Convolution2Dlayer.
二维卷积层
描述
二维卷积层将滑动卷积滤波器应用于输入。该图层通过垂直和水平沿输入沿输入和计算重量和输入的点乘积来使滤波器旋转输入,然后添加偏置术语。
属性
例子
更多关于
卷积的层
二维卷积层将滑动卷积滤波器应用于输入。该层通过沿输入垂直和水平移动滤波器,计算权重和输入的点积,然后添加偏差项,对输入进行卷积。
卷积层由各种组件组成。[1]
卷积层由连接到输入图像的子区域或前一层的输出的神经元组成。该图层在扫描通过图像时学习这些区域本地化的功能。使用中创建图层时Convolution2Dlayer.函数中指定这些区域的大小filterSize输入参数。
对于每个区域,trainNetwork函数计算权值与输入的点积,然后加上偏差项。应用于图像中某一区域的一组权值称为过滤器.滤波器沿输入图像垂直和水平移动,对每个区域重复相同的计算。换句话说,过滤器对输入进行卷积。
这张图片显示了一个3 × 3的过滤器扫描输入。下面的映射表示输入,上面的映射表示输出。
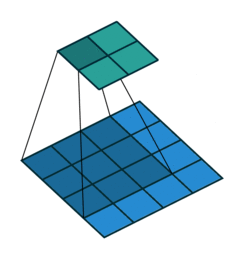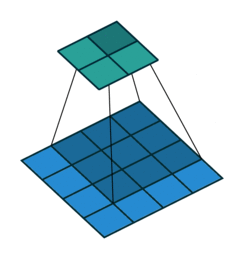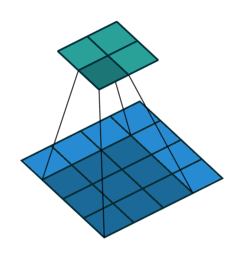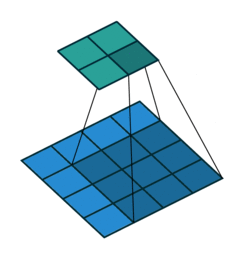
滤波器移动的步长称为步.属性可以指定步长步名称-值对的论点。神经元连接的局部区域可能会重叠,这取决于filterSize和“步”值。
这张图片显示了一个3 × 3的过滤器以2的步幅扫描输入。下面的映射表示输入,上面的映射表示输出。
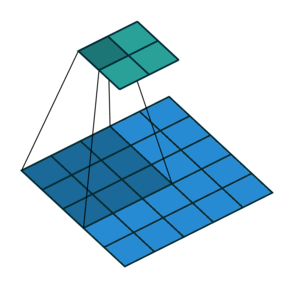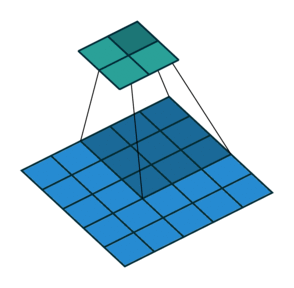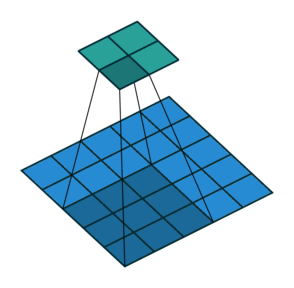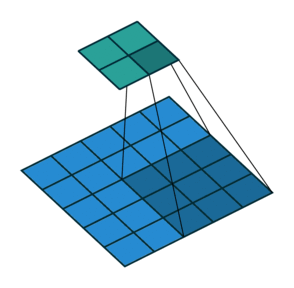
过滤器中的权重数为h*w*c,在那里h是高度,和w滤镜的宽度分别是和吗c为输入中的通道数。例如,如果输入是彩色图像,则颜色通道数为3。滤波器的数量决定了卷积层输出的通道数量。属性指定筛选器的数目numFilters参数与Convolution2Dlayer.函数。
扩展卷积是一种卷积,在这种卷积中,滤波器通过插入元素之间的空格展开。属性指定膨胀系数“DilationFactor”财产。
使用扩展卷积来增加层的接受域(层可以看到的输入区域),而不增加参数或计算的数量。
通过在每个滤波器元件之间插入零来扩展滤波器。扩张因子确定用于采样输入的步骤或等效地对滤波器的上采样因子进行采样。它对应于有效的滤波器大小(过滤器的大小- 1) *膨胀系数+ 1。例如,一个带有膨胀系数的3 × 3滤波器(2 - 2)相当于一个元素之间为零的5 × 5滤波器。
这张图片显示了一个3 × 3的滤光片,放大了2倍扫描通过输入。下面的映射表示输入,上面的映射表示输出。

当一个滤波器沿着输入移动时,它使用相同的权值集和相同的卷积偏差,形成一个特征映射.每个特征图是使用不同的重量和不同偏差集的卷积的结果。因此,特征映射的数量等于过滤器的数量。卷积层中的参数总数是((h*w*c+ 1)*数量的过滤器),其中1为偏差。
控件也可以对输入图像的边框垂直或水平应用填充“填充”名称-值对的论点。填充是附加到输入边界以增加其大小的值。通过调整填充,你可以控制图层的输出大小。
这张图片显示了一个3 × 3的过滤器扫描输入,填充大小为1。下面的映射表示输入,上面的映射表示输出。

卷积层的输出高度和宽度为(输入的大小- ((过滤器的大小- 1) *膨胀系数+ 1 + 2*填充)/步+ 1。此值必须是要完全覆盖的整数的整数。如果这些选项的组合不会引导要完全覆盖的图像,则默认情况下的软件忽略了卷积中右侧和底部边缘的剩余部分。
输出高度和宽度的乘积给出了特征图中神经元的总数地图大小.卷积层中的神经元总数(输出大小)为地图大小*数量的过滤器.
例如,假设输入图像是一个32 × 32 × 3的彩色图像。对于一个包含8个过滤器,过滤器大小为5 × 5的卷积层,每个过滤器的权重数为5 * 5 * 3 = 75,层中的参数总数为(75 + 1)* 8 = 608。如果每个方向的步幅为2,并指定填充大小为2,则每个feature map为16 × 16。这是因为(32 - 5 + 2 * 2)/2 + 1 = 16.5,并且一些最外层的填充到右边和底部的图像被丢弃。最后,层中神经元的总数为16 * 16 * 8 = 2048。
通常,这些神经元的结果通过某种形式的非线性,例如整流的线性单元(Relu)。
在定义卷积层时,您可以使用名称值对参数调整图层的学习速率和正常化选项。如果您选择不指定这些选项,那么trainNetwork使用定义的全局培训选项培训选项函数。有关全局和层训练选项的详细信息,请参见卷积神经网络参数的建立与训练.
卷积神经网络可以由一个或多个卷积层组成。卷积层的数量取决于数据的数量和复杂性。
兼容性考虑因素
参考文献
莱昆,Y. B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard,和L. D. jackkel。“基于反向传播网络的手写数字识别”在神经信息处理系统研究进展2(杜雷兹基编)。旧金山:摩根·考夫曼,1990年。
勒昆(LeCun)、L.博图(L. Bottou)、Y.本吉奥(Y. Bengio)和P. Haffner。“梯度学习在文档识别中的应用”。IEEE论文集.1998年第86卷第11期,第2278-2324页。
K. P.墨菲机器学习:概率视角.马萨诸塞州剑桥:麻省理工学院出版社,2012。
[4] Glorot,Xavier和Yoshua Bengio。“了解训练深馈神经网络的难度。”在第十三届国际人工智能和统计会议论文集, 249 - 356。撒丁岛,意大利:AISTATS, 2010。
何开明,张翔宇,任少青,孙健深入研究整流器:在图像网分类上超越人类水平的表现。在2015 IEEE计算机视觉国际会议论文集, 1026 - 1034。计算机视觉,2015。
扩展功能
另请参阅
BatchnormalizationLayer.|深层网络设计师|fullyConnectedLayer|groupedConvolution2dLayer|maxPooling2dLayer|reluLayer|trainNetwork
您还可以从以下列表中选择一个网站:
