trainNetwork
火车神经网络深入学习
语法
描述
对于分类和回归任务,您可以使用trainNetwork为了培训用于图像数据的卷积神经网络(ConvNet,CNN),诸如序列数据的长短期存储器(LSTM)或门控复发单元(GU)网络的经常性神经网络(RNN),或者是多个 -用于数字特征数据的Layer Perceptron(MLP)网络。您可以在CPU或GPU上培训。对于图像分类和图像回归,您可以使用多个GPU或并行训练。使用GPU,Multi-GPU和并行选项需要并行计算工具箱™。要使用GPU进行深度学习,还必须有CUDA®启用nvidia.®GPU,计算能力3.0或更高。要指定培训选项,包括执行环境的选项,请使用培训选项函数。
网= trainnetwork(洛桑国际管理发展学院,层,选项)层用于使用图像数据存储中的图像和标签的图像分类任务洛桑国际管理发展学院和培训选项定义选项.
例子
用于图像分类的火车网络
将数据加载为ImageDatastore目的。
digitdatasetpath = fullfile(matlabroot,'工具箱',“nnet”,...“nndemos”,“nndatasets”,'digitdataset');imds = imageageataStore(DigitDatasetPath,...'insertumbfolders',真的,...'labelsource',“foldernames”);
数据存储区包含从0到9的数字的10,000个合成图像。通过将随机变换应用于以不同字体创建的数字图像来生成图像。每个数字图像是28×28像素。数据存储区每个类别包含相同数量的图像。
在数据存储中显示一些图像。
图numimages = 10000;perm = randperm(numimages,20);为了I = 1:20 subplot(4,5, I);imshow (imds.Files{烫发(i)});drawnow;结束

划分数据存储,以便培训集中的每个类别具有750个图像,并且测试集具有来自每个标签的剩余图像。
numTrainingFiles = 750;[imdsTrain, imdsTest] = splitEachLabel (imd, numTrainingFiles“随机”);
splitEachLabel分割图像文件digitdata.进入两个新数据存储,Imdstrain.和Inmdstest..
定义卷积神经网络架构。
层= [...imageInputLayer([28 28 1])卷积2dlayer (5,20) reluLayer maxPooling2dLayer(2, 20)“步”,2)全连接列(10)SoftmaxLayer分类层];
将动量随机梯度下降的选项设置为默认设置。设置最大纪元数为20,初始学习率为0.0001,开始训练。
选择= trainingOptions ('sgdm',...'maxepochs'20,...'italllearnrate',1e-4,...'verbose',错误的,...“阴谋”,'培训 - 进步');
培训网络。
网= trainNetwork (imdsTrain层,选项);
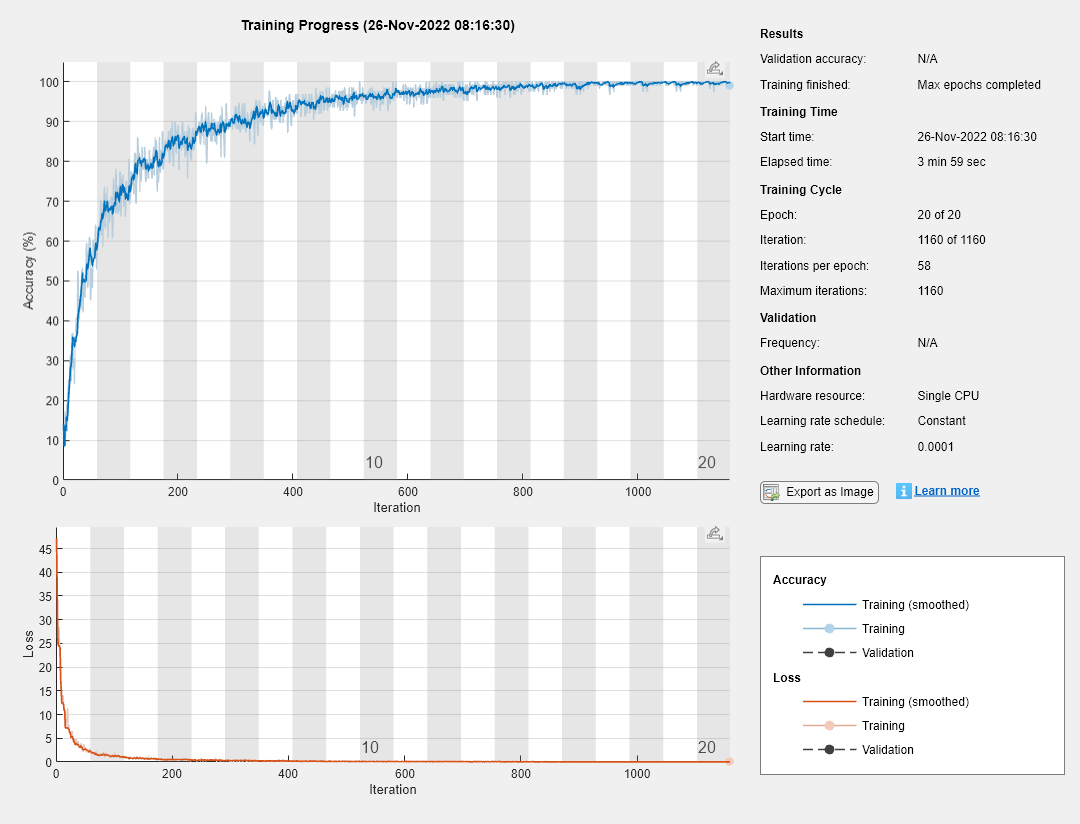
在未用于训练网络的测试集中运行训练网络,并预测图像标签(数字)。
Ypred =分类(网络,IMDSTEST);ytest = imdstest.labels;
计算准确性。准确性是测试数据中真实标签数与分类匹配的真实标签的比率分类到测试数据中的图像数量。
精度= sum(YPred == YTest)/numel(YTest)
精度= 0.9420.
用增强图像列车网络
使用增强图像数据列车卷积神经网络。数据增强有助于防止网络过度接收和记忆培训图像的确切细节。
加载样本数据,它由手写数字的合成图像组成。
[XTrain, YTrain] = digitTrain4DArrayData;
digittrain4darraydata.将数字训练集加载为4-D阵列数据。XTrain是一个28 × 28 × 1 × 5000的数组,其中:
28是图像的高度和宽度。
1是通道的数量。
5000是手写数字的合成图像数量。
ytrain.是一个包含每个观察标签的分类矢量。
预留1000个图像用于网络验证。
idx = randperm(大小(XTrain, 4), 1000);XValidation = XTrain (:,:,:, idx);XTrain (::,:, idx) = [];YValidation = YTrain (idx);YTrain (idx) = [];
创建一个imageDataAugmenter对象,该对象指定用于图像增强的预处理选项,如调整大小、旋转、平移和反射。随机将图像水平和垂直平移到三个像素,并旋转图像的角度高达20度。
imageAugmenter = imageDataAugmenter (...'randroatation'(-20年,20),...“RandXTranslation”3 [3],...'randytranslation'3 [3])
Imageaugmenter = ImagedataAugmenter具有属性:FileValue:0 RandXreflection:0 Randyreflection:0 RandRotation:[-20 20] RANDSCALE:[1] RANDXSCALE:[1] RANDYSCALE:[1] RANDXSHEAR:[0] RANDYSHEAR:[00] RandXTranslation:[-3 3] RandyTranslation:[-3 3]
创建一个AugmentedimageGedataStore.用于网络训练的对象并指定图像输出大小。在培训期间,数据存储区执行图像增强并调整图像大小。数据存储区增强了图像而不将任何图像保存到内存。trainNetwork更新网络参数,然后丢弃增强后的图像。
图像= [28 28 1];Augimds = AugmentedimageDataStore(图像化,Xtrain,Ytrain,“DataAugmentation”, imageAugmenter);
指定卷积神经网络架构。
[imageInputLayer(imageSize)] = [imageInputLayer(imageSize)]“填充”,'相同的')BatchnormalizationLayer Ruilulayer MaxPooling2dlayer(2,“步”,2)卷积2dlayer(3,16,“填充”,'相同的')BatchnormalizationLayer Ruilulayer MaxPooling2dlayer(2,“步”,2)卷积2dlayer(3,32,“填充”,'相同的') batchNormalizationLayer relullayer fulllyconnectedlayer (10) softmaxLayer classificationLayer];
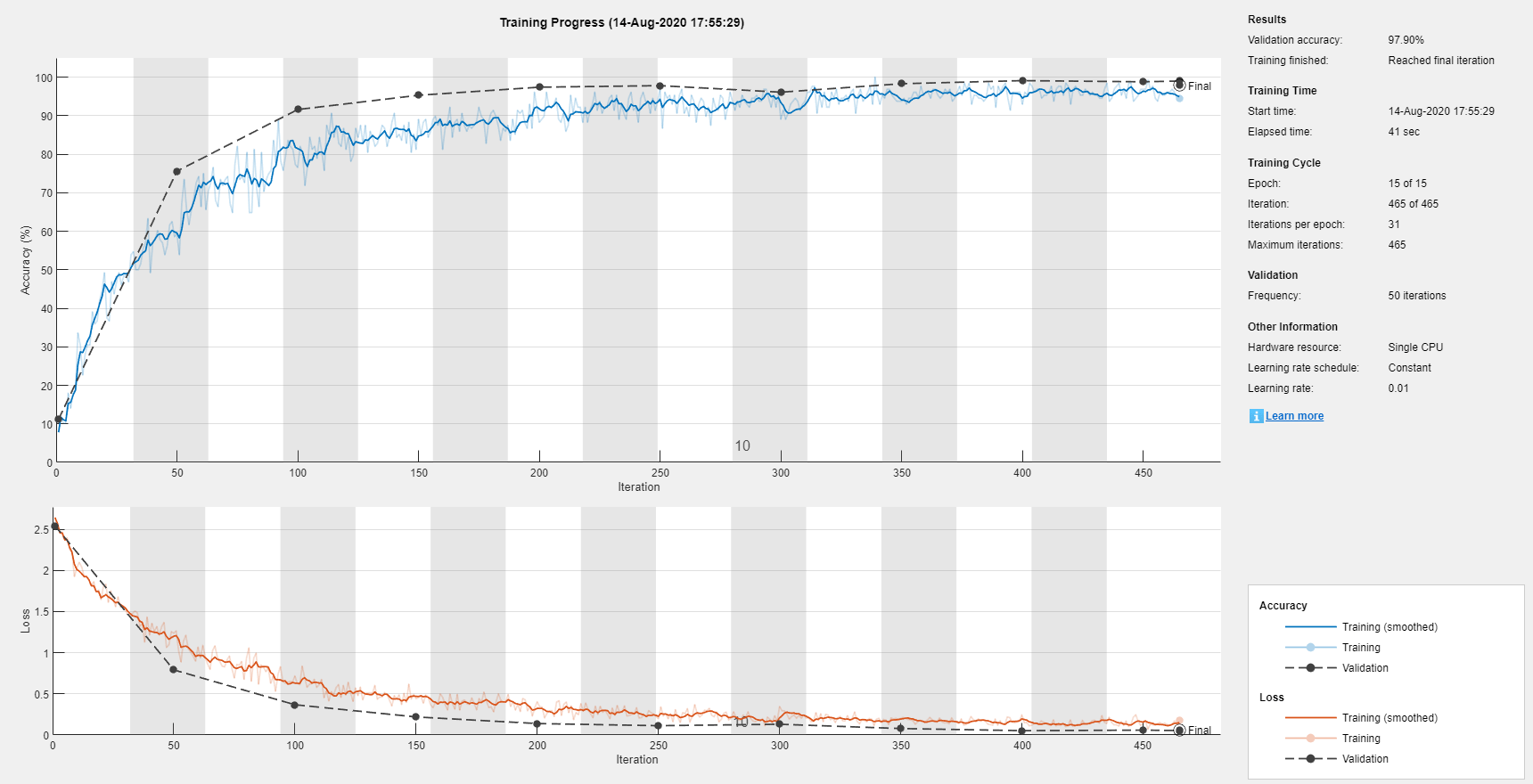
用动量指定随机梯度下降的培训选项。
选择=培训选项('sgdm',...'maxepochs'15,...“洗牌”,'每个时代',...“阴谋”,'培训 - 进步',...'verbose',错误的,...'vightationdata', {XValidation, YValidation});
培训网络。由于验证图像未增强,所以验证精度高于训练精度。
网= trainNetwork (augimds层,选择);
图像回归训练网络
加载样本数据,它由手写数字的合成图像组成。第三个输出包含相应的角度,每个图像被旋转的角度。
以4-D数组的形式加载训练图像digittrain4darraydata..输出XTrain是一个28 × 28 × 1 × 5000的数组,其中:
28是图像的高度和宽度。
1是通道的数量。
5000是手写数字的合成图像数量。
ytrain.包含度数的旋转角度。
[XTrain,〜,Ytrain] = Digittrain4darraydata;
显示20个随机训练图像imshow..
图numtrainimages = numel(ytrain);IDX = RANDPERM(NUMTRAIMIMAGES,20);为了i = 1:元素个数(idx)次要情节(4、5、i) imshow (XTrain (:,:,:, idx(我)))drawnow;结束
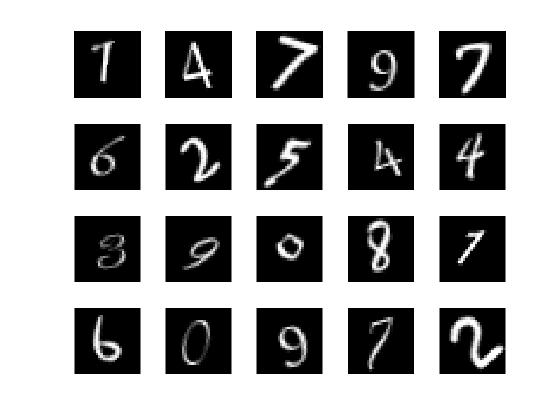
指定卷积神经网络架构。对于回归问题,包括在网络末尾的回归层。
层= [...imageInputLayer([28 28 1])卷积2dlayer(12,25)rululayer全连接列(1)回归层];
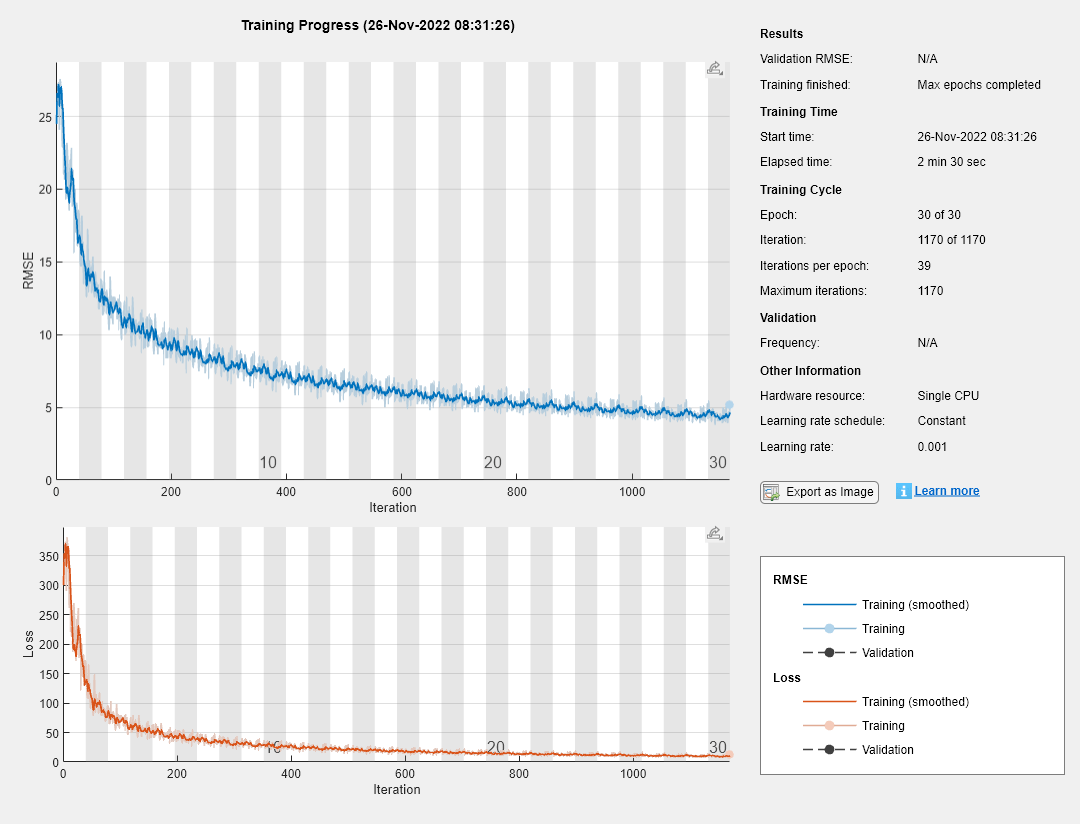
指定网络培训选项。设置初始学习率为0.001。
选择= trainingOptions ('sgdm',...'italllearnrate',0.001,...'verbose',错误的,...“阴谋”,'培训 - 进步');
培训网络。
网= trainNetwork (XTrain、YTrain层,选择);
通过评估测试数据的预测准确性来测试网络的性能。用预测来预测验证图像的旋转角度。
[xtest,〜,ytest] = dimittest4darraydata;ypred =预测(net,xtest);
通过计算预测和实际旋转角度的均方根误差(RMSE)来评估模型的性能。
rmse =√(mean((YTest - YPred).^2)))
RMSE =.单身的6.0356
序列分类训练网络
培训深度学习LSTM网络,用于序列到标签分类。
如[1]和[2]中所述加载日语元音数据集。XTrain是含有270个变化长度序列的细胞阵列,其具有对应于LPC综合系数的12个特征。Y是标签1,2,...,9的分类矢量。参赛作品XTrain是具有12行的矩阵(每个特征的一行)和不同数量的列(每次步骤一列)。
[XTrain, YTrain] = japaneseVowelsTrainData;
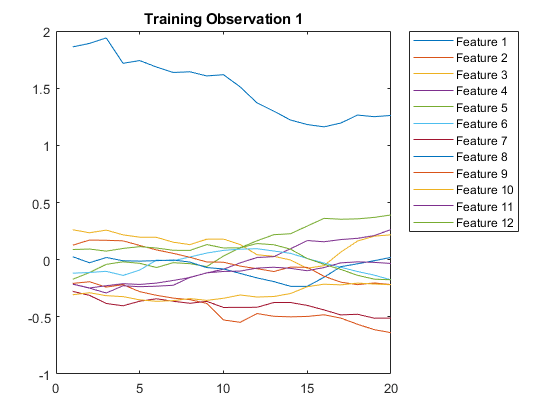
想象情节中的第一个时间序列。每一行对应一个特征。
图绘制(XTrain{1}”)标题(“训练观察1”)numfeatures = size(xtrain {1},1);传奇(“特征 ”+字符串(1:numFeatures),'地点',“northeastoutside”)
定义LSTM网络架构。指定输入大小为12(输入数据的功能数)。指定LSTM层以具有100个隐藏单元,并输出序列的最后一个元素。最后,通过包括一个完全连接的大小9层来指定九类,然后是Softmax层和分类层。
inputSize = 12;numHiddenUnits = 100;numClasses = 9;层= [...sequenceInputLayer inputSize lstmLayer (numHiddenUnits,'OutputMode',“最后一次”)软连接层(numClasses)
图层= 5×1层阵列,带有图层:1''序列输入序列输入,带12尺寸2''LSTM LSTM,具有100个隐藏单元3'完全连接的9个完全连接的第4层''Softmax SoftMax 5''分类输出CrossentRopyex
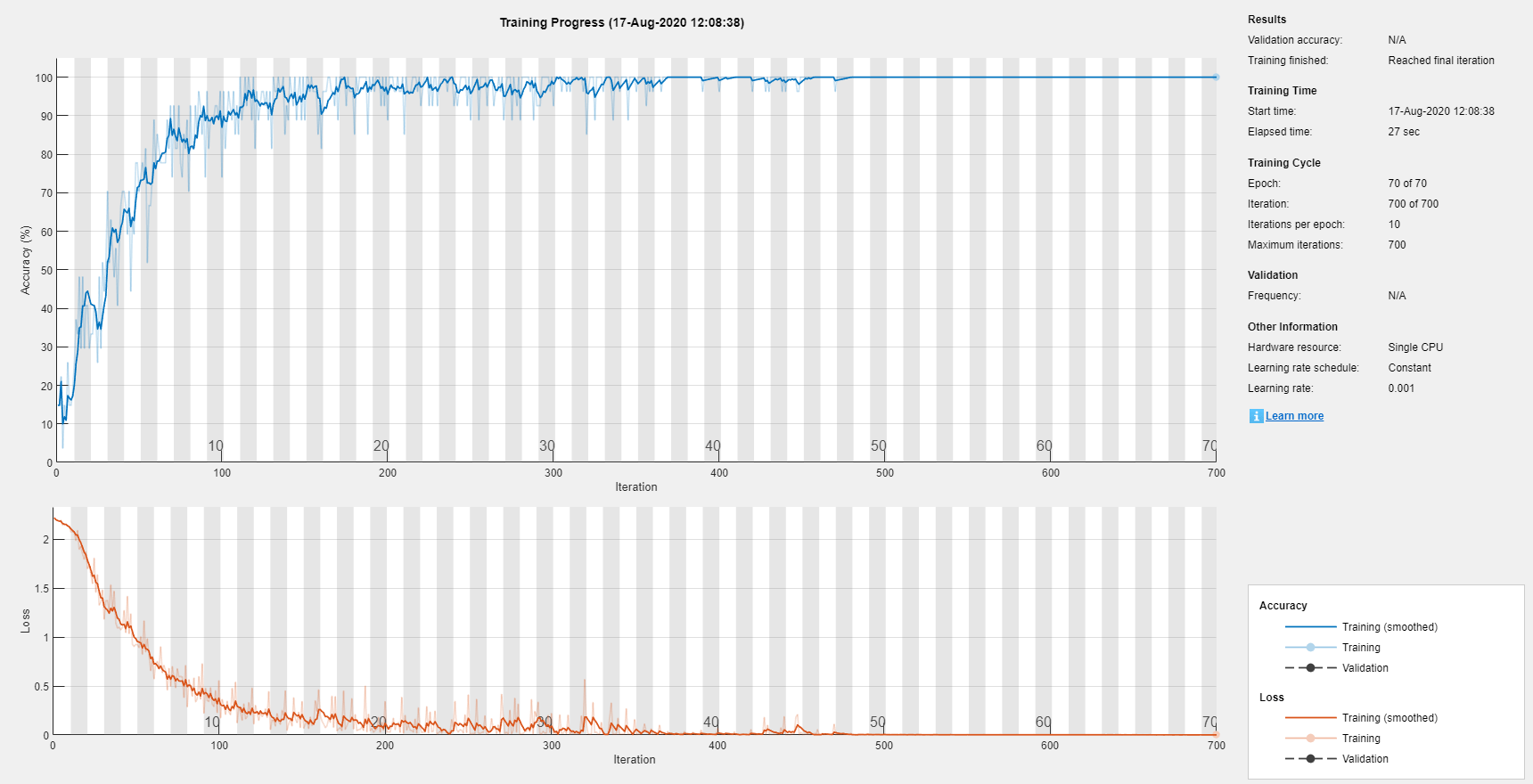
指定培训选项。指定求解器为'亚当'和'gradientthreshold'作为1.将迷你批量尺寸设置为27并将最大数量的时期设置为70。
由于迷你批次具有短序列,因此CPU更适合培训。放“ExecutionEnvironment”到“cpu”.在GPU上训练,如果有的话,设置“ExecutionEnvironment”到“汽车”(默认值)。
maxEpochs = 70;miniBatchSize = 27个;选择= trainingOptions ('亚当',...“ExecutionEnvironment”,“cpu”,...'maxepochs',maxepochs,...“MiniBatchSize”,小匹马,...'gradientthreshold',1,...'verbose',错误的,...“阴谋”,'培训 - 进步');
使用指定的训练选项训练LSTM网络。
网= trainNetwork (XTrain、YTrain层,选择);
加载测试集并将序列分类为扬声器。
[XTest,欧美]= japaneseVowelsTestData;
分类测试数据。指定用于培训的相同百分比大小。
XTest YPred =分类(净,“MiniBatchSize”, miniBatchSize);
计算预测的分类精度。
ACC = SUM(YPRED == ytest)./ numel(ytest)
ACC = 0.9514.
用数字功能列车网络
如果您有一个数字特征的数据集(例如没有空间或时间尺寸的数字数据集合),则可以使用特征输入层培训深度学习网络。
从CSV文件读取传输壳体数据“transactionscasingdata.csv”.
文件名=“transactionscasingdata.csv”;台= readtable(文件名,“TextType”,'细绳');
属性将用于预测的标签转换为分类的转录Vars.函数。
labelName =“齿轮技术”;tbl = convedvars(tbl,labelname,“分类”);
要使用分类功能培训网络,必须首先将分类功能转换为数字。首先,将分类预测因子转换为分类转录Vars.通过指定包含所有分类输入变量的名称的字符串数组。在此数据集中,有两个具有名称的分类功能“传感器”和“shaftcondition”.
categoricalInputNames = [“传感器”“shaftcondition”];台= convertvars(资源描述、categoricalInputNames“分类”);
循环分类输入变量。为每一个变量:
将分类值转换为使用的一个热编码向量
onehotencode函数。使用介绍将单热量向量添加到表中
addvars.函数。指定在包含相应的分类数据的列后插入向量。删除包含分类数据的相应列。
为了i = 1:numel(categoricalInputNames) name = categoricalInputNames(i);哦= onehotencode(资源描述(:,名字));台= addvars(资源描述,哦,“后”,姓名);tbl(:,name)= [];结束
将向量分割成单独的列splitvars函数。
tbl = splitvars(tbl);
查看表的前几行。请注意,分类预测器被分割为多个列,其中分类值作为变量名。
头(TBL)
ans =8×23表SigMean SigMedian SigRMS SigVar SigPeak SigPeak2Peak SigSkewness SigKurtosis SigCrestFactor SigMAD SigRangeCumSum SigCorrDimension SigApproxEntropy SigLyapExponent PeakFreq HighFreqPower EnvPower PeakSpecKurtosis无传感器漂移传感器漂移无轴的磨损轴的磨损GearToothCondition ________ _________ ______ _______ _______ ____________ ___________ ___________ ______________ _______ ______________ ________________ ________________ _______________ ________ _____________ ________ ________________ _______________ ____________ _______________________ __________________ -0.94876 -0.9722 1.3726 0.98387 0.81571 3.6314 -0.041525 2.2666 2.0514 0.8081 28562 1.1429 0.031581 79.931 0 6.75e-06 3.23e-07 162.13 0 1 1 0无齿故障-0.97537 -0.98958 1.3937 0.99105 0.81571 3.6314 -0.023777 2.2598 2.0203 0.81017 294181.1362 0.037835 70.325 0 5.08E-08 9.16E-08 226.12 0 1 1 0无齿故障1.0502 1.0267 1.4449 0.98491 2.8157 3.6314 -0.04162 2.2658 1.9487 0.80853 31712 0.80853 31710 1.1479 0.0.031565 125.19 0 6.74e-06 2.85E-07 162.13 0 1 0 1无齿故障1.0227 1.4288 0.99553 2.8157 3.6314 -0.016356 2.2483 1.9707 0.81324 30984 0.81324 30984 0.81324 30984 1.1472 0.0.0 4.0 4.0 4.0 40-071112.5 0 1 0 1/10 1 0 40 40-07 162.13 0 1 0 1无齿故障1.0123 1.0024 1.01230.99233 2.8157 3.6314 -0.014701 2.2542 1.9826 0.81156 30661 1.1469 0.03287 108.86 0 3.62E-06 2.28e-07 230.39 0 1 0 1无齿故障1.0275 1.0102 1.4338 1.0001 2.8157 3.6314 -0.02659 2.2439 1.9638 0.81589 31102 1.0985 0.033427 64.576 0 2.55e-06 1.65e-07 230.39 0 1 0 1无齿故障1.0464 1.0275 1.4477 1.0011 2.8157 3.6314 -0.042849 2.2455 1.9449 0.81595 2.9449 0.81595 1.9449 0.81595 3.9449 0.81595 3.9449 0.81595 31665 1.1415 0. 0.0 1.73C-06 1.552-07/12.81590 1.0.035405 2.2757 1.955 0.80583 0.80583 31554 1.1345 0.0353 44.223 0 1.11E-06 1.39E-07 230.39 0 1 0 1无齿故障
查看数据集的类名。
ClassNames =类别(TBL {:,labelName})
一会=2×1细胞{'无牙齿故障'}{'牙齿故障'}
接下来,将数据分区设置为训练和测试分区。留出15%的测试数据。
确定每个分区的观察数。
numObservations =大小(1台);numObservationsTrain =地板(0.85 * numObservations);numObservationsTest = numObservations - numObservationsTrain;
使用分区大小创建与观察和分区对应的随机索引数组。
idx = randperm(numobservations);idxtrain = idx(1:numobservationstrain);iDxtest = idx(numobservationstrain + 1:结束);
使用索引将数据表划分为训练、验证和测试分区。
tblTrain =(资源(idxTrain:);tblTest =(资源(idxTest:);
定义一个具有特征输入层的网络,并指定特征的数量。另外,配置输入层,使用Z-score标准化对数据进行标准化。
numfeatures =尺寸(tbl,2) - 1;numclasses = numel(classnames);图层= [FeatureInputLayer(NumFeatures,“归一化”,“zscore”) fulllyconnectedlayer (50) batchNormalizationLayer relullayer fulllyconnectedlayer (numClasses) softmaxLayer classificationLayer];
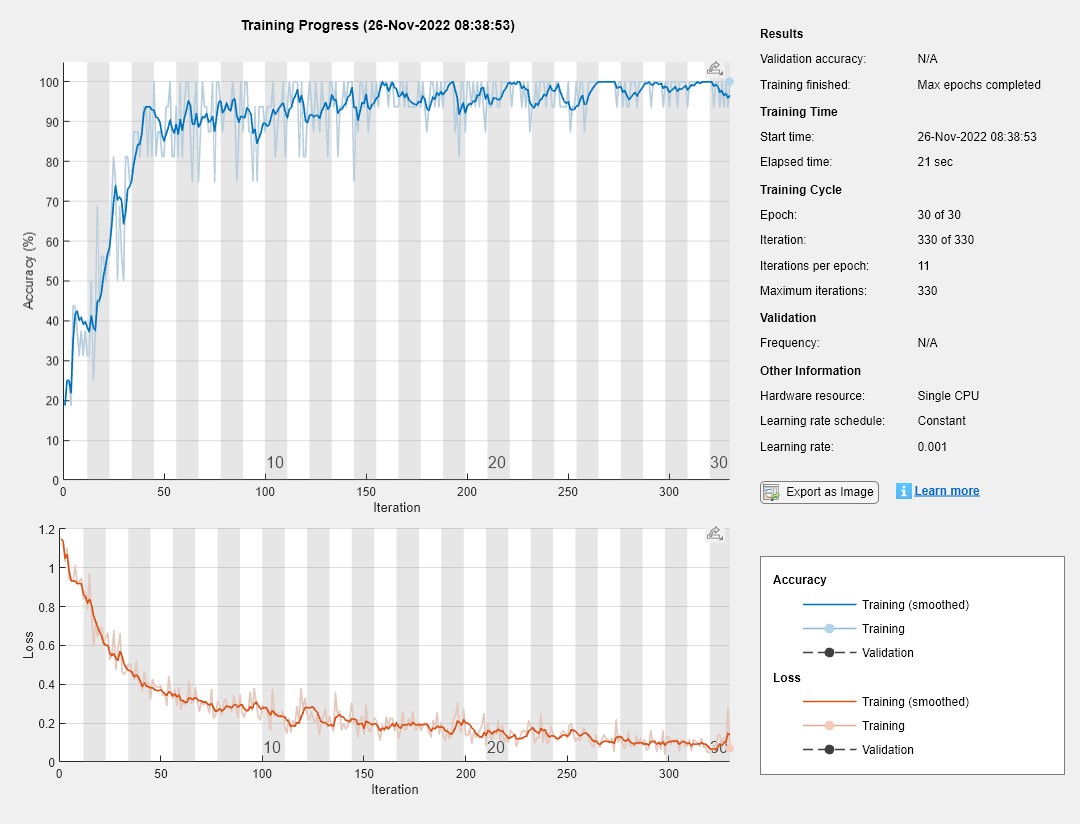
指定培训选项。
miniBatchSize = 16;选择= trainingOptions ('亚当',...“MiniBatchSize”,小匹马,...“洗牌”,'每个时代',...“阴谋”,'培训 - 进步',...'verbose',错误的);
使用由架构定义的架构列车层、培训数据和培训选项。
网= trainNetwork (tblTrain层,选项);
使用培训的网络预测测试数据的标签并计算精度。准确性是网络正确预测的标签的比例。
tblTest YPred =分类(净,“MiniBatchSize”, miniBatchSize);欧美= tblTest {: labelName};精度= sum(YPred == YTest)/numel(YTest)
精度= 0.9688
输入参数
输出参数
更多关于
参考文献
工藤,富山,新博。“使用通过区域的多维曲线分类”。模式识别的字母.卷。20,第11-13页,第11-13页,第1103-1111111111。
[2] Kudo,M.,J. Toyama和M. Shimbo。日本元音数据集.https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
扩展能力
您还可以从以下列表中选择一个网站:
