augmentedImageDatastore
转换批处理以增强图像数据
描述
增强图像数据存储通过可选的预处理(如调整大小、旋转和反射)对训练、验证、测试和预测数据进行批量转换。调整图像的大小,使其与深度学习网络的输入大小兼容。使用随机预处理操作增加训练图像数据,以帮助防止网络过度拟合和记忆训练图像的确切细节。
要使用增强图像训练网络,请提供augmentedImageDatastore来trainNetwork.有关更多信息,请参见深度学习的图像预处理.
当您使用扩充图像数据存储作为训练图像的来源时,该数据存储将随机扰动每个epoch的训练数据,因此每个epoch使用略有不同的数据集。每个纪元的实际训练图像数量没有变化。转换后的图像不存储在内存中。
一个
imageInputLayer使用增广图像的均值而不是原始数据集的均值对图像进行归一化。这个平均数对于第一个增广期计算一次。所有其他纪元使用相同的平均值,这样平均图像不会在训练过程中发生变化。
默认情况下,一个augmentedImageDatastore仅调整图像大小以适应输出大小。控件可以配置其他图像转换选项imageDataAugmenter.
创建
语法
描述
auimds = augmentedImageDatastore (outputSize,使用图像数据存储中的图像创建一个扩充的图像数据存储,用于分类问题洛桑国际管理发展学院)洛桑国际管理发展学院,并设置OutputSize
auimds = augmentedImageDatastore (outputSize,创建一个扩充的图像数据存储,用于预测数组中的图像数据的响应X)X.
auimds = augmentedImageDatastore (outputSize,为分类和回归问题创建一个扩充的图像数据存储。桌上,资源描述)资源描述,包含预测因素和反应。
auimds = augmentedImageDatastore (outputSize,为分类和回归问题创建一个扩充的图像数据存储。桌上,资源描述,responseNames)资源描述,包含预测因素和反应。的responseNames参数指定的响应变量资源描述.
auimds = augmentedImageDatastore (___、名称、值)创建扩展的图像数据存储,使用名称-值对设置ColorPreprocessingDataAugmentationOutputSizeModeDispatchInBackground
例如,myTable augmentedImageDatastore([28日28],“OutputSizeMode”,“centercrop”)创建一个增强图像数据存储,从中心裁剪图像。
输入参数
属性
对象的功能
结合 |
合并来自多个数据存储的数据 |
hasdata |
确定是否可以读取数据 |
numpartitions |
数据存储分区数 |
分区 |
分区数据存储 |
partitionByIndex |
分区augmentedImageDatastore根据指数 |
预览 |
预览数据存储中的数据子集 |
读 |
读取的数据augmentedImageDatastore |
readall |
读取数据存储中的所有数据 |
readByIndex |
读取由index指定的数据augmentedImageDatastore |
重置 |
将数据存储重置为初始状态 |
洗牌 |
混乱的数据augmentedImageDatastore |
子集 |
创建数据存储或文件集的子集 |
变换 |
变换数据存储 |
isPartitionable |
确定数据存储是否可分区 |
isShuffleable |
确定数据存储是否可洗牌 |
例子
带有增强图像的列车网络
利用增强图像数据训练卷积神经网络。数据增强有助于防止网络过度拟合和记忆训练图像的确切细节。
加载样本数据,它由手写数字的合成图像组成。
[XTrain, YTrain] = digitTrain4DArrayData;
digitTrain4DArrayData将数字训练集加载为4-D阵列数据。XTrain是一个28 × 28 × 1 × 5000的数组,其中:
28是图像的高度和宽度。
1是通道的数量。
5000是手写数字合成图像的数量。
YTrain是包含每个观察的标签的分类向量。
预留1000个图像用于网络验证。
idx = randperm(大小(XTrain, 4), 1000);XValidation = XTrain (:,:,:, idx);XTrain (::,:, idx) = [];YValidation = YTrain (idx);YTrain (idx) = [];
创建一个imageDataAugmenter对象,该对象指定用于图像增强的预处理选项,如调整大小、旋转、平移和反射。随机将图像水平和垂直平移到三个像素,并旋转图像的角度高达20度。
imageAugmenter = imageDataAugmenter (...“RandRotation”(-20年,20),...“RandXTranslation”3 [3],...“RandYTranslation”3 [3])
imageAugmenter = imageDataAugmenter with properties: 0 RandXReflection: 0 RandYReflection: 0 RandRotation: [-20 20] RandScale: [1 1] RandXScale: [1 1] RandYScale: [1 1] RandXShear: [0 0] RandYShear: [0 0] RandXTranslation: [-3 3] RandYTranslation: [-3 3]
创建一个augmentedImageDatastore对象用于网络训练并指定图像输出大小。在训练期间,数据存储执行图像增强和调整图像的大小。数据存储增加图像而不保存任何图像到内存。trainNetwork更新网络参数,然后丢弃增强后的图像。
imageSize = [28 28 1];augimds = augmentedImageDatastore(图象尺寸、XTrain YTrain,“DataAugmentation”, imageAugmenter);
指定卷积神经网络结构。
[imageInputLayer(imageSize)] = [imageInputLayer(imageSize)]“填充”,“相同”maxPooling2dLayer(2,“步”2) convolution2dLayer(16日“填充”,“相同”maxPooling2dLayer(2,“步”32岁的,2)convolution2dLayer (3“填充”,“相同”) batchNormalizationLayer relullayer fulllyconnectedlayer (10) softmaxLayer classificationLayer];
为带动量的随机梯度下降指定训练选项。
选择= trainingOptions (“个”,...“MaxEpochs”15岁的...“洗牌”,“every-epoch”,...“阴谋”,“训练进步”,...“详细”假的,...“ValidationData”, {XValidation, YValidation});
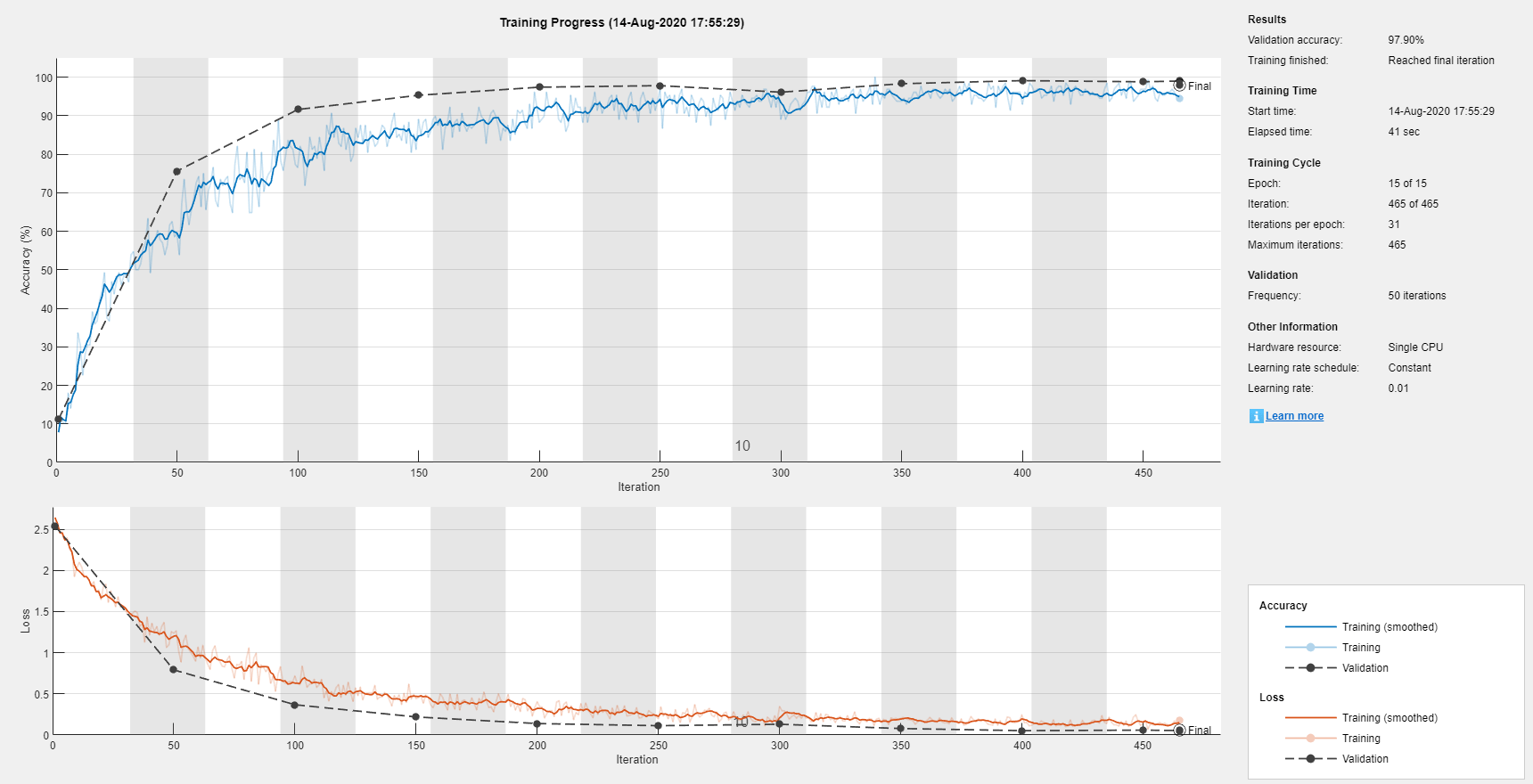
培训网络。由于没有对验证图像进行增强,验证精度高于训练精度。
网= trainNetwork (augimds层,选择);
提示
控件可以在同一个图形中可视化多个变换后的图像
imtile函数。例如,这段代码显示了来自称为auimds.minibatch =阅读(auimds);imshow (imtile (minibatch.input))
默认情况下,调整大小是对图像执行的唯一图像预处理操作。属性启用其他预处理操作
DataAugmentationimageDataAugmenter对象。每次从增强图像数据存储中读取图像时,将对每个图像应用不同的随机预处理操作组合。
你也可以从以下列表中选择一个网站:
