使用文本文件中的数据文件集合数据存储
在预测维护算法设计中,您通常以纯文本格式具有系统数据,例如逗号分隔值(CSV)。此示例显示了如何创建和使用afillensembledataStore.对象以管理以这种格式存储的数据的集合。
合并数据
提取示例的压缩数据。
解压缩fleetdata.zip.zip.%提取压缩文件
该集合由十个文件组成,fleetdata_01.txt,...,fleetdata_10.txt,每个都包含一辆汽车的一辆汽车的数据。每个文件包含五列数据列,对应于以下值的每日读数:
里程表读数在一天结束时,以英里为单位
那天消耗的燃料,在加仑
当天的最大RPM
最大的发动机温度当天,中摄氏度
发动机灯状态在一天结束时(0 = OFF,1 = ON)
每个文件包含约80到大约120天的操作。为该示例进行了人工制造的数据集,并且不对应于真实的舰队数据。
配置合奏数据存储
创建一个fillensembledataStore.对象管理数据。
位置= PWD;延伸='。文本文件';fensemble = filecenembledataStore(位置,扩展);
配置集合数据存储才能使用提供的功能readfleetdata.m.从文件中读取数据。
AddPath(FullFile(MatlaBroot,'例子'那'predmaint'那'主要的')))%确保函数在路径上fensemble.readfcn = @readfleetdata;
因为数据文件中的列未标记,所以功能readfleetdata.将预定义的标签附加到相应的数据。配置集合数据变量以匹配定义的标签readfleetdata.。
fensemble.datavariables = [“里程表”;“燃料consump”;“maxrpm”;“maxtemp”;“Enginelight”];
功能readfleetdata.另外解析文件名以返回收集数据的汽车的ID,从1到10中的数字。此ID是集合独立变量。
fensemble.independentvariables =“ID”;
根据所选变量指定所有数据变量和独立变量,以便从合并数据存储中读取。
fensemble.selectedvariables = [fensemble.indepentvariables; fensemble.datavariables];fensemble.
fensemble = fileCleeMbledataStastore具有属性:readfcn:@readfleetdata writetomemberfcn:[] datavariables:[5x1字符串]独立variables:“id”条件variables:[0x0字符串]选择variables:[6x1字符串] readsize:1 nummembers:10 lastmemberread:[0x0字符串]文件:[10x1字符串]
阅读集合数据
你打电话的时候读在集合数据存储上,它使用readfleetdata.从第一集合成员读取所选变量。
data1 =读取(fensemble)
data1 =1×6表ID Idometer CuerConsump Maxrpm Maxtemp Enginelight _________________ _________________ _________________ _________________ 1 {120x1时间表} {120x1时间表} {120x1时间表} {120x1时间表}
检查和绘制里程表数据。
ODO1 = data1.odometer {1}
ODO1 =120×1时间表Time Var1 _______ ______ 0天180.04 1天266.76 2天396.01 3天535.19 4天574.31 5天714.82 6天714.82 7天821.44 8天1030.5 9天1213.4 10天1303.4 11天1513.5 13天1513.5 13天1513.5 13天1513.5 13天1513.5 13天1513.5 13天1513.5天1804.6天
绘图(ODO1.Time,ODO1.var1)
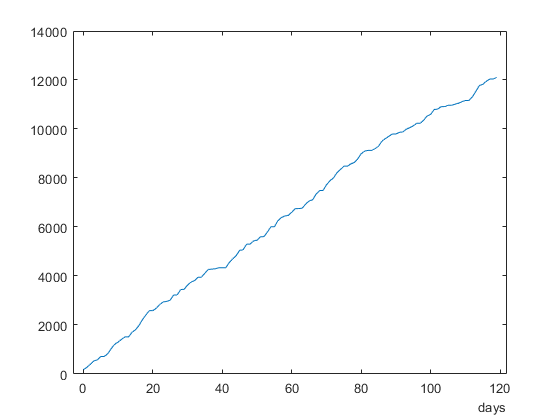
计算该成员的平均气体里程。这个值是最后一天的里程表读数,除以所消耗的总燃料。
Culconsump1 = data1.fuelconsump {1} .var1;totalconsump1 = sum(燃料consump1);TotalMiles1 = ODO1.VAR1(END);MPG1 = TotalMiles1 / TotalConsump1
MPG1 = 22.3086.
来自所有集合成员的批处理数据
如果你打电话读再次,它读取来自下一个集合成员的数据并提前莱特曼弗雷德财产fensemble.反映该合奏的文件名。您可以重复处理步骤以计算该成员的平均气体里程。在实践中,可以自动化读取和处理数据的过程更有用。为此,将集合数据存储重置为未读取数据的状态。然后循环通过集合并为每个成员执行读取和处理步骤,返回包含每辆汽车ID和平均气体里程的表。(如果您有并行计算工具箱™,则可以使用它来加快更大数据集合的处理。)
重置(fensemble)mpgdata = zeros(10,2);10个集合成员的%preallocate阵列ct = 1;尽管hasdata(fensemble)数据=读取(fensemble);odo = data.odometer {1} .var1;uculconsump = data.fuelconsump {1} .var1;totalconsump = sum(燃料consump);MPG = ODO(END)/ TOILCONSUMP1;id = data.id;MPGDATA(CT,:) = [ID,MPG];CT = CT + 1;结尾mpgtable = array2table(mpgdata,'variablenames',{'ID'那'mpg'})
mpgtable =10×2表ID MPG ________1 22.309 2 19.327 3 20.816 4 27.464 5 18.848 6 22.517 7 27.018 8 27.284 9 17.149 10 26.37
也可以看看
相关话题
您还可以从以下列表中选择一个网站:
