trainingOptions
深度学习神经网络训练选项
描述
选项= trainingOptions (solverName)solverName.要培训网络,请使用培训选项作为输入参数trainNetwork功能。
选项= trainingOptions (solverName那名称,值)
例子
指定培训选项
创建一组选项来训练网络使用随机梯度下降与动量。每5个周期将学习率降低0.2倍。将训练的最大纪元数设置为20,并在每次迭代中使用包含64个观察值的小批处理。打开训练进度图。
选择= trainingOptions (“个”那...“LearnRateSchedule”那“分段”那...“LearnRateDropFactor”, 0.2,...“LearnRateDropPeriod”5,...“MaxEpochs”, 20岁,...“MiniBatchSize”, 64,...“阴谋”那“训练进步”)
选择= TrainingOptionsSGDM属性:动力:0.9000 InitialLearnRate: 0.0100 LearnRateSchedule:“分段”LearnRateDropFactor: 0.2000 LearnRateDropPeriod: 5 L2Regularization: 1.0000 e-04 GradientThresholdMethod:“l2norm”GradientThreshold:正MaxEpochs: 20 MiniBatchSize: 64详细:1 VerboseFrequency: 50 ValidationData:[] ValidationFrequency: 50 ValidationPatience:正洗牌:“一旦”CheckpointPath:“ExecutionEnvironment:‘汽车’WorkerLoad: [] OutputFcn:[]阴谋:“训练进步”SequenceLength:“最长”SequencePaddingValue: 0 SequencePaddingDirection:“对”DispatchInBackground: 0 ResetInputNormalization: 1
监控深度学习训练进展
当您培训深度学习网络时,监控培训进度通常有用。通过在培训期间绘制各种指标,您可以了解培训是如何进展的。例如,您可以确定网络精度是否改进的速度,以及网络是否开始过度使用培训数据。
当你指定“训练进步”随着“阴谋”价值trainingOptions开始网络培训,trainNetwork创建一个数字并在每次迭代时显示培训指标。每次迭代都是对梯度的估计和网络参数的更新。中指定验证数据trainingOptions,图中显示每次验证的度量trainNetwork验证网络。图中描绘了如下内容:
训练精度-每个小批量的分类精度。
平滑的训练精度—平滑训练精度,将平滑算法应用到训练精度上获得。与不平滑的精度相比,它的噪声更小,因此更容易发现趋势。
验证准确性-整个验证集的分类精度(指定使用
trainingOptions).培训损失那平滑培训损失,确认损失-每个小批量的损失,它的平滑版本,和验证集的损失,分别。如果你的网络的最后一层是
classificationLayer,则损失函数为交叉熵损失。有关用于分类和回归问题的损失函数的更多信息,请参见输出层.
对于回归网络,图形绘制了根均方误差(RMSE)而不是精度。
这个图形标记了每一次训练时代使用阴影背景。epoch是完整的通过整个数据集。
在培训期间,您可以通过单击右上角的停止按钮来停止培训并返回网络的当前状态。例如,当网络的准确性到达高原时,您可能希望停止培训,并且很明显,准确性不再改善。单击“停止”按钮后,可能需要一段时间才能完成培训。一旦培训完成,trainNetwork返回训练过的网络。
培训结束时,查看结果显示最终验证的准确性和培训完成的原因。最后的验证度量被标记最后的情节。如果您的网络包含批处理规范化层,那么最终的验证度量通常与训练期间评估的验证度量不同。这是因为最终网络中的批处理归一化层执行的操作与训练时不同。
在右侧可查看培训时间和设置信息。要了解更多培训选项,请参见卷积神经网络参数的建立与训练.
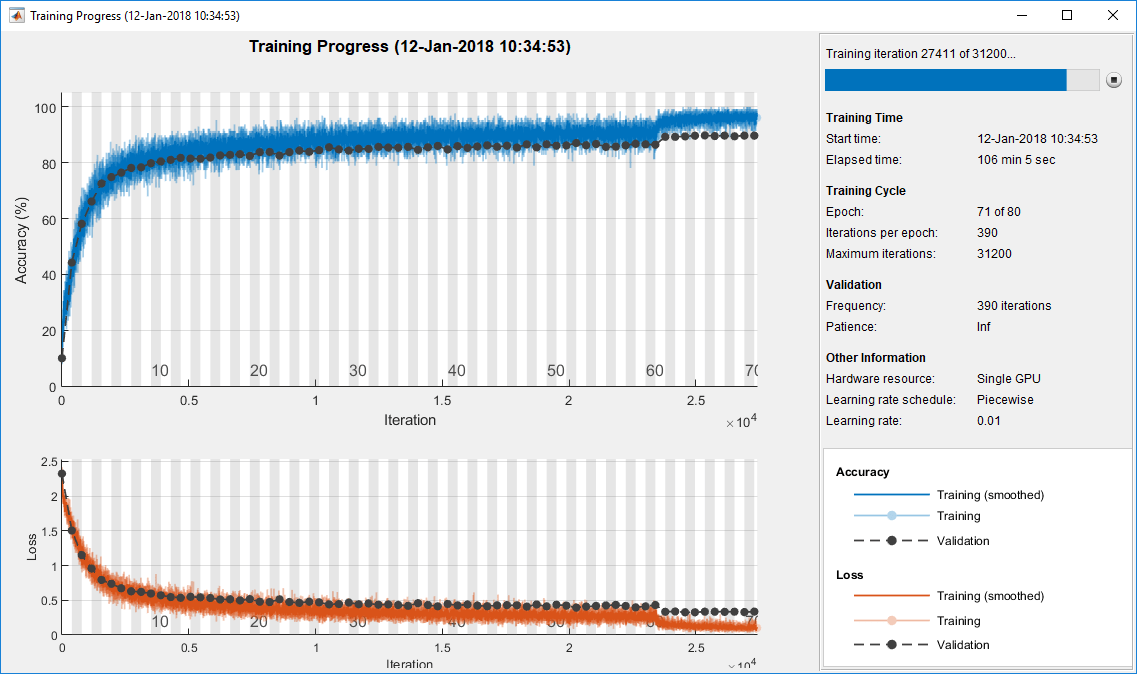
在培训过程中策划培训进度
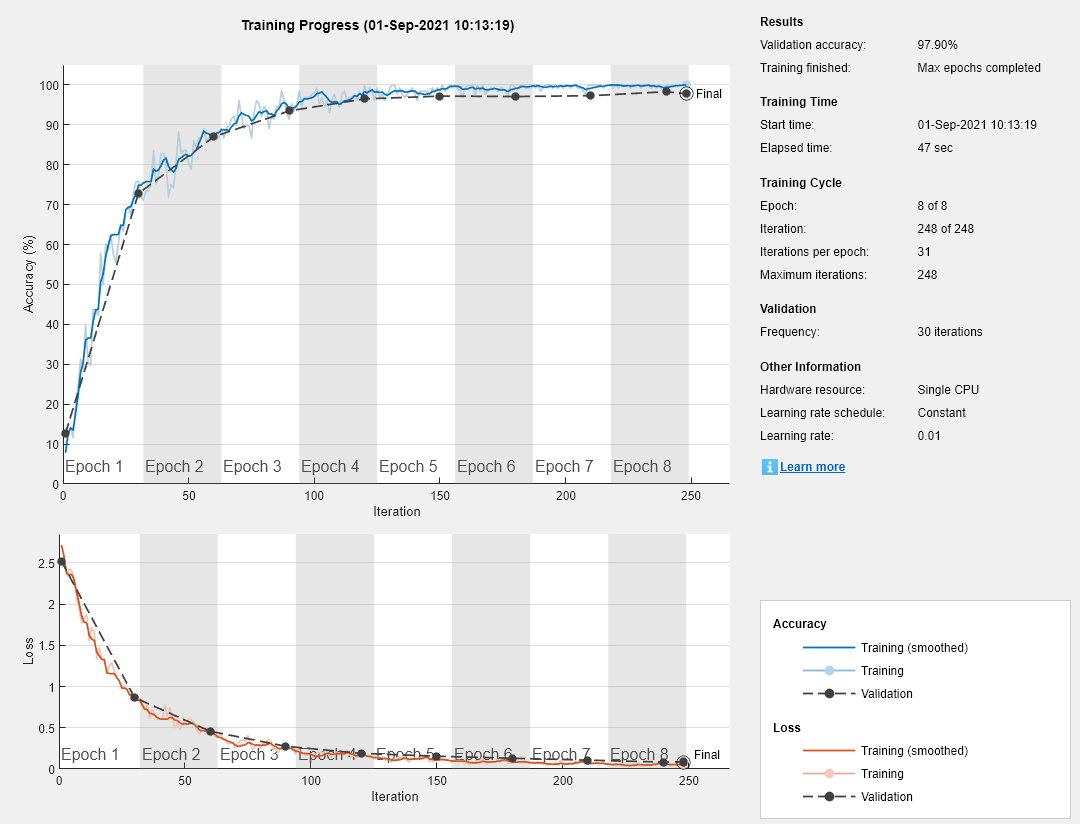
训练网络,并在训练过程中绘制训练进度图。
加载训练数据,其中包含5000个数字图像。预留1000个图像用于网络验证。
[XTrain, YTrain] = digitTrain4DArrayData;idx = randperm(大小(XTrain, 4), 1000);XValidation = XTrain (:,:,:, idx);XTrain (::,:, idx) = [];YValidation = YTrain (idx);YTrain (idx) = [];
构造一个网络来对数字图像数据进行分类。
layers = [imageInputLayer([28 28 1])]“填充”那“相同”maxPooling2dLayer(2,“步”2) convolution2dLayer(16日“填充”那“相同”maxPooling2dLayer(2,“步”32岁的,2)convolution2dLayer (3“填充”那“相同”) batchNormalizationLayer relullayer fulllyconnectedlayer (10) softmaxLayer classificationLayer];
指定网络训练选项。要在训练期间定期验证网络,请指定验证数据。选择“ValidationFrequency”值,以便每个epoch大约验证一次网络。在培训过程中规划培训进度,指定“训练进步”随着“阴谋”价值。
选择= trainingOptions (“个”那...“MaxEpochs”8...“ValidationData”{XValidation, YValidation},...“ValidationFrequency”30岁的...“详细”假的,...“阴谋”那“训练进步”);
培训网络。
网= trainNetwork (XTrain、YTrain层,选择);
输入参数
solverName-训练网络求解器
“个”|“rmsprop”|“亚当”
训练网络求解器,指定为下列任一种:
“个”-使用随机梯度下降与动量(SGDM)优化器。可以使用。指定动量值“动量”名称-值对的论点。“rmsprop”—使用RMSProp优化器。您可以指定衰减速率的平方梯度移动平均使用'squaredgradientdecayfactor'名称-值对的论点。“亚当”-使用亚当优化器。可以指定梯度和平方梯度移动平均的衰减率'gradientdecayfactor'和'squaredgradientdecayfactor'名称-值对参数。
有关不同求解器的更多信息,请参见随机梯度下降法.
名称-值对的观点
指定可选的逗号分离对名称,值参数。的名字参数名和价值为对应值。的名字必须出现在引号内。可以以任意顺序指定多个名称和值对参数Name1, Value1,…,的家.
“InitialLearnRate”,0.03,“L2Regularization”,0.0005,“LearnRateSchedule”、“分段”指定初始学习率为0.03L.2正则化因子为0.0005,并指示软件通过与某一因子相乘来降低每一给定纪元数的学习率。
“阴谋”-在网络训练期间显示的图
“没有”(默认)|“训练进步”
在网络训练期间要显示的图,指定为逗号分隔对,由“阴谋”和以下之一:
“没有”-在训练期间不要显示情节。“训练进步”-规划培训进度。该图显示了小批损失和准确性,验证损失和准确性,以及培训进展的附加信息。这个情节有一个停止按钮 在右上角。点击按钮停止训练,返回网络当前状态。有关培训进度图的更多信息,请参见监控深度学习训练进展.
在右上角。点击按钮停止训练,返回网络当前状态。有关培训进度图的更多信息,请参见监控深度学习训练进展.
例子:“阴谋”,“训练进步”
“详细”-显示培训进度信息的指标
1(真正的)(默认)|0.(假)
指示符用于在命令窗口中显示训练进度信息,指定为逗号分隔的对,由“详细”,要么1(真正的)或0.(假).
verbose输出显示如下信息:
网络的分类
| 场 | 描述 |
|---|---|
时代 |
时代的数字。epoch对应于数据的一次完整传递。 |
迭代 |
迭代数。迭代对应于小批处理。 |
时间 |
时间以小时、分钟和秒为单位流逝。 |
Mini-batch准确性 |
在小批量上的分类精度。 |
验证准确性 |
对验证数据的分类精度。如果不指定验证数据,则该函数不会显示该字段。 |
Mini-batch损失 |
迷你批处理上的损失。如果输出层是ClassificationOutputLayer对象,则该损失为类间互斥的多类分类问题的交叉熵损失。 |
确认损失 |
验证数据的丢失。如果输出层是ClassificationOutputLayer对象,则该损失为类间互斥的多类分类问题的交叉熵损失。如果不指定验证数据,则该函数不会显示该字段。 |
基础学习速率 |
基础学习率。该软件将该值乘以图层的学习速率因子。 |
回归网络
| 场 | 描述 |
|---|---|
时代 |
时代的数字。epoch对应于数据的一次完整传递。 |
迭代 |
迭代数。迭代对应于小批处理。 |
时间 |
时间以小时、分钟和秒为单位流逝。 |
Mini-batch RMSE |
迷你批处理上的根均匀误差(RMSE)。 |
验证RMSE. |
验证数据的RMSE。如果不指定验证数据,则软件不会显示此字段。 |
Mini-batch损失 |
迷你批处理上的损失。如果输出层是RegressionOutputLayer对象,则损失为一半均方误差。 |
确认损失 |
验证数据的丢失。如果输出层是RegressionOutputLayer对象,则损失为一半均方误差。如果不指定验证数据,则软件不会显示此字段。 |
基础学习速率 |
基础学习率。该软件将该值乘以图层的学习速率因子。 |
要指定验证数据,请使用“ValidationData”名称-值对。
例子:“详细”,假的
“VerboseFrequency”-详细打印频率
50(默认)|正整数
详细打印的频率,它是在打印到命令窗口之间的迭代次数,指定为由逗号分隔的对组成“VerboseFrequency”一个正整数。此选项只有效果“详细”值=真正的.
如果你在训练期间验证网络,那么trainNetwork每次验证发生时也打印到命令窗口。
例子:“VerboseFrequency”,100年
输出参数
提示
对于大多数深度学习任务,您可以使用预先训练的网络,并使其适应您自己的数据。有关如何使用迁移学习来重新训练卷积神经网络来对一组新图像进行分类的示例,请参见训练深度学习网络对新图像进行分类.或者,您可以使用从头开始创建和培训网络
layerGraph的对象trainNetwork和trainingOptions功能。如果
trainingOptions函数不提供任务所需的训练选项,则可以使用自动区分创建自定义训练循环。想要了解更多,请看为自定义训练循环定义深度学习网络.
算法
兼容性的考虑
工具书类
[1]毕晓普模式识别和机器学习.施普林格,纽约,纽约,2006。
K. P.墨菲机器学习:概率视角.麻省理工学院出版社,剑桥,马萨诸塞州,2012年。
帕斯卡努,R., T. Mikolov, Y. Bengio。“关于训练递归神经网络的困难”。第30届国际机器学习会议论文集.[j] .岩石力学与工程学报,2013,34(3):341 - 346。
[4]金玛,迪德里克和吉米·巴。"亚当:随机优化的方法"arXiv预印本arXiv: 1412.6980(2014).
也可以看看
你也可以从以下列表中选择一个网站:
