vggish
VAGATH神经网络
描述
例子
下载vggish network.
下载和解压缩音频工具箱™模型以实现vggnish。
类型vggish在命令窗口。如果未安装VAGAD的音频工具箱模型,则该函数提供了网络权重的位置的链接。要下载模型,请单击链接。将文件解压缩到MATLAB路径上的位置。
或者,执行这些命令下载并解压缩临时目录的VAGAD模型。
downloadfolder = fullfile(tempdir,'vggishdownload');loc = websave (downloadFolder,'https://ssd.mathworks.com/金宝appsupportfiles/audio/vggish.zip');VggishLocation = Tempdir;解压缩(Loc,VggishLocation)AddPath(FullFile(VggishLocation,'vgnish')))
通过键入检查安装是否成功vggish在命令窗口。如果安装了网络,则该函数返回a系列网络(深度学习工具箱)目的。
vggish
ans = SeriesNetwork with properties: Layers: [24×1 net.cnn.layer. layer] InputNames: {'InputBatch'} OutputNames: {'regressionoutput'}
负载净化的VAGATH网络
装载普罗瓦特普拉什卷积神经网络,检查图层和类。
采用vggish加载预磨损的vggnish网络。输出网是一个系列网络(深度学习工具箱)目的。
net = vgnish.
[24×1 nnet.cnn.layer.Layer] InputNames: {'InputBatch'} OutputNames: {'regressionoutput'}
使用该网络架构查看网络架构层数财产。网络有24层。有九层具有可学习的重量,其中六个是卷积层,三个是完全连接的层。
网。层数
ans = 24×1 Layer array with layers:1“InputBatch”图像输入96×64×1图片2 conv1卷积64 3×3×1旋转步[1]和填充“相同”3“relu”relu relu 4“pool1”马克斯池2×2马克斯池步(2 - 2)和填充“相同”5 conv2卷积128 3×3×64旋转步[1]和填充“相同”6“relu2”relu relu 7 pool2马克斯池2×2马克斯池步(2 - 2)和填充“相同”256“conv3_1”卷积3×3×128旋转步[1]和填充“相同”9“relu3_1”ReLU ReLU conv3_2的卷积256 3×3×256旋转步[1]和填充“相同”11的relu3_2 ReLU ReLU 12“pool3”马克斯池2×2马克斯池步(2 - 2)和填充“相同”13conv4_1卷积512 3×3×256旋转步[1]和填充“相同”14的relu4_1 ReLU ReLU 15 conv4_2卷积512 3×3×512旋转步[1]和填充“相同”16的relu4_2 ReLU ReLU 17“pool4”马克斯池2×2马克斯池步(2 - 2)和填充“相同”18 fc1_1完全连接4096完全连接层19'relu5_1' ReLU ReLU 20 'fc1_2' Fully Connected 4096 Fully Connected layer 21 'relu5_2' ReLU ReLU 22 'fc2' Fully Connected 128 Fully Connected layer 23 ' embedingbatch ' ReLU ReLU 24 'regressionoutput' Regression Output ' Regression Output均方误差
采用analyzeNetwork(深度学习工具箱)可视化地探索网络。
分析(净)

使用VAGATH提取功能
VAggish网络要求您通过将网络培训的采样率转换为采样率,然后提取日志MEL谱图来预处理和提取来自音频信号的功能。此示例通过所需的预处理和特征提取来匹配用于培训VAGATH的预处理和功能提取。这vggishfeatures.函数为您执行这些步骤。
读入音频信号进行分类。重新采样音频信号到16千赫,然后将其转换为单一精度。
[AudioIn,FS0] = audioread( 'Ambiance-16-44p1-mono-12secs.wav');fs = 16e3;AudioIn =重组(AudioIn,FS,FS0);AudioIn =单(AudioIn);
'Ambiance-16-44p1-mono-12secs.wav');fs = 16e3;AudioIn =重组(AudioIn,FS,FS0);AudioIn =单(AudioIn);
定义MEL谱图参数,然后使用该方法提取特征MELSPectRoge.功能。
FFTLength = 512;numbands = 64;频率频率= [125 7500];windowlength = 0.025 * fs;overtaplenththength = 0.015 * fs;MELSECT = MELSPETROGROG(AudioIn,FS,......“窗口”,HANN(WindowLength,'定期'),......'overlaplencth',overtaplength,......'fftlength',fftlength,......“FrequencyRange”frequencyRange,......“NumBands”numBands,......“FilterBankNormalization”那'没有任何'那......'风向正常化',错误的,......“SpectrumType”那“级”那......“FilterBankDesignDomain”那“扭曲”);
将MEL谱图转换为日志比例。
melSpect = log(melSpect + single(0.001));
重新定位mel谱图,使时间以行的形式沿第一个维度排列。
melsclet = melspect。';[numstftwindows,numbands] =大小(melscly)
numstftwindows = 1222
numbands = 64.
将声谱图分成长度为96、重叠48的帧。沿着第四维度放置框架。
FrameWindowLength = 96;Frameoverlaplength = 48;HopLength = FrameWindowLength - FrameOverlaplength;numhops =楼层((numstftwindows - framewindowlength)/ hoplength)+ 1;框架= zeros(FrameWindowLength,NumBand,1,NumHops,“喜欢”, melSpect);为了hop = 1:numHops range = 1 + hopLength*(hop-1):hopLength*(hop -1) + frameWindowLength;跳帧(::1)= melSpect(范围:);结尾
创建VGGish网络。
net = vgnish;
称呼预测从频谱图中提取特征嵌入物。该特征嵌入物作为a返回numframes.-By-128矩阵,在哪里numframes.是单独的谱图的数量,128是每个特征向量中的元素的数量。
特征=预测(网络,框架);[numframes,numfeatures] =大小(特征)
numframes = 24.
numfeatures = 128
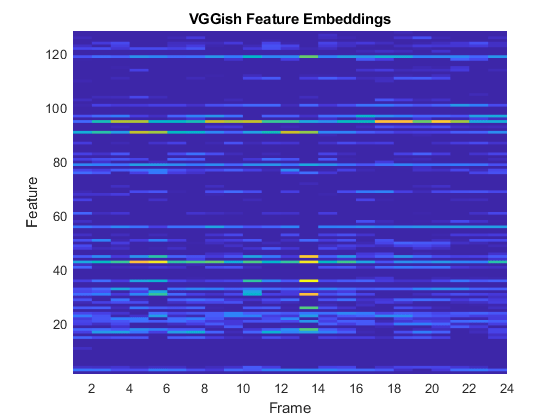
比较MEL谱图的可视化和VAGADISH功能嵌入。
melSpectrogram (audioIn fs,......“窗口”,HANN(WindowLength,'定期'),......'overlaplencth',overtaplength,......'fftlength',fftlength,......“FrequencyRange”frequencyRange,......“NumBands”numBands,......“FilterBankNormalization”那'没有任何'那......'风向正常化',错误的,......“SpectrumType”那“级”那......“FilterBankDesignDomain”那“扭曲”);

冲浪(特性,'Edgecolor'那'没有任何')视图([90,-90])轴([1 numFeatures 1 numFrames]) xlabel('特征')ylabel(“帧”)标题('VAGATH功能嵌入')
使用VAGATH转移学习
在此示例中,您将Legress在VAggish回归模型中传输到音频分类任务。
下载并解压环境声音分类数据集。该数据集由标记为10个不同音频声音类(ESC-10)之一的录音组成。
url ='http://ssd.mathwands.com/金宝appsupportfiles/audio/esc-10.zip';downloadfolder = fullfile(tempdir,'esc-10');datasetlocation = tempdir;如果〜存在(fullfile(tempdir,'esc-10'),“dir”)loc = websave(downloadFolder,URL);解压缩(LOC,FullFile(Tempdir,'esc-10')))结尾
创建一个audiodatastore.对象来管理数据,并将其分解为训练集和验证集。称呼counteanceLabel.显示声音类的分布和独特标签的数量。
广告= audiodataStore(DownloadFolder,'insertumbfolders',真的,'labelsource'那'foldernames');labelTable = countEachLabel(广告)
Labeltable =.10×2表标签数_______________ _____电锯40钟声40 crackling_fire 40 crying_baby 40狗40狗40 rove 40 rooster 38 sea_waves 40打喷嚏40
确定类的总数。
numclasses = size(labeltable,1);
称呼spliteachlabel.将数据拆分为培训和验证集。检查培训和验证集中标签的分发。
[adstrain,ADSValidation] = SpliteachLabel(广告,0.8);CountAckeLabel(adstrain)
ans =10×2表标签数______________ _____链锯32 clock_tick 32 crackling_fire 32啼哭的婴儿32狗32直升机32雨32公鸡30海浪32打喷嚏32
CountAckeLabel(ADSValidation)
ans =10×2表标签数______________ _____电锯8个钟声_tick 8 crackling_fire 8 crying_baby 8狗8直升机8 roving 8公鸡8 sea_waves 8打喷嚏8
VAggish网络预计音频将被预处理到日志MEL谱图中。支持功能金宝appvggishpreprocess.需要一个audiodatastore.对象和日志MEL谱图之间的重叠百分比作为输入,并返回适合作为VAGANT网络的输入的预测器和响应的矩阵。
重叠普遍= 75;[训练训练,trainlabels] = Vggishpreprocess(adstrain,重叠植物);[验证特征,验证标签,segmentsperfile] = VggishPrepess(ADSValidation,Overlappercentage);
75;[训练训练,trainlabels] = Vggishpreprocess(adstrain,重叠植物);[验证特征,验证标签,segmentsperfile] = VggishPrepess(ADSValidation,Overlappercentage);
加载VAGATH模型并将其转换为分层图(深度学习工具箱)目的。
net = vgnish;LGRAPRE = LayerGraph(Net.Layers);
采用removeLayers(深度学习工具箱)从图中删除最终回归输出层。删除回归层后,图形的新最后一层是名为的Relu层'embeddingbatch'。
lgraph = removeLayers (lgraph,'回归输出');Layers(结束)
ANS =具有属性的抵押者:名称:'EmbeddingBatch'
采用addlayers.(深度学习工具箱)添加一个全康统计层(深度学习工具箱), 一种softmaxLayer(深度学习工具箱)和A.分类层(深度学习工具箱)到图表。
Lgraph = AddLayers(Lapraph,全连接层(NumClasses,'名称'那'fcfinal'));Lgraph = Addlayers(Lography(SoftMaxLayer)('名称'那“softmax”));lgraph = addLayers (lgraph classificationLayer ('名称'那'课堂'));
采用ConnectLayers.(深度学习工具箱)将全连接层、softmax层和分类层附加到层图中。
Lgraph = ConnectLayers(LAPHAGE,'embeddingbatch'那'fcfinal');Lgraph = ConnectLayers(LAPHAGE,'fcfinal'那“softmax”);Lgraph = ConnectLayers(LAPHAGE,“softmax”那'课堂');
定义培训选项,使用培训选项(深度学习工具箱)。
minibatchsize = 128;选项=培训选项(“亚当”那......'maxepochs'5,......“MiniBatchSize”miniBatchSize,......“洗牌”那'每个时代'那......'vightationdata',{ValidationFeatures,ValidationLabels},......'验证职业',50,......“LearnRateSchedule”那'分段'那......'学习ropfactor',0.5,......'学习ropperiod',2);
培训网络,使用Trainnetwork.(深度学习工具箱)。
[trainedNet, netInfo] = trainNetwork(trainFeatures,trainLabels,lgraph,options);
单GPU训练。|======================================================================================================================| | 时代| |迭代时间| Mini-batch | |验证Mini-batch | |验证基地学习 | | | | ( hh: mm: ss) | | |精度精度损失| | |率损失|======================================================================================================================| | 1 | 1 |就是| | 10.94% 26.03% | 2.2253 | 2.0317 | 0.0010 | | 2 | 50 | 00:00:05 | | 93.75% 83.75% | 0.1884 | 0.7001 | 0.0010 | | 3 | 100 | 00:00:10 | | 96.88% 80.07% | 0.1150 | 0.7838 | 0.0005 | | 150 | | 00:00:15 |92.97% | 81.99% | 0.1656 | 0.7612 | 0.0005 | | 200 | | 00:00:20 | | 92.19% 79.04% | 0.1738 | 0.8192 | 0.0003 | | 210 | | 00:00:21 95.31% | | | 0.1389 | 0.8581 | 0.0003 80.15% | |======================================================================================================================|
每个音频文件都分成多个段以进入VAGGASH网络。使用大多数规则决策结合验证集中的每个文件的预测。
validationPredictions =分类(trainedNet validationFeatures);idx = 1;validationPredictionsPerFile =分类;为了ii = 1:numel(adsvalidate . files) validationPredictionsPerFile(ii,1) = mode(validationPredictions(idx:idx+segmentsPerFile(ii)-1));idx = idx + segmentsPerFile(ii);结尾
采用困惑的园林(深度学习工具箱)评估网络对验证集的性能。
数字(“单位”那'标准化'那“位置”,[0.2 0.2 0.5 0.5]);厘米= confusionchart (adsValidation.Labels validationPredictionsPerFile);厘米。标题= sprintf ('验证数据的混淆矩阵\ naccuracy =%0.2f %%',意味着(validationPredictionsPerFile = = adsValidation.Labels) * 100);厘米。ColumnSummary ='列 - 归一化';cm.rowsummary =“row-normalized”;
![]()
金宝app支持功能
功能[预测器,响应,segmentsperfile] = vggishpreprocess(广告,重叠)%此函数仅供示例使用,可以更改或删除未来释放的%。%创建过滤器银行FFTLength = 512;numbands = 64;fs0 = 16e3;FilterBank = DesignAudiTionFilterBank(FS0,......“FrequencyScale”那“梅尔”那......'fftlength',fftlength,......“FrequencyRange”,[125 7500],......“NumBands”numBands,......“归一化”那'没有任何'那......“FilterBankDesignDomain”那“扭曲”);%定义STFT参数窗口长度= 0.025 * fs0;hopLength = 0.01 * fs0;赢得=损害(windowLength,'定期');%定义频谱图分段参数segmentDuration = 0.96;%秒sementrate = 100;%赫兹segmentLength = segmentduration * segmentRate;%每种听觉谱图的频谱数量semmenthopduration =(100-重叠)* semmentduration / 100;%听觉频谱图之间的持续时间(s)segshoplence = round(段Hopduration * sementrate);听觉谱图之间的频谱数量在%预先采用的预测器和响应的细胞阵列numfiles = numel(ads.files);predictor = cell(numfiles,1);响应=预测因子;segmentsperfile = zeros(numfiles,1);提取每个文件的预测器和响应为了II = 1:NUMFiles [AudioIN,INFO] =读取(广告);x =单(重新取样(AudioIn,FS0,Info.Samplerge));y = stft(x,......“窗口”,赢了,......'overlaplencth',windowlength-hoplength,......'fftlength',fftlength,......“FrequencyRange”那'片面');y = abs(y);logmelspectroge = log(filterbank * y +单个(0.01))';%段日志 - MEL谱图numhops =楼层((大小(y,2)-segent长度)/段Hoploplength)+ 1;segmentedlogmelspectroge = zeros(secmentlength,numband,1,numhops);为了segmentedLogMelSpectrogram(:,:,1,hop) = logMelSpectrogram(1+segmentHopLength*(hop-1):segmentLength+segmentHopLength*(hop-1),:);结尾预测{2}= segmentedLogMelSpectrogram;响应{2}= repelem (info.Label numHops);segmentsPerFile (ii) = numHops;结尾%连接预测器和响应到数组预测预测=猫(4日{:});响应=猫(2、响应{:});结尾
输出参数
参考文献
[1] Gemmeke,Jort F.,Daniel P. W. Ellis,Dylan Freedman,Aren Jansen,Wade Lawrence,R. Channing Moore,Manoj Plakal和Marvin Ritter。“音频集:音频事件的本体和人为标签数据集。”在2017 IEEE声学,语音和信号处理国际会议(ICASSP)776-80。新奥尔良,洛杉矶:IEEE。https://doi.org/10.1109/ICASSP.2017.7952261。
Hershey, Shawn, Sourish Chaudhuri, Daniel P. W. Ellis, Jort F. Gemmeke, Aren Jansen, R. Channing Moore, Manoj Plakal, et al. 2017。CNN大规模音频分类架构在2017 IEEE声学,语音和信号处理国际会议(ICASSP),131-35。新奥尔良,洛杉矶:IEEE。https://doi.org/10.1109/ICASSP.2017.7952132。
扩展功能
您还可以从以下列表中选择一个网站: