测量GPU性能
这个例子展示了如何测量GPU的一些关键性能特征。
GPU可用于加快某些类型的计算。然而,GPU性能在不同的GPU设备之间差异很大。为了量化GPU的性能,使用了三个测试:
数据发送到GPU或从它读取的速度有多快?
GPU内核读写数据有多快?
GPU如何快速执行计算?
在测量这些后,GPU的性能可以与主机CPU进行比较。这提供了一个指南,即GPU需要多少数据或计算才能提供优于CPU的优势。
设置
gpu = gpudevice();fprintf('使用%s gpu。\ n', gpu.Name) sizeOfDouble = 8;%每个双精度数需要8字节的存储空间大小=功率(2,14:28);
使用Tesla K40C GPU。
测试主机/ GPU带宽
第一个测试估计了数据发送到GPU和从GPU读取的速度。因为GPU是插到PCI总线上的,这在很大程度上取决于PCI总线有多快以及有多少其他东西在使用它。然而,度量中也包含一些开销,特别是函数调用开销和数组分配时间。因为它们存在于GPU的任何“现实世界”使用中,所以包含它们是合理的。
在以下测试中,分配内存并使用数据发送到GPUGPUArray.函数。内存被分配,数据被传输回主机内存使用收集。
请注意,PCI Express V3,如本测试所用,每巷具有0.99gb / s的理论带宽。对于NVIDIA的计算卡使用的16车道插槽(PCIe3 X16),这给出了理论为15.75GB / s。
sendtimes = Inf(尺寸(大小));收集时间= INF(尺寸(大小));为了II = 1:NUMER(大小)NUMELEMENTS =尺寸(ii)/ sizeofdouble;hostdata = randi([0 9],numElements,1);GPudata = RANDI([0 9],numElements,1,“gpuArray”);%时间发送给GPUsendfcn = @()gpuarray(hostdata);sendtimes(ii)= gputimeit(sendfcn);%从GPU收集回来的时间gatherFcn = @()收集(gpuData);gatherTimes (ii) = gputimeit (gatherFcn);结尾sendBandwidth = (sizes. / sendTimes) / 1 e9;[maxSendBandwidth, maxSendIdx] = max (sendBandwidth);fprintf('实现高峰发送速度%g gb / s \ n',maxsendbandwidth)GatherBandWidth =(大小./gathertimes)/ 1E9;[maxgatherbandwidth,maxgatheridx] = max(gatherbandwidth);fprintf('实现峰值收集速度%g gb / s \ n'马克斯(gatherBandwidth))
实现峰值发送速度6.18519 GB/s实现峰值采集速度3.31891 GB/s
在下面的图中,每个案例的峰值是圆圈的。具有小型数据集大小,开销占主导地位。具有较大量的数据PCI总线是限制因素。
抓住从semilogx(大小、sendBandwidth“b -”、大小、gatherBandwidth' r . - ')举行在semilogx(大小(maxsendidx),maxsendbandwidth,“bo - - - - - -”那“MarkerSize”10);maxGatherBandwidth semilogx(大小(maxGatherIdx),“ro - - - - - -”那“MarkerSize”10);网格在标题(的数据传输带宽)包含(的数组大小(字节)) ylabel (传输速度(GB / s)的) 传奇('发送给GPU'那'从GPU聚集'那'地点'那'西北')

测试内存密集型操作
许多操作与阵列的每个元素进行了很少的计算,因此在从存储器中获取数据或将其写回来的时间主导。函数如那些那Zeros.那南那真正的只写出它们的输出,而且函数就像翻倒那Til.读和写,但不做计算。即使是简单的操作符+那减那m每个元素的计算很少,它们仅被内存访问速度绑定。
这个函数+对每个浮点操作执行一次内存读和一次内存写。因此,它应该受到内存访问速度的限制,并提供一个良好的读写操作的速度指标。
MemoryTimesGPU = INF(大小(大小));为了II = 1:NUMER(大小)NUMELEMENTS =尺寸(ii)/ sizeofdouble;GPudata = RANDI([0 9],numElements,1,“gpuArray”);plusfcn = @()加(gpudata,1.0);MemoryTimesGPU(ii)= gputimeit(plusfcn);结尾memoryBandwidthGPU = 2 * (sizes. / memoryTimesGPU) / 1 e9;[maxxbwgpu, maxxbwidxgpu] = max(memoryBandwidthGPU);fprintf(在GPU上实现的峰值读写速度:%g GB/s\nmaxBWGPU)
在GPU上实现高峰读+写速度:186.494 GB / s
现在将其与CPU上运行的相同代码进行比较。
memoryTimesHost =正(大小(尺寸));为了II = 1:NUMER(大小)NUMELEMENTS =尺寸(ii)/ sizeofdouble;hostdata = randi([0 9],numElements,1);plusfcn = @()加(hostdata,1.0);MemoryTimeshost(ii)= timeit(plusfcn);结尾memoryBandwidthHost = 2 * (sizes. / memoryTimesHost) / 1 e9;[maxxbwhost, maxxbwidxhost] = max(memoryBandwidthHost);fprintf(主机上达到的峰值读写速度:%g GB/s\nmaxBWHost)%绘制CPU和GPU结果。抓住从semilogx(大小、memoryBandwidthGPU“b -”那......大小,记忆带宽,' r . - ')举行在semilogx(大小(maxbwidxgpu),maxbwgpu,“bo - - - - - -”那“MarkerSize”10);semilogx(大小(maxbwidxhost),maxbhost,“ro - - - - - -”那“MarkerSize”10);网格在标题(“阅读+写作带宽”)包含(的数组大小(字节)) ylabel ('速度(gb / s)') 传奇(“图形”那“主机”那'地点'那'西北')
主机读写速度峰值:40.2573 GB/s

将此绘图与上面的数据传输图进行比较,显然GPU通常可以从中读取并写入它们的存储器,而不是从主机获取数据。因此,重要的是最小化Host-GPU或GPU-Host Memory转移的数量。理想情况下,程序应将数据传输到GPU,然后在GPU上尽可能多地与其一起进行,并在完成时将其带回主机。甚至更好地是创建GPU上的数据以开始。
测试计算密集型操作
对于从内存读取或写入每个元素所执行的浮点计算数量较高的操作,内存速度就不那么重要了。在这种情况下,浮点单元的数量和速度是限制因素。这些操作被称为具有很高的“计算密度”。
对计算性能的良好测试是矩阵矩阵乘法。用于乘以二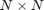 矩阵的浮点运算总数为
矩阵的浮点运算总数为
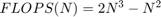 。
。
读取两个输入矩阵,写出一个结果矩阵,总共是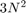 元素读取或写入。这给出了一个计算密度
元素读取或写入。这给出了一个计算密度(2N - 1)/ 3失败/元素。与之形成对比的是,+如上所述,其计算密度为1/2失败/元素。
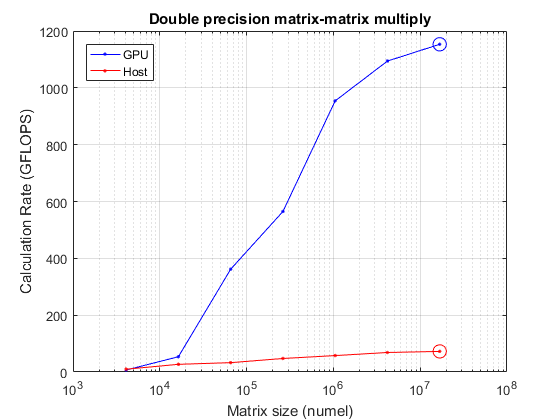
尺寸=功率(2,12:2:24);N = sqrt(大小);mmTimesHost =正(大小(尺寸));mmTimesGPU =正(大小(尺寸));为了II = 1:数量(尺寸)%首先在主机上执行它A = rand(N(ii), N(ii));B = rand(N(ii), N(ii));mmTimesHost(ii) = timeit(@() A*B);%现在在GPU上a = gpuarray(a);B = GPUARRAY(B);mmtimesgpu(ii)= gputimeit(@()a * b);结尾mmGFlopsHost = (2 * N。^ 3 - n ^ 2)。/ mmTimesHost / 1 e9;[maxGFlopsHost, maxGFlopsHostIdx] = max (mmGFlopsHost);mmGFlopsGPU = (2 * N。^ 3 - n ^ 2)。/ mmTimesGPU / 1 e9;[maxGFlopsGPU, maxGFlopsGPUIdx] = max (mmGFlopsGPU);流(['实现了'峰值计算率'那......'%1.1f GFLOPS(主机),%1.1f GFLOPS (GPU)\n'),......Maxgflopshost,MaxGFlockGPU)
实现72.5 GFLOPS(主机),1153.3 GFLOPS(GPU)的峰值计算率
现在请看它来看看达到达到达到的位置。
抓住从semilogx(大小、mmGFlopsGPU“b -”、大小、mmGFlopsHost' r . - ')举行在maxGFlopsGPU semilogx(大小(maxGFlopsGPUIdx),“bo - - - - - -”那“MarkerSize”10);semilogx(大小(maxgflopshostidx),maxgflopshost,“ro - - - - - -”那“MarkerSize”10);网格在标题('双重精确矩阵 - 矩阵乘以')包含(的矩阵大小(元素个数)) ylabel ('计算率(gflops)') 传奇(“图形”那“主机”那'地点'那'西北')
结论
这些测试揭示了GPU性能的一些重要特征:
从主机存储到GPU内存和后面的转移相对较慢。
良好的GPU可以比主机CPU读取/写入它的内存更快地读取/写入它的内存。
给定足够大的数据,GPU可以比主机CPU更快地执行计算。
值得注意的是,在每个测试中,无论是记忆还是通过计算限制,都需要完全饱和GPU。GPU立即使用数百万元素时提供最大的优势。
更多详细的GPU基准测试,包括不同GPU之间的比较,请参见GPUBench在MATLAB®中央文件交换。
你也可以从以下列表中选择一个网站: