主要内容
histcounts2.
双变量直方图箱数计数
语法
描述
例子
输入参数
输出参数
N- 垃圾箱数目
大批
垃圾箱数,返回为数字数组。
中不同编号箱子的箱子包含方案N,以及它们相对于x-axis和Y- 是,是
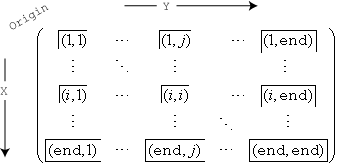
例如,(1,1)bin包括落在每个维度中的第一边缘的值,右下方的最后一个箱子包括落在其任何边缘的值。
xedges.-垃圾箱边缘x-尺寸
向量
bin边缘x-dimension,作为向量返回。Xedges(1)是第一个宾馆x-dimension和Xedges(结束)是最后一个箱子的边缘。
是的-垃圾箱边缘Y-尺寸
向量
bin边缘Y-dimension,作为向量返回。yedges(1)是第一个宾馆Y-dimension和yedges(结束)是最后一个箱子的边缘。
宾克斯- Bin指数x-尺寸
大批
Bin索引x-dimension,返回与尺寸相同的数字数组X.相应的元素宾克斯和平淡的描述编号的bin包含相应的值X和Y.价值0在里面宾克斯或者平淡的指示不属于任何存储箱的元素(例如楠价值)。
例如,宾克斯(1)和二进制(1)描述该值的存储箱位置[X(1),Y(1)].
平淡的- Bin指数Y-尺寸
大批
Bin索引Y-dimension,返回与尺寸相同的数字数组Y.相应的元素宾克斯和平淡的描述编号的bin包含相应的值X和Y.价值0在里面宾克斯或者平淡的指示不属于任何存储箱的元素(例如楠价值)。
例如,宾克斯(1)和二进制(1)描述该值的存储箱位置[X(1),Y(1)].
扩展能力
在R2015B中介绍
您还可以从以下列表中选择一个网站:
