非线性数据拟合
这个例子展示了如何使用几个Optimization Toolbox™算法将非线性函数拟合到数据中。
问题的设置
考虑以下数据:
Data =...[0.0000 5.8955 0.1000 3.5639 0.2000 2.5173 0.3000 1.9790 0.4000 1.8990 0.5000 1.3938 0.6000 1.1359 0.7000 1.0096 0.8000 1.0343 0.9000 0.8435 1.0000 0.6856 1.1000 0.6100 1.2000 0.5392 1.3000 0.3946 1.4000 0.3903 1.5000 0.5474 1.6000 0.3459 1.7000 0.1370 1.8000 0.2211 1.9000 0.1704 2.0000 0.2636];
我们把这些数据点画出来。
t =数据(:1);y =数据(:,2);%轴([0 2 -0.5 6])%抓住情节(t y“罗”)标题(的数据点)
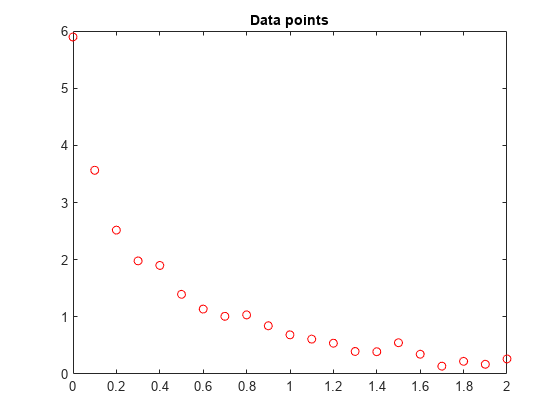
%推迟
我们想要符合这个函数
Y = c(1)*exp(-lam(1)*t) + c(2)*exp(-lam(2)*t)
的数据。
解决方案方法使用lsqcurvefit
的lsqcurvefit函数很容易解决这类问题。
首先,用一个变量x定义参数:
x (1) = c (1)
x (2) = lam (1)
x (3) = c (2)
林x (4) = (2)
然后将曲线定义为参数x和数据t的函数:
F = @ (x, xdata) x (1) * exp (- x (2) * xdata) + x (3) * exp (- x (4) * xdata);
我们任意设置初始点x0如下:c(1) = 1, lam(1) = 1, c(2) = 1, lam(2) = 0:
X0 = [1 1 1 0];
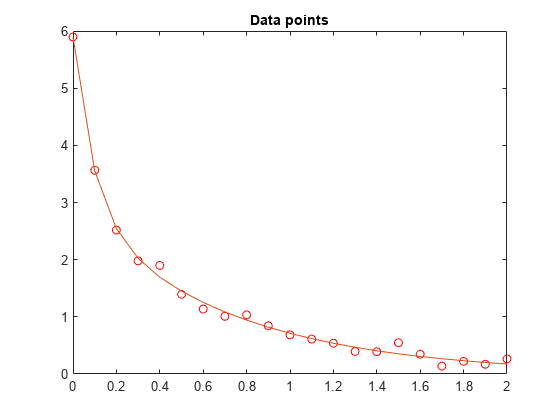
我们运行求解器并绘制出匹配结果。
[x, resnorm ~, exitflag,输出]= lsqcurvefit (F, x0、t、y)
局部最小值。Lsqcurvefit停止是因为相对于初始值的平方和的最终变化小于函数公差的值。
x =1×43.0068 10.5869 2.8891 1.4003
resnorm = 0.1477
exitflag = 3
输出=结构体字段:firstorderopt: 7.88522 -06 iterations: 6 funcCount: 35 cgiterations: 0 algorithm: 'trust-region-reflective' stepsize: 0.0096 message: '…'
持有在情节(t, F (x, t))从
解决方案方法使用fminunc
解决问题使用fminunc,我们设目标函数为残差平方和。
= @(x)sum((F(x,t) - y).^2);选择= optimoptions (“fminunc”,“算法”,“拟牛顿”);[xunc, ressquared eflag outputu] =...fminunc (x0, Fsumsquares选择)
局部最小值。由于梯度的大小小于最优性公差的值,优化完成。
xunc =1×42.8890 1.4003 3.0069 10.5862
ressquared = 0.1477
eflag = 1
outputu =结构体字段:firstderopt: 2.9662e-05 algorithm: '拟牛顿' message: '…'
请注意,fminunc找到了相同的解lsqcurvefit,但需要进行更多的函数计算。的参数fminunc和那些的顺序相反吗lsqcurvefit;较大的lam是lam(2),而不是lam(1)。这并不奇怪,变量的顺序是任意的。
流([“使用fminunc有%d次迭代,”...'和%d使用lsqcurvefit.\n'],...outputu.iterations output.iterations)
使用fminunc进行了30次迭代,使用lsqcurvefit进行了6次迭代。
流([“使用fminunc进行了%d函数计算,”...'和%d使用lsqcurvefit '],...outputu.funcCount output.funcCount)
使用fminunc进行了185次函数评估,使用lsqcurvefit进行了35次函数评估。
线性和非线性问题的分裂
请注意,拟合问题在参数c(1)和c(2)中是线性的。这意味着对于lam(1)和lam(2)的任意值,我们可以使用反斜杠运算符来找到c(1)和c(2)的值来解决最小二乘问题。
现在我们把这个问题重新做为一个二维问题,寻找lam(1)和lam(2)的最佳值。c(1)和c(2)的值在每一步使用上面描述的反斜杠操作符计算。
类型fitvector
function yEst = fitvector(lam,xdata,ydata) % fitvector DATDEMO用于返回拟合函数值。% yEst = FITVECTOR(lam,xdata)返回在参数设置为lam的数据点xdata处的拟合函数y %(定义如下)的值。% yes作为一个N乘1的列向量返回,其中N是%数据点的数量。% % FITVECTOR假设拟合函数y的形式为% % y = c(1)*exp(-lam(1)*t) +…+ c(n)*exp(-lam(n)*t) % %, n个线性参数c, n个非线性参数lam。为了求解线性参数c,我们构建一个矩阵a %,其中a的第j列是exp(-lam(j)*xdata) (xdata是一个向量)。然后我们求解线性最小二乘解c, %,其中ydata是y的观测值,A = 0 (length(xdata),length(lam));% build A matrix for j = 1:length(lam) A(:,j) = exp(-lam(j)*xdata);end c = A\ydata;%解A*c = y为线性参数c % return the estimated response based on c
使用方法解决问题lsqcurvefit,从二维初始点lam(1), lam(2)出发:
X02 = [1 0];F2 = @(x,t) fitvector(x,t,y);(x2, resnorm2, ~, exitflag2 output2] = lsqcurvefit (F2, x02 t y)
局部最小值。Lsqcurvefit停止是因为相对于初始值的平方和的最终变化小于函数公差的值。
x2 =1×210.5861 - 1.4003
resnorm2 = 0.1477
exitflag2 = 3
output2 =结构体字段:firstorderopt: 4.4018e-06 iterations: 10 funcCount: 33 cgiterations: 0 algorithm: 'trust-region- reflection ' stepsize: 0.0080 message: '…'
二维解的效率与四维解相似:
流([“使用2-d进行了%d函数计算”...'公式,%d使用4-d公式。'],...output2.funcCount output.funcCount)
使用二维配方进行了33项功能评估,使用4d配方进行了35项功能评估。
分割问题比初始猜想更健壮
为原来的四参数问题选择一个错误的起点会导致一个不是全局的局部解。对于分裂二参数问题,选择一个具有相同坏lam(1)和lam(2)值的起始点可以得到全局解。为了证明这一点,我们重新运行初始问题,初始问题会导致一个相对较差的局部解决方案,并将结果与全局解决方案进行比较。
X0bad = [5 1 1 0];[xbad, resnormbad, ~, exitflagbad outputbad] =...lsqcurvefit (F, x0bad t y)
局部最小值。Lsqcurvefit停止是因为相对于初始值的平方和的最终变化小于函数公差的值。
xbad =1×4-22.9036 2.4792 28.0273 2.4791
resnormbad = 2.2173
exitflagbad = 3
outputbad =结构体字段:firstorderopt: 0.0057 iterations: 32 funcCount: 165 cgiterations: 0 algorithm: 'trust-region- reflection ' stepsize: 0.0021 message: '…'
持有在情节(t、F (xbad t),‘g’)传说(“数据”,“全球健康”,“坏当地合适的,“位置”,“不”)举行从
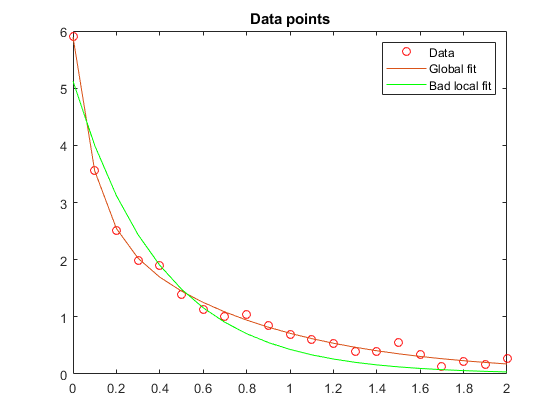
流(["好的结束点的剩余标准是%f "...'而在坏的结束点的剩余标准是%f '],...resnorm resnormbad)
好的结束点残差范数为0.147723,坏的结束点残差范数为2.217300。
相关的话题
你也可以从以下列表中选择一个网站:
