编程拟合
MATLAB多项式模型的功能
两个matlab.®函数可以用多项式为数据建模。
多项式拟合功能
此示例显示如何使用多项式模拟数据。
衡量一个量y在几个时间的值T.。
t = [0 0.3 0.8 1.1 1.6 2.3];Y = [0.6 0.67 1.01 1.35 1.47 1.25];绘图(t,y,'o')标题('y与t'的情节)
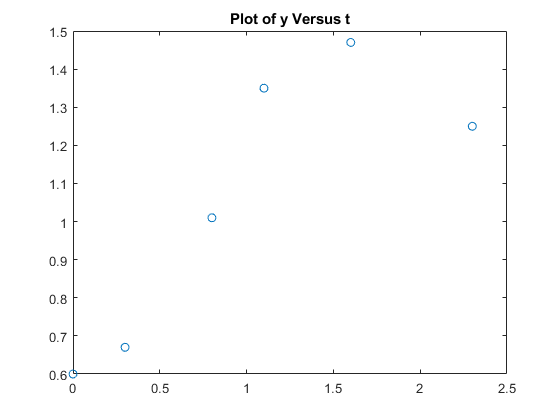
你可以尝试用二阶多项式函数来建模这些数据,
未知的系数, 那 , ,通过最小化数据偏离模型的平方和(最小二乘拟合)来计算。
使用Polyfit.求多项式系数。
p = polyfit (t, y, 2)
P =1×3.-0.2942 1.0231 0.4981
MATLAB计算下降功率的多项式系数。
该方程给出了数据的二次多项式模型
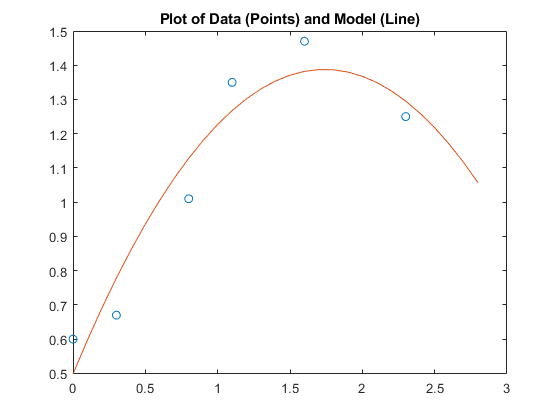
求均匀间隔时间的多项式,T2.。然后,在同一绘图上绘制原始数据和模型。
t2 = 0:0.1:2.8;y2 = polyval (p, t2);图绘制(t y'o', t2, y2)标题('数据(点)和型号(线)')
评估数据时间向量的模型
y2 = polyval (p、t);
计算残差。
res = y - y2;
绘制残差。
图,绘图(t,res,'+')标题('残留的情节')
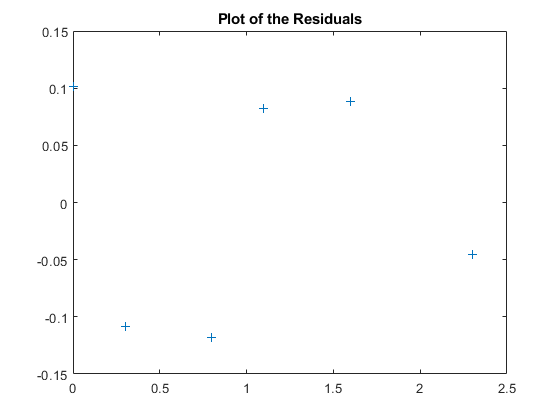
请注意,二级适合粗略遵循数据的基本形状,但不会捕获数据似乎撒谎的平滑曲线。似乎存在残差中的模式,这表明可能需要不同的模型。第五程度多项式(显示接下来)在数据的波动之后更好地做得更好。
重复练习,这次使用五度多项式Polyfit.。
p5 = polyfit(t,y,5)
p5 =1×6.0.7303 -3.5892 5.4281 -2.5175 0.5910 0.6000
评估多项式T2.并在新的数字窗口中的数据顶部绘制拟合。
Y3 = Polyval(P5,T2);图绘制(t y'o',t2,y3)标题('第五层多项式合适')

笔记
如果您试图为物理情况建模,那么考虑特定顺序的模型在您的情况下是否有意义总是很重要的。
带有非增值术语的线性模型
这个例子展示了如何用一个包含非多项式项的线性模型来拟合数据。
当多项式函数不能产生令人满意的数据模型时,可以尝试使用带有非多项式项的线性模型。例如,考虑下面的函数在参数中是线性的 那 , ,但是非线性 数据:
你可以计算未知的系数 那 , 通过构造和求解一组同时方程并解决参数。以下语法通过形成a而完成了这一点设计矩阵,其中每个列表示用于预测响应的变量(模型中的术语),并且每行对应于这些变量的一个观察。
进入T.和y作为列向量。
T = [0 0.3 0.8 1.1 1.6 2.3]';Y = [1];
形成设计矩阵。
X = [ones(size(t)) exp(-t) t.*exp(-t)];
计算模型系数。
a = x \ y
A =3×11.3983 -0.8860 0.3085
因此,数据的模型由
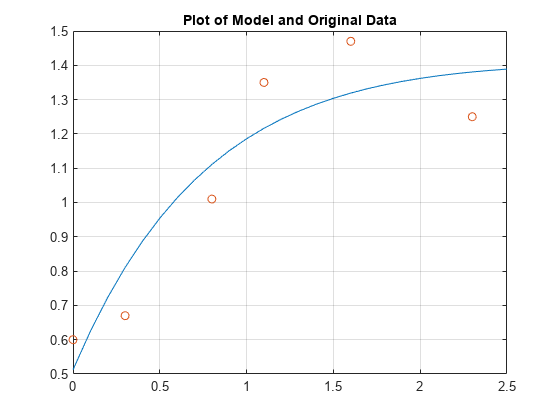
现在在规则间隔的点上评估模型,并使用原始数据绘制模型。
T =(0:0.1:2.5)”;exp(-T) *exp(-T) *a;情节(T Y' - '、t、y,'o'), 网格上标题(“模型与原始数据图”)
多元回归
此示例显示如何使用多元回归来模型数据,该数据是多于一个预测变量的函数。
当Y是一个以上的预测变量的函数时,必须扩展表达变量之间关系的矩阵方程以适应附加数据。这就是所谓的多重回归。
衡量一个量
对于几个值
和
。将这些值存储在vectors中X1那X2,y, 分别。
x1 =[。2。5.。6.。8.1。0.1。1]'; x2 = [.1 .3 .4 .9 1.1 1.4]'; y = [.17 .26 .28 .23 .27 .24]';
该数据的模型是这种形式的
多元回归解决未知系数 那 , 通过最小化来自模型(最小二乘拟合)的数据偏差的平方和。
通过形成设计矩阵,构造并求解联立方程组,X。
X = [ones(size(x1)) x1 x2];
使用反斜杠操作符解决参数。
a = x \ y
A =3×10.1018 0.4844 -0.2847
数据的最小二乘拟合模型是
为验证模型,求出数据与模型的偏差绝对值的最大值。
y = x * a;maxerr = max(abs(y - y))
MaxErr = 0.0038
该值比任何一个数据值都要小得多,说明该模型准确地遵循了数据。
编程拟合
这个例子展示了如何使用MATLAB函数:
中加载样本普查数据普氏.Mat.,其中包含来自1790年至1990年的美国人口数据。
加载普查
这将以下两个变量添加到MATLAB工作空间。
cdate是一个列向量,包含1790年到1990年,以10为增量。流行音乐美国人口数量对应的列向量在哪里cdate。
绘制数据。
情节(cdate、流行,'ro')标题(1790年至1990年的美国人口)
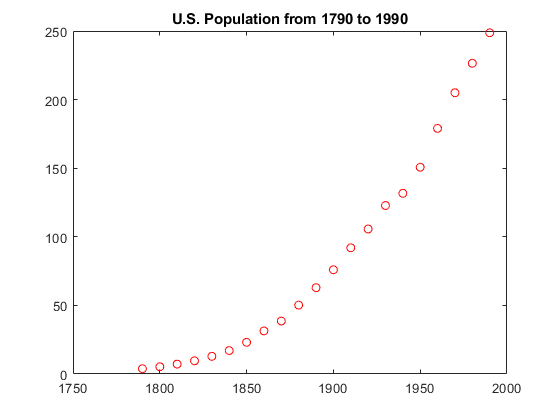
这幅图显示了一个很强的模式,这表明变量之间有很高的相关性。
计算相关系数
在该示例的这一部分中,您可以确定变量之间的统计相关性cdate和流行音乐致力于建模数据。有关相关系数的更多信息,请参阅线性相关。
计算相关系数矩阵。
corrcoef (cdate、流行)
ans =2×21.0000 0.9597 0.9597 1.0000
对角矩阵元素表示每个变量与自身的完全相关,等于1。非对角线元素非常接近于1,表明变量之间存在很强的统计相关性cdate和流行音乐。
拟合多项式数据
示例的这一部分应用Polyfit.和polyvalMATLAB函数以模拟数据。
计算适合参数。
[p,错误]= polyfit (cdate流行2);
评估契合。
pop_fit = polyval(p,cdate,收藏);
绘制数据和拟合。
绘图(CDate,Pop_fit,' - 'cdate流行,'+');标题(1790年至1990年的美国人口) 传奇('多项式模型'那“数据”那'地点'那'西北');Xlabel(“人口普查年”);ylabel(“人口(百万)”);

该曲线表明,二次多项式拟合提供给数据的良好近似。
计算适合的残差。
res = pop - pop_fit;图,情节(Cdate,Res,'+')标题(“二次多项式模型的残差”)

请注意,残差的曲线表现出一种模式,表明二级多项式可能不适合建模该数据。
情节并计算置信界限
信心范围是预测反应的置信区间。间隔的宽度表示拟合的确定性。
该示例的这部分适用Polyfit.和polyval到普查对二阶多项式模型的样本数据生成置信限。
以下代码使用间隔 ,对应于大样本的95%置信区间。
评估拟合和预测误差估计(delta)。
[pop_fitδ]= polyval (p cdate错误);
绘制数据、拟合和置信限。
情节(cdate、流行,'+'那......cdate pop_fit,'G-'那......Cdate,pop_fit + 2 *三角洲,“:”那......cdate、pop_fit-2 *δ“:”);Xlabel(“人口普查年”);ylabel(“人口(百万)”);标题('二次多项式适合置信度界限'网格)上

95%的间隔表明,您有95%的几率,新的观察将属于范围内。
你也可以从以下列表中选择一个网站:
