classifySound
在音频信号进行分类
语法
描述
(还返回一个表,其中包含结果的细节。听起来,时间戳,resultsTable)= classifySound (___)
classifySound (___)没有输出参数创建一个词云识别声音的音频信号。
这个函数需要音频工具箱™和深度学习工具箱™。
例子
下载classifySound
下载并解压缩音频工具箱™YAMNet支持。金宝app
如果音频工具箱支持YAMNet没有安装,然金宝app后第一次调用函数提供了一个链接到下载位置。下载模式,点击链接。将文件解压缩到一个位置在MATLAB的道路。
另外,执行以下命令来下载并解压缩YAMNet模型到你的临时目录中。
downloadFolder = fullfile (tempdir,“YAMNetDownload”);loc = websave (downloadFolder,“https://ssd.mathworks.com/金宝appsupportfiles/audio/yamnet.zip”);YAMNetLocation = tempdir;YAMNetLocation解压(loc)目录(fullfile (YAMNetLocation,“yamnet”))
识别颜色的噪音
产生1秒的粉红噪声假设16千赫采样率。
fs = 16 e3;x = pinknoise (fs);
调用classifySound粉红噪声信号和采样率。
identifiedSound = classifySound (x, fs)
identifiedSound =“粉红噪声”
及时识别和定位声音
读入一个音频信号。调用classifySound返回检测到声音和对应的时间戳。
[audioIn, fs] = audioread (“multipleSounds-16-16-mono-18secs.wav”);(声音、时间戳)= classifySound (audioIn fs);
画出音频信号和标签检测到声音的地区。
t =(0:元素个数(audioIn) 1) / fs;情节(t, audioIn)包含(“时间(s)”)轴([t(1),(结束),1,1])textHeight = 1.1;为idx = 1:元素个数(声音)补丁([时间戳(idx, 1),时间戳(idx, 1),时间戳(idx, 2),时间戳(idx, 2)),…(1,1,1,1),…(0.3010 0.7450 0.9330),…“FaceAlpha”,0.2);文本(时间戳(idx, 1), textHeight + 0.05 * (1) ^ idx,声音(idx))结束
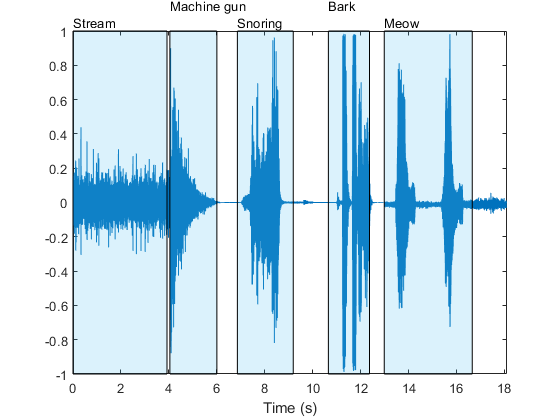
选择一个区域,只听选定的区域。
sampleStamps =地板(时间戳* fs) + 1;soundEvent =3;isolatedSoundEvent = audioIn (sampleStamps (soundEvent 1): sampleStamps (soundEvent 2));声音(isolatedSoundEvent, fs);显示器(“检测到声音= '+声音(soundEvent))

“检测到声音=打鼾”
只识别特定的声音
读入一个音频信号包含多个不同的声音事件。
[audioIn, fs] = audioread (“multipleSounds-16-16-mono-18secs.wav”);
调用classifySound音频信号和采样率。
(声音,~,soundTable) = classifySound (audioIn fs);
的听起来字符串数组包含在每个地区最有可能的声音事件。
听起来
听起来=1×5弦“流”“机关枪”“打鼾”“树皮”“喵喵”
的soundTable包含详细的信息在每个区域中发现,包括得分手段和分析信号最大值。
soundTable
soundTable =5×2表时间戳结果___________ ___________ 0 3.92}{4×3表4.0425 - 6.0025}{3×3表10.658 - 12.373 6.86 - 9.1875{表2×3}}{4×3表12.985 - 16.66{4×3表}
查看最后的检测区域。
soundTable.Results{结束}
ans =4×3表“动物”听起来AverageScores MaxScores ________________________ _________________ ____ 0.80243 - 0.99831 0.79514 - 0.99941“家畜、宠物”“猫”0.8048 - 0.99046 0.6342 - 0.90177“喵喵”
调用classifySound一次。这一次,IncludedSounds来动物这样的函数只保留区域动物声音检测到类。
(声音、时间戳、soundTable) = classifySound (audioIn fs,…“IncludedSounds”,“动物”);
听起来数组只返回指定为包含时发出的声音。的听起来现在包含的两个实例数组动物声明为相对应的区域树皮和猫叫之前。
听起来
听起来=1×2字符串“动物”“动物”
声表只包括地区指定的声音类检测。
soundTable
soundTable =2×2表时间戳结果___________ ___________ 12.985 - 16.66 10.658 - 12.373{4×3桌}{4×3表}
查看最后一个检测到的地区soundTable。结果表还包括统计在该地区的所有检测到的声音。
soundTable.Results{结束}
ans =4×3表“动物”听起来AverageScores MaxScores ________________________ _________________ ____ 0.80243 - 0.99831 0.79514 - 0.99941“家畜、宠物”“猫”0.8048 - 0.99046 0.6342 - 0.90177“喵喵”
探索这类支持的声音金宝appclassifySound,使用yamnetGraph。
排除特定的声音
读入一个音频信号和电话classifySound检查最可能听起来按时间顺序安排检测。
[audioIn, fs] = audioread (“multipleSounds-16-16-mono-18secs.wav”);听起来= classifySound (audioIn fs)
听起来=1×5弦“流”“机关枪”“打鼾”“树皮”“喵喵”
调用classifySound再次,ExcludedSounds来猫叫排除的声音猫叫从结果。以前分为部分猫叫现在是归类为猫,这是其前任AudioSet本体。
听起来= classifySound (audioIn fs,“ExcludedSounds”,“喵喵”)
听起来=1×5弦“流”“机关枪”“打鼾”“树皮”“猫”
调用classifySound再次,ExcludedSounds来猫。当你排除声音,所有的继任者也排除在外。这意味着扣除的声音猫也排除了声音猫叫。最初分为部分猫叫现在是归类为家畜、宠物,这是前任猫AudioSet本体。
听起来= classifySound (audioIn fs,“ExcludedSounds”,“猫”)
听起来=1×5弦“流”“机关枪”“打鼾”“树皮”“家畜、宠物”
调用classifySound再次,ExcludedSounds来家畜、宠物。声音类,家畜、宠物是前任两个树皮和猫叫,所以排除,先前确定的声音树皮和猫叫现在都是确定为的前身吗家畜、宠物,这是动物。
听起来= classifySound (audioIn fs,“ExcludedSounds”,“国内的动物,宠物”)
听起来=1×5弦“流”“机关枪”“打鼾”“动物”“动物”
调用classifySound再次,ExcludedSounds来动物。声音类动物没有前辈。
听起来= classifySound (audioIn fs,“ExcludedSounds”,“动物”)
听起来=1×3的字符串“流”“机关枪”“打鼾”
如果你想避免检测猫叫和它的前辈,但继续检测的继任者在同样的前辈,使用IncludedSounds选择。调用yamnetGraph所有支持的类的列表。金宝app删除猫叫和它的前辈从数组中所有的类,然后调用classifySound一次。
(~、类)= yamnetGraph;classesToInclude = setxor(类,“喵喵”,“猫”,“国内的动物,宠物”,“动物”]);听起来= classifySound (audioIn fs,“IncludedSounds”classesToInclude)
听起来=1×4弦“流”“机关枪”“打鼾”“树皮”
生成词云
读入一个音频信号,听它。
[audioIn, fs] = audioread (“multipleSounds-16-16-mono-18secs.wav”);声音(audioIn fs)
调用classifySound没有输出参数来生成一个词云检测的声音。
classifySound (audioIn fs);

修改默认的参数classifySound探讨影响“云”这个词。
阈值=0.1;minimumSoundSeparation =
0.92;minimumSoundDuration =
1.02;classifySound (audioIn fs,…“阈值”阈值,…“MinimumSoundSeparation”minimumSoundSeparation,…“MinimumSoundDuration”,minimumSoundDuration);




输入参数
输出参数
算法
的classifySound函数使用YAMNet分类音频段划分为类AudioSet本体所描述的声音。的classifySound函数进行预处理的音频,在YAMNet所需的格式和后处理YAMNet的预测与常见的任务,使结果更解释。
后处理
通过每个521信心的信号通过一个移动平均滤波器的窗口长度7。
的信号通过一个移动的中值滤波窗口长度为3。
信心的信号转换为二进制面具使用指定的
阈值。短于丢弃任何声音
MinimumSoundDuration。合并区域拉近
MinimumSoundSeparation。
巩固了良好的区域重叠50%以上为单一的地区。该地区开始时间是最小的开始时间的声音。该地区结束时间是最大的所有声音的结束时间。函数返回时间戳、声音类和均值和最大信心的声音类内的地区resultsTable。
你可以设置你的声音的特异性水平分类使用SpecificityLevel选择。例如,假设有四个声音类健康组与下列相应的平均成绩在声音地区:
水- - -0.82817流- - -0.81266细流,运球- - -0.23102倒- - -0.20732
声音类,水,流,细流,运球,倒位于AudioSet本体所表示的图:
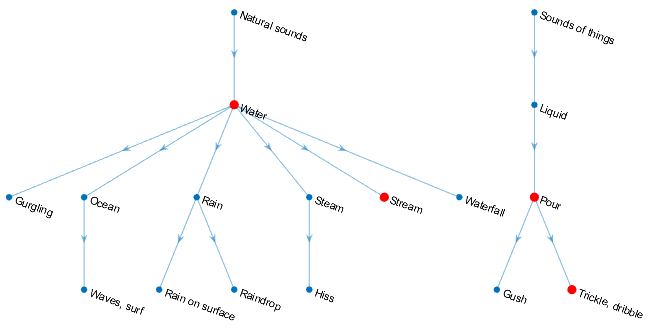
函数返回的声音类组的声音听起来输出参数依据SpecificityLevel:
“高”(默认),在这种模式下,流是首选水,细流,运球是首选倒。流对该地区平均评分更高,那么函数返回流在听起来输出为该地区。“低”,在这种模式下,声音类的最一般的本体论范畴的意思是最高的信心在返回该地区。为细流,运球和倒,最一般的类别声音的东西。为流和水,最一般的类别自然的声音。因为水意味着最高信心声音地区,函数返回自然的声音。“没有”——在这种模式下,函数返回的声音类意味着信心得分最高,而在这个例子中水。
引用
[1]Gemmeke, Jort F。,et al. “Audio Set: An Ontology and Human-Labeled Dataset for Audio Events.”2017年IEEE国际会议音响、演讲和信号处理(ICASSP)IEEE 2017,页776 - 80。DOI.org (Crossref),doi: 10.1109 / ICASSP.2017.7952261。
[2]好时,肖恩,et al。”CNN大规模的音频分类架构。”2017年IEEE国际会议音响、演讲和信号处理(ICASSP),2017岁的IEEE 131 - 35页。DOI.org (Crossref),doi: 10.1109 / ICASSP.2017.7952132。