] 周、博雷、阿迪蒂亚·科斯拉、阿加塔·拉佩德里扎、安东尼奥·托拉尔巴和奥德·奥利瓦。“位置:用于深入场景理解的图像数据库。”arXiv预印本arXiv: 1610.02055(2016).
[4]的地方.http://places2.csail.mit.edu/
[5]咖啡模型动物园.http://caffe.berkeleyvision.org/model_zoo.html
另请参阅
阿列克斯内特|darknet19|darknet53|深层网络设计师|densenet201|exportONNXNetwork|googlenet|进口咖啡机|进口咖啡网|importKerasLayers|进口卡拉斯网络|importONNXLayers|进口网络|接收resnetv2|接收v3|mobilenetv2|纳斯内特拉格|nasnetmobile|resnet101|resnet18|resnet50|沙夫林|squeezenet|vgg16|vgg19|xception
相关话题
你也可以从以下列表中选择一个网站:
