PixellabelimagedAtastore.
语义分割网络的数据存储
描述
使用PixellabelimagedAtastore.创建一个数据存储,用于使用深度学习训练语义分割网络。
创建
句法
描述
pximds.= pixellabelimagedataStore(GTRUTH.)地面对象或数组地面对象。使用输出PixellabelimagedAtastore.对象,使用深度学习工具箱™函数trainNetwork(深度学习工具箱)训练卷积神经网络进行语义分割。
pximds.= pixellabelimagedataStore(IMDS.那PXDS.)IMDS.是一个imageageAtastore.对象,表示对网络的训练输入。PXDS.是A.PixelLabelDatastore代表所需网络输出的对象。
pximds.= pixellabelimagedataStore(___那名称,值)DisparctinBackground.和OutputSizeMode属性。对于2-D数据,还可以使用名称-值对指定colorpreprocessing那dataaugmentation.,OutputSize增加属性。可以指定多个名称-值对。将每个属性名用引号括起来。
例如,pixelLabelImageDatastore (gTruth PatchesPerImage, 40)创建像素标签图像数据存储,随机生成40个补丁从每个地面真理对象GTRUTH..
输入参数
特性
对象的功能
结合 |
将数据与多个数据存储组合 |
countEachLabel |
计数像素或盒标签的出现次数 |
hasdata |
确定数据是否可用读取 |
PartitionByIndex. |
划分PixellabelimagedAtastore.根据指数 |
预习 |
在数据存储区中预览数据子集 |
读 |
从数据存储中读取数据 |
读物 |
读取数据存储中的所有数据 |
readByIndex |
读取由索引指定的数据PixellabelimagedAtastore. |
重置 |
将数据存储重置为初始状态 |
洗牌 |
返回打乱的数据存储版本 |
变换 |
转换数据存储 |
例子
训练一个语义分割网络
加载培训数据。
datasetdir = fullfile(toolboxdir('想象'),“visiondata”那'triangleimages');imageDir = fullfile (dataSetDir,'培训码');labelDir = fullfile (dataSetDir,'训练标签');
为图像创建图像数据存储。
IMDS = IMAGEDATASTORE(IMAGEDIR);
创建一个PixellabeldAtastore.对于地面真相像素标签。
一会= [“三角形”那“背景”];labelids = [255 0];pxds = pixellabeldataStore(Labeldir,ClassNames,LabelIds);
可视化训练图像和地面真实像素标签。
我=读(imd);C =阅读(pxds);I = imresize (5);L = imresize (uint8 (C {1}), 5);imshowpair (L,我'剪辑')

创建语义分段网络。该网络基于下采样和上采样设计使用简单的语义分割网络。
numfilters = 64;filtersize = 3;numclasses = 2;图层= [imageInputlayer([32 32 1])卷积2dlayer(过滤,numfilters,'填充',1)rululayer()maxpooling2dlayer(2,'走吧',2)卷积2dlayer(过滤,numfilters,'填充'(1) reluLayer) transposedConv2dLayer (4 numFilters'走吧'2,'裁剪'1);numClasses convolution2dLayer(1日);pixelClassificationLayer softmaxLayer () ())
图层= 10×1层阵列,图层:1''图像输入32×32×1图像,带有'Zerocenter'归一化2''卷积64 3×3卷绕升温[11]和填充[1 1 1 1] 3''Relu Relu 4''最大汇集2×2最大汇集步进[2 2]和填充[0 0 0 0] 5''卷积64 3×3卷绕步进[1 1]和填充[1 1 1 1] 6''Relu Relu 7''转换卷积64 4×4带有步部的转换卷积[2 2]和裁剪[111 1] 8''卷积2 1×1卷曲[11]和填充[00 0 0] 9''softmax softmax 10''像素分类层交叉熵损耗
设置培训选项。
选择= trainingOptions ('sgdm'那...“InitialLearnRate”1 e - 3,...“MaxEpochs”,100,...'minibatchsize',64);
结合图像和像素标签数据存储进行训练。
trainingdata = pixellabelimagedataStore(IMDS,PXD);
训练网络。
网= trainNetwork (trainingData层,选择);
单CPU训练。初始化输入数据规范化。|========================================================================================||时代|迭代|经过时间的时间迷你批量|迷你批量|基础学习| | | | (hh:mm:ss) | Accuracy | Loss | Rate | |========================================================================================| | 1 | 1 | 00:00:00 | 58.11% | 1.3458 | 0.0010 | | 17 | 50 | 00:00:11 | 97.30% | 0.0924 | 0.0010 | | 34 | 100 | 00:00:23 | 98.09% | 0.0575 | 0.0010 | | 50 | 150 | 00:00:34 | 98.56% | 0.0424 | 0.0010 | | 67 | 200 | 00:00:46 | 98.48% | 0.0435 | 0.0010 | | 84 | 250 | 00:00:58 | 98.66% | 0.0363 | 0.0010 | | 100 | 300 | 00:01:09 | 98.90% | 0.0310 | 0.0010 | |========================================================================================|
读取并显示测试图像。
testImage = imread ('triangletest.jpg');imshow (testImage)
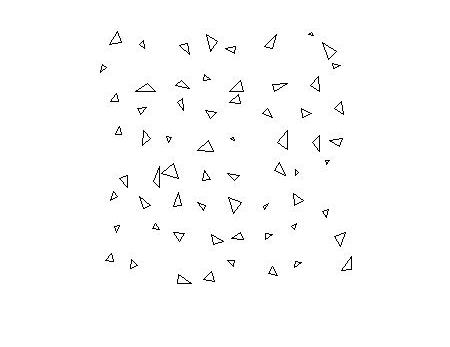
分段测试图像并显示结果。
C = SemanticSeg(Testimage,Net);B = Labeloverlay(Testimage,C);imshow(b)

改善结果
网络无法段分割三角形并将每个像素分类为“背景”。培训似乎与大于90%的训练准确性进展顺利。但是,该网络仅学习以对背景类进行分类。要了解为什么发生这种情况,您可以在数据集中计算每个像素标签的发生。
台= countEachLabel (pxds)
TBL =2×3表名字PixelCount ImagePixelCount ______________ __________ _______________ {' 三角形的}10326 2.048 e + 05年{‘背景’}1.9447 e + 05年2.048 e + 05
大多数像素标签用于背景。结果不佳是由于阶级不平衡。类别不平衡偏见了学习过程,支持主导类。这就是为什么每个像素被归类为“背景”。要解决这个问题,可以使用类权重来平衡类。有几种计算类别的方法。一种常见的方法是逆频率加权,其中类权重是类频率的倒数。这会增加给代表欠款的类别。
TotalNumberofpixels = SUM(TBL.PIXELCOUNT);频率= tbl.pixelcount / totalnumberofpixels;Classweights = 1./罚款
classWeights =2×119.8334 - 1.0531
类权重可以使用pixelClassificationLayer.更新最后一个图层以使用apixelClassificationLayer用逆类权重。
层(结束)= pixelClassificationLayer (“类”资源描述。的名字,“ClassWeights”,类别);
再次火车网络。
网= trainNetwork (trainingData层,选择);
单CPU训练。初始化输入数据规范化。|========================================================================================||时代|迭代|经过时间的时间迷你批量|迷你批量|基础学习| | | | (hh:mm:ss) | Accuracy | Loss | Rate | |========================================================================================| | 1 | 1 | 00:00:00 | 72.27% | 5.4135 | 0.0010 | | 17 | 50 | 00:00:11 | 94.84% | 0.1188 | 0.0010 | | 34 | 100 | 00:00:23 | 96.52% | 0.0871 | 0.0010 | | 50 | 150 | 00:00:35 | 97.29% | 0.0599 | 0.0010 | | 67 | 200 | 00:00:47 | 97.46% | 0.0628 | 0.0010 | | 84 | 250 | 00:00:59 | 97.64% | 0.0586 | 0.0010 | | 100 | 300 | 00:01:10 | 97.99% | 0.0451 | 0.0010 | |========================================================================================|
尝试再次分割测试图像。
C = SemanticSeg(Testimage,Net);B = Labeloverlay(Testimage,C);imshow(b)

使用类加权来平衡类,产生了更好的分割结果。改进结果的其他步骤包括增加用于训练的纪元的数量、添加更多的训练数据或修改网络。
在训练时增加数据
配置像素标签图像数据存储以在训练时增强数据。
加载训练图像和像素标签。
datasetdir = fullfile(toolboxdir('想象'),“visiondata”那'triangleimages');imageDir = fullfile (dataSetDir,'培训码');labelDir = fullfile (dataSetDir,'训练标签');
创建一个imageageAtastore.持有培训图像的对象。
IMDS = IMAGEDATASTORE(IMAGEDIR);
定义类名称及其关联的标签ID。
一会= [“三角形”那“背景”];labelids = [255 0];
创建一个PixellabeldAtastore.对象握住训练图像的地面真相像素标签。
pxds = pixellabeldataStore(Labeldir,ClassNames,LabelIds);
创建一个imageDataAugmenter对象随机旋转和镜像图像数据。
增量= imageDataAugmenter (“RandRotation”-10年[10],'randxreflection',真正的)
Augmenter = ImagedataAugmenter具有属性:Filevalue:0 RandXreflection:1 Randyreflection:0 RandRotation:[-10 10] RANDSCALE:[1] RANDXSCALE:[1] RANCYSCALE:[1] RANDXSHEAR:[0] RANDXSHEAR:[0] RANDYSHEAR:[00] randxtranslation:[0] RandyTranslation:[0 0]
创建一个PixellabelimagedAtastore.目的利用增强数据对网络进行训练。
plimds = pixellabelimagedataStore(IMDS,PXD,'dataaugmentation'增量)
plimds = pixelLabelImageDatastore with properties: Images: {200x1 cell} PixelLabelData: {200x1 cell} ClassNames: {2x1 cell} DataAugmentation: [1x1 imageDataAugmenter] ColorPreprocessing: 'none' OutputSize: [] OutputSizeMode: 'resize' MiniBatchSize: 1 NumObservations: 200 DispatchInBackground: 0
使用扩张卷积的语义分割
使用扩展卷积训练语义分割网络。
语义分割网络对图像中的每个像素进行分类,导致由类分段的图像。语义分割的应用包括用于自主驾驶和癌细胞分段的道路分割,用于医学诊断。要了解更多信息,请参阅使用深度学习开始语义分割.
像DeepLab[1]这样的语义分割网络广泛使用扩张卷积(也称为atrous卷积),因为它们可以增加层的接受域(层可以看到的输入区域),而不增加参数或计算的数量。
负荷训练数据
该示例使用32×32三角形图像的简单数据集以用于说明目的。数据集包括伴随像素标签地面真实数据。使用一个加载训练数据imageageAtastore.和一个PixellabeldAtastore..
datafolder = fullfile(toolboxdir('想象'),“visiondata”那'triangleimages');imageFolderTrain = fullfile (dataFolder,'培训码');labelfoldertrain = fullfile(datafolder,'训练标签');
创建一个imageageAtastore.对于图像。
imdsTrain = imageDatastore (imageFolderTrain);
创建一个PixellabeldAtastore.对于地面真相像素标签。
一会= [“三角形”“背景”];标签= [255 0];pxdsTrain = pixelLabelDatastore (labelFolderTrain、类名、标签)
pxdstrain = pixellabeldataStore与属性:文件:{200x1 cell} classNames:{2x1 cell} readsize:1 readfcn:@readdataStoreimage alternatefilesystemroots:{}
创建语义分割网络
此示例使用基于扩展卷积的简单语义分段网络。
为训练数据创建一个数据源,并获取每个标签的像素计数。
pximdstrain = pixellabelimagedataStore(imdstrain,pxdstrain);TBL = CONSECHANCELABEL(PXDSTRAIN)
TBL =2×3表名字PixelCount ImagePixelCount ______________ __________ _______________ {' 三角形的}10326 2.048 e + 05年{‘背景’}1.9447 e + 05年2.048 e + 05
大多数像素标签用于背景。这种阶级失衡使学习过程偏向于主导阶级。要解决这个问题,可以使用类权重来平衡类。可以使用几种方法来计算类权重。一种常见的方法是逆频率加权,其中类权重是类频率的倒数。这个方法增加了给予未表示的类的权重。使用反频率加权计算类别权重。
numberpixels = sum(tbl.pixelcount);频率= tbl.pixelcount / numperspixels;Classweights = 1 ./频率;
通过使用与输入图像的大小对应的输入大小的图像输入层创建用于像素分类的网络。接下来,指定三个卷积块,批量标准化和Relu层。对于每个卷积层,指定32个3×3滤波器,随着扩张因子的增加并填充输入,使它们与输出相同,通过设置'填充'选择“相同”.要对像素分类,请包括卷积层K.1×1的卷积,K.是类的数量,后跟一个softmax层和一个pixelClassificationLayer用相反的类权重。
InputSize = [32 32 1];filtersize = 3;numfilters = 32;numclasses = numel(classnames);图层= [ImageInputLayer(InputSize)Convolution2Dlayer(过滤,NumFilters,'膨胀因子',1,'填充'那“相同”) batchNormalizationLayer reluLayer卷积2dlayer (filterSize,numFilters,'膨胀因子'2,'填充'那“相同”) batchNormalizationLayer reluLayer卷积2dlayer (filterSize,numFilters,'膨胀因子',4,'填充'那“相同”) batchNormalizationLayer reluLayer卷积2dlayer (1,numClasses) softmaxLayer pixelClassificationLayer(“类”一会,“ClassWeights”classWeights)];
火车网络
指定培训选项。
选择= trainingOptions ('sgdm'那...“MaxEpochs”,100,...'minibatchsize', 64,...“InitialLearnRate”,1E-3);
使用培训网络trainNetwork.
net = trainnetwork(pximdstrain,图层,选项);
单CPU训练。初始化输入数据规范化。|========================================================================================| | 时代| |迭代时间| Mini-batch | Mini-batch |基地学习 | | | | ( hh: mm: ss) | | |丧失准确性 | |========================================================================================| | 1 | 1 |就是| | 1.6825 | 0.0010 91.62%||17 |50 |00:00:20 | 88.56% | 0.2393 | 0.0010 | | 34 | 100 | 00:00:39 | 92.08% | 0.1672 | 0.0010 | | 50 | 150 | 00:00:57 | 93.17% | 0.1472 | 0.0010 | | 67 | 200 | 00:01:14 | 94.15% | 0.1313 | 0.0010 | | 84 | 250 | 00:01:33 | 94.47% | 0.1167 | 0.0010 | | 100 | 300 | 00:01:51 | 95.04% | 0.1100 | 0.0010 | |========================================================================================|
测试网络
加载测试数据。创建一个imageageAtastore.对于图像。创建一个PixellabeldAtastore.对于地面真相像素标签。
imagefoldertest = fullfile(datafolder,'testimages');imdstest = imageageataStore(imagefoldertest);labelfoldertest = fullfile(datafolder,'testlabels');pxdsTest = pixelLabelDatastore (labelFolderTest、类名、标签);
利用测试数据和训练网络进行预测。
pxdsPred = semanticseg (imdsTest净,'minibatchsize'32岁的'writeelocation', tempdir);
运行语义分割网络------------------------------- * Processed 100图像。
使用预测精度评估预测精度评估评估.
指标= evaluateSemanticSegmentation (pxdsPred pxdsTest);
评估语义分割结果--------------------------------- *所选指标:全球准确性,课程准确性,iou,加权iou,bf得分。*处理100个图像。*完成......完成。*数据集指标:GlobalAccuracy意味着意思意味着Weirceediou含义___________________________ 0.97352 0.46416 0.46416 0.46416
有关评估语义分割网络的更多信息,请参见评估评估.
段新形象
读取并显示测试图像triangletest.jpg..
imgTest = imread ('triangletest.jpg');图imshow (imgTest)
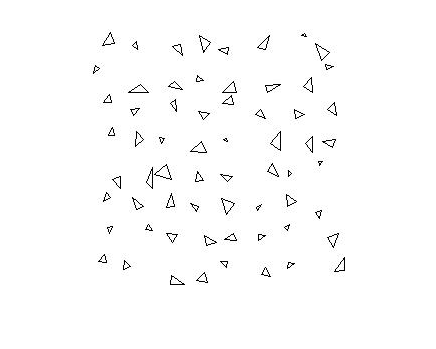
段使用测试图像semanticseg并使用显示结果Labeloverlay..
c = SemanticSeg(IMGTest,Net);B = Labeloverlay(IMGTEST,C);图imshow(b)

提示
这
PixellabeldAtastore.PXDS.和imageageAtastore.IMDS.按字典顺序存储位于文件夹中的文件。例如,如果您有12个文件名为'file1.jpg'那“file2.jpg”、……'file11.jpg','file12.jpg',则文件按以下顺序存储:存储在单元格数组中的文件被读取的顺序与存储的顺序相同。'file1.jpg'“file10.jpg”'file11.jpg''file12.jpg'“file2.jpg”'file3.jpg'...“file9.jpg”如果文件的顺序
PXDS.和IMDS.当您使用a读取地面真相和相应的标签数据时,您可能会遇到不匹配的不一样PixellabelimagedAtastore..如果出现这种情况,那么重命名像素标签文件,使它们具有正确的顺序。例如,重命名'file1.jpg'、……“file9.jpg”来'file01.jpg'、……'file09.jpg'.从a中提取语义分段数据
地面由此产生的对象贴标签机视频, 使用pixelLabelTrainingData函数。
你也可以从以下列表中选择一个网站:
