风电机组高速轴承预测
这个例子展示了如何建立一个指数退化模型来实时预测风力发电机轴承的剩余使用寿命(RUL)。指数退化模型根据其参数先验值和最新的测量值(历史运行到故障的数据可以帮助估计模型参数先验值,但它们不是必需的)来预测RUL。该模型能够实时检测到明显的退化趋势,并在有新的观测结果时更新其参数先验。该实例遵循一个典型的预后工作流:数据导入和探索、特征提取和后处理、特征重要性排序和融合、模型拟合和预测以及性能分析。
数据集
数据集收集自一个2MW的风力涡轮机高速轴驱动的20齿小齿轮[1]。连续50天每天采集6秒的振动信号(3月17日有2次测量,在本例中为2天)。在50天的时间内,轴承发生了内圈故障,导致轴承失效。
该数据集的压缩版本是在工具箱中。要使用小型数据集,该数据集复制到当前文件夹,并启用其写权限。
拷贝文件(...fullfile (matlabroot“工具箱”,'predmaint',...“predmaintdemos”,'windTurbineHighSpeedBearingPrognosis'),...“WindTurbineHighSpeedBearingPrognosis-Data-master”)fileattrib(完整文件(“WindTurbineHighSpeedBearingPrognosis-Data-master”,‘* .mat‘),' + w ')
用于紧凑型数据集的测量时间步长为5天。
TIMEUNIT ='\乘以5一天;
对于完整的数据集,请转到这个链接https://github.com/mathworks/WindTurbineHighSpeedBearingPrognosis-Data,将整个存储库下载为zip文件,并将其保存在与此活动脚本相同的目录中。使用此命令解压缩文件。完整数据集的测量时间步长为1天。
如果存在(“WindTurbineHighSpeedBearingPrognosis-Data-master.zip”,“文件”)解压缩(“WindTurbineHighSpeedBearingPrognosis-Data-master.zip”)TIMEUNIT ='天';结束
在这个实施例的结果是从完整数据集生成的。强烈建议下载完整数据集来运行这个例子。从小型数据集生成的结果可能没有意义。
数据导入
创建一个fileEnsembleDatastore的风力涡轮机数据。数据中包含的振动信号和转速计信号。该fileEnsembleDatastore将解析文件名并提取日期信息为IndependentVariables。有关详细信息,请参阅与此示例关联的支持文件中的帮助函数。金宝app
hsbearing = fileEnsembleDatastore(...完整文件('',“WindTurbineHighSpeedBearingPrognosis-Data-master”),...“.mat”);hsbearing.DataVariables = [“振动”,“测速”];hsbearing。IndependentVariables =“日期”;hsbearing.SelectedVariables = [“日期”,“振动”,“测速”];hsbearing。ReadFcn = @helperReadData;hsbearing。WriteToMemberFcn = @helperWriteToHSBearing;高(hsbearing)
ANS = M×3高大表日期振动转速____________________ _________________ _______________ 07-MAR-2013 1点57分46秒[585936×1双] [2446×1双] 08-MAR-2013 2点34分21秒[585936×1双] [2411×1双] 09-MAR-2013 2时33分43秒[585936×1双] [2465×1双] 10-MAR-2013 3点01分02秒[585936×1双] [2461×1双] 11-MAR-2013 3点00分24秒[585936×1双] [2506×1双] 12-MAR-2013六时17分10秒[585936×1双] [2447×1双] 13-MAR-20136点34分04秒[585936×1双] [2438×1双] 14-MAR-2013 6时五十分41秒[585936×1双] [2390×1双]::::::
振动信号的采样速率为97656赫兹。
FS = 97656;%赫兹
数据发掘
本节将探索时域和频域的数据,并从中寻找对预后有帮助的特征。
首先将振动信号在时域可视化。在这个数据集中,连续50天有50个6秒的振动信号。现在把50个振动信号一个接一个地画出来。
复位(hsbearing)TSTART = 0;图保存在而hasdata(hsbearing) data = read(hsbearing);v = data.vibration {1};t = tstart +(1:长度(v))/fs;%下采样信号以减少存储器使用plot(t(1:10:end), v(1:10:end)) tstart = t(end);结束保持从xlabel(时间,每天6秒,总共50天)ylabel (“加速度(g)”)
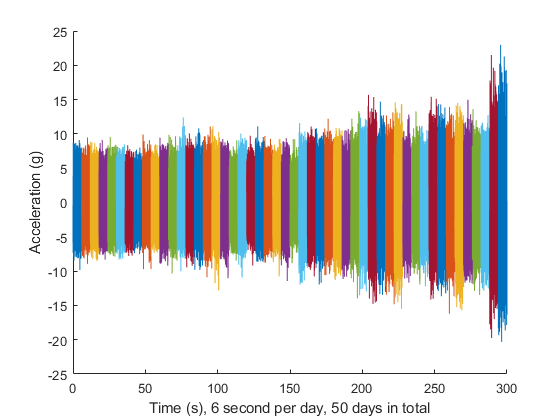
在时域上的振动信号揭示了信号冲动的增加趋势。指标量化信号的冲动,如峰度,峰 - 峰值,波峰因数等。,是该风力涡轮机承载数据集[2]的潜在预后特征。
在另一方面,光谱峰度被认为是在频域[3]风力涡轮机的预后有力工具。为了显现沿着时间的光谱峰度的变化,绘制光谱峰度值作为频率的函数和测量一天。
hsbearing.DataVariables = [“振动”,“测速”,“SpectralKurtosis”];颜色= parula (50);图保存在复位(hsbearing)天= 1;而hasdata(hsbearing) data = read(hsbearing);data2add =表;得到振动信号和测量数据v = data.vibration {1};%计算谱峰度与窗口大小= 128wc = 128;[SK, F] =峰度(v, fs, wc);data2add。{table(F, SK)};%绘制光谱峰度plot3(F,天*的人(大小(F)),SK,'颜色',颜色(天,:))写谱峰度值writeToLastMemberRead (hsbearing data2add);%增加天数天=天+ 1;结束保持从xlabel(的频率(赫兹))ylabel (“时间(天)”)zlabel (“谱峰态”)网格在视图(-45,30)CBAR =彩条;ylabel(CBAR,'故障严重性(0 - 健康的,1 - 故障)')
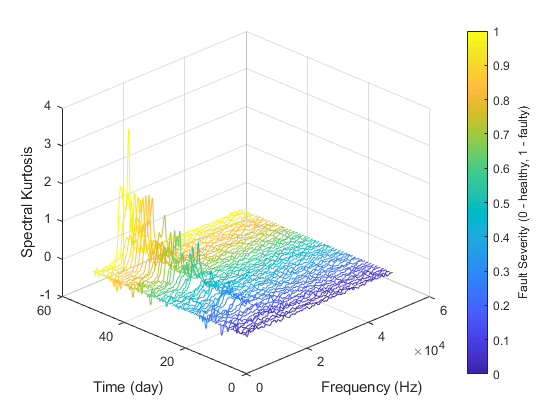
颜色栏中显示的故障严重程度是归一化为0到1刻度的测量数据。可以看出,随着机器状态的下降,10khz左右的谱峰度值逐渐增大。光谱峰度的统计特征,如均值、标准差等等。,将是轴承退化的潜在指标[3]。
特征提取
基于先前的部分中的分析,统计特征的集合从时域信号和频谱峭度将要被提取的。在[2-3]提供有关功能的更多数学细节。
首先,预先分配写他们进入fileEnsembleDatastore前DataVariables功能名称。
hsbearing.DataVariables = [hsbearing。DataVariables;...“意思”;“标准”;“偏斜”;“峰度”;“Peak2Peak”;...“RMS”;“CrestFactor”;“形状因子”;“ImpulseFactor”;“MarginFactor”;“能源”;...“SKMean”;“SKStd”;“SKSkewness”;“SKKurtosis”];
对于每个集合构件计算特征值。
hsbearing.SelectedVariables = [“振动”,“SpectralKurtosis”];重置(hsbearing)而hasdata(hsbearing) data = read(hsbearing);v = data.vibration {1};SK = data.SpectralKurtosis {1} .SK;特点=表;%时域特性features.Mean =平均值(V);features.Std = STD(V);features.Skewness =偏斜度(V);features.Kurtosis =峭度(V);features.Peak2Peak = peak2peak(V);features.RMS =有效值(V);features.CrestFactor = MAX(ⅴ)/features.RMS;features.ShapeFactor = features.RMS /平均值(ABS(V));features.ImpulseFactor = MAX(V)/平均值(ABS(V));features.MarginFactor = MAX(V)/平均值(ABS(V))^ 2; features.Energy = sum(v.^2);%光谱峰度相关特征特性。SKMean =意味着(SK);特性。SKStd =性病(SK);特性。SKSkewness =偏态(SK);特性。SKKurtosis =峰度(SK);%写导出的特征为相应的文件writeToLastMemberRead (hsbearing、特点);结束
选择自变量日期和所有提取的特征,构造特征表。
hsbearing.SelectedVariables = [“日期”,“意思”,“标准”,“偏斜”,“峰度”,“Peak2Peak”,...“RMS”,“CrestFactor”,“形状因子”,“ImpulseFactor”,“MarginFactor”,“能源”,...“SKMean”,“SKStd”,“SKSkewness”,“SKKurtosis”];
由于feature表足够小,可以放入内存(50 * 15),所以在处理之前要收集表。对于大数据,建议以高格式执行操作,直到您确信输出足够小,可以装入内存为止。
featureTable =聚集(高(hsbearing));
使用并行池“local”对tall表达式求值:- 1 / 1:1秒内完成求值,1秒内完成
将表格转换为时间表,这样的时间信息总是与特征值相关联。
featureTable = table2timetable (featureTable)
featureTable =50×15时间表日期的意思是性病偏态峰度Peak2Peak RMS CrestFactor ShapeFactor ImpulseFactor MarginFactor能源SKMean SKStd SKSkewness SKKurtosis ____________________ _________…………………………_________________ ________ ____ _______ __________ __________ ________ __________ __________ 07 - 3月- 2013 01:57:46 0.34605 2.2705 0.0038699 2.9956 21.621 2.2967 0.001253 4.9147 1.2535 6.1607 3.3625 3.0907 e + 06 - mar - 2013 02:34:21 08年0.025674 -0.22882 3.362 0.24409 2.06210.0030103 3.0195 19.31 2.0765 4.9129 1.2545 6.163 3.7231 2.5266 e + 06年0.0046823 0.020888 0.057651 3.3508 09 - 3月- 2013 02:33:43 0.21873 2.1036 -0.0010289 3.0224 21.474 2.1149 5.2143 1.2539 6.5384 3.8766 2.6208 e + 06 -0.0011084 0.022705 -0.50004 4.9953 10 - 3月- 2013年03:01:02 0.21372 2.0081 0.001477 3.0415 19.52 2.0194 5.286 1.2556 6.637 4.1266 2.3894 e + 06 0.0087035 0.034456 1.4705 8.1235 11 - 3月- 2013 03:00:24 0.21518 2.0606 0.0010116 3.0445 21.217 2.0718 5.0058 1.2554 6.2841 3.8078 2.515 0.013559 e + 060.032193 0.11355 3.848 12 - 3月- 2013年06:17:10 0.29335 2.0791 -0.008428 3.018 20.05 2.0997 4.7966 1.2537 6.0136 3.5907 2.5833 e + 06年0.0017539 0.028326 -0.1288 3.8072 13 - 3月- 2013 06:34:04 0.21293 1.972 -0.0014294 3.0174 18.837 1.9834 4.8496 1.2539 6.0808 3.8441 2.3051 e + 06 0.0039353 - 0.029292 -1.4734 - 8.1242 14 - 3月- 2013 06:50:41 0.24401 1.8114 0.0022161 3.0057 17.862 1.8278 4.8638 1.2536 6.0975 4.1821 1.9575 e + 06 15 - 3月- 2013 06:50:03 0.0013107 0.022468 0.27438 2.8597 0.20984 1.9973 0.001559 3.0711 - 21.120.0023769 2.0083 5.4323 1.2568 6.8272 4.2724 2.3633 e + 06 16 - 3月- 2013 06:56:43 0.047767 -2.5832 20.171 0.23318 1.9842 -0.0019594 3.0072 18.832 1.9979 5.0483 1.254 6.3304 3.9734 2.3387 e + 06年0.0076327 0.030418 0.52322 4.0082 17 - 3月- 2013 06:56:04 0.21657 2.113 -0.0013711 3.1247 21.858 2.1241 5.4857 1.2587 6.9048 4.0916 2.6437 e + 06年0.0084907 0.037876 2.3753 11.491 17 - 3月- 2013 18:47:56 0.19381 2.1335 -0.012744 3.0934 21.589 2.1423 4.7574 1.2575 5.9825 3.5117 2.6891 e + 06年0.019624 0.055537 3.1986 17.79618 - 3月- 2013年18:47:15 0.21919 2.1284 -0.0002039 3.1647 24.051 2.1396 5.7883 1.2595 7.2902 4.2914 2.6824 e + 20 - 3月- 2013年06 0.016315 0.064516 2.8735 11.632 00:33:54 0.35865 2.2536 -0.002308 3.0817 22.633 2.2819 0.0011097 5.2771 1.2571 6.6339 3.6546 3.0511 e + 06 21 - 3月- 2013 00:33:14 0.051539 -0.056774 7.0712 0.1908 2.1782 -0.00019286 3.1548 25.515 2.1865 6.0521 1.26 7.6258 4.3945 2.8013 0.0040392 e + 06 22 - 3月- 2013 00:39:50 0.066254 -0.39587 12.111 0.20569 2.1861 0.0020375 3.2691 26.439 2.1958 6.17531.2633 7.8011 4.4882 2.825 e + 06年0.020676 0.077728 2.6038 11.088⋮
特征后处理
提取的特征通常与噪音有关。具有相反趋势噪声有时可能是有害的RUL预测。此外,功能性能指标,单调性,接下来将要介绍的一个不抗噪能力。因此,因果移动平均滤波器具有5个步骤的滞后窗口施加到所提取的特征,其中“因果”是指没有未来值是在移动平均滤波中使用。
variableNames = featureTable.Properties.VariableNames;featureTableSmooth = varfun(@(X)movmean(X,[5 0]),featureTable);featureTableSmooth.Properties.VariableNames = variableNames;
这里是表示前和后平滑的特征的例子。
图保存在情节(featureTable。日期,featureTable.SKMean) plot(featureTableSmooth.Date, featureTableSmooth.SKMean) hold从xlabel('时间')ylabel (“特征值”)传说(“以前平滑”,“平滑后”)标题(“SKMean”)
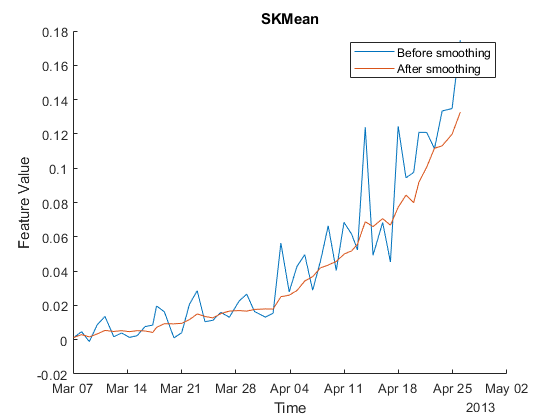
移动平均平滑引入了信号的时延,但在RUL预测中选择适当的阈值可以减小时延效应。
训练数据
在实践中,在开发预测算法时无法获得整个生命周期的数据,但有理由假设已经收集了生命周期早期阶段的一些数据。因此,前20天(生命周期的40%)收集的数据被视为培训数据。下面的特征重要性排序和融合只是基于训练数据。
课间=日期时间(2013,3,27);断点=查找(featureTableSmooth.Date <课间,1,'持续');trainData = featureTableSmooth(1:断点,:);
功能重要性排序
在本例中,我们使用[3]提出的单调性来量化这些特征的优点,以达到预测的目的。
的单调性 个特征 被计算为
在哪里 是测量点的数量,在这种情况下 。 在机器的数量监测,在这种情况下, 。 是 测量到的特征 机。 ,即信号的差值 。
%与移动窗口平滑已经完成,集“WindowSize”为0,关闭函数内的平滑featureImportance =单调性(trainData,'WindowSize',0);helperSortedBarPlot (featureImportance“单调”);

该信号的峰度是基于单调顶部的特征。
下一节选取特征重要度评分大于0.3的特征进行特征融合。
traindatasselected = trainData(:, featureImportance{:,::}>0.3);featureSelected = featureTableSmooth(:, featureImportance{:,:}>0.3)
featureSelected =50×5时间表日期的意思是峰度ShapeFactor MarginFactor SKStd ____________________ _________ _______ ________ ________ ___________ 07 - 3月- 2013 01:57:46 08年0.34605 2.9956 1.2535 3.3625 0.025674 - 3月- 2013 02:34:21 0.29507 3.0075 1.254 3.5428 0.023281 09 - 3月- 2013 02:33:43 0.26962 3.0125 1.254 3.6541 0.023089 10 - 3月- 2013年11 03:01:02 0.25565 3.0197 1.2544 3.7722 0.025931 - 3月- 2013 03:00:24 0.24756 3.0247 1.2546 3.7793 0.027183 3月12 - 13 - 2013 06:17:10 0.25519 3.0236 1.2544 3.7479 0.027374 0.233 - 3月- 2013 06:34:043.0272 1.2545 3.8282 0.027977 14-Mar-2013 06:50:41 0.23299 3.0249 1.2544 3.9047 0.02824 15-Mar-2013 06:50:03 0.2315 3.033 1.2548 3.9706 0.032417 16-Mar-2013 06:56:43 0.23475 3.0273 1.2546 3.9451 0.031744 17-Mar-2013 06:56:04 0.23498 3.0407 1.2551 3.9924 0.032691 17-Mar-2013 18:47:56 0.21839 3.0533 1.2557 3.9792 0.037226 18-Mar-2013 18:47:15 0.21943 3.0778 1.2567 4.0538 0.043097 20-Mar-2013 00:33:54 0.23854 3.0905 1.2573 3.9658 0.047942 21-Mar-2013 00:33:14 0.23537 3.1044 1.2578 3.9862 0.051023 22-Mar-2013 00:39:50 0.23079 3.1481 1.2593 4.072 0.058908 ⋮
降维与特征融合
本例采用主成分分析方法进行降维和特征融合。在执行PCA之前,最好将特征归一化到相同的范围内。注意,PCA系数和归一化中使用的均值和标准差是从训练数据中获得的,并应用于整个数据集。
meanTrain =意味着(trainDataSelected {:,:});sdTrain =性病(trainDataSelected {:,:});trainDataNormalized = (traindatasselected {:,:} - meanTrain)./sdTrain;系数= pca (trainDataNormalized);
的平均值,标准偏差和PCA系数被用于处理整个数据集。
PCA1 =(featureSelected {:,:} - meanTrain)./ sdTrain * COEF(:,1);PCA2 =(featureSelected {:,:} - meanTrain)./ sdTrain * COEF(:,2);
在前两个主成分的空间中可视化数据。
figure numData = size(featureTable, 1);scatter(PCA1, PCA2, [], 1:numData,'填充')包含(“PCA 1”)ylabel (《PCA 2》)CBAR =彩条;ylabel(CBAR,[“时间”timeUnit')'])

该图表明,随着机器接近失败第一主成分正在增加。因此,第一主成分是一种很有前途稠健康指示符。
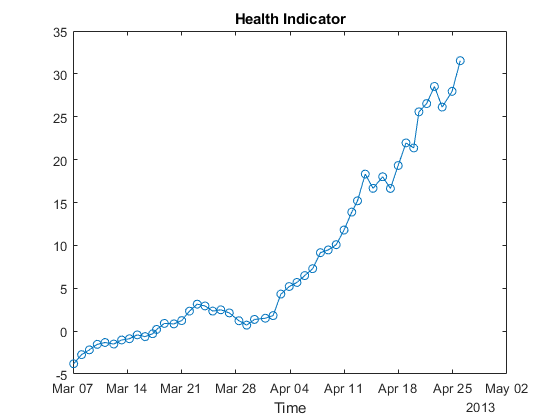
healthIndicator = PCA1;
将健康指标形象化。
图图(featureSelected.Date,healthIndicator,“o”)包含('时间')标题(“健康指标”)
为剩余使用寿命(RUL)估计拟合指数退化模型
指数衰减模型被定义为
在哪里 是时间的函数的健康指标。 是被认为是常数的截距项。 和 是确定所述模型,其中的斜率随机参数 是对数分布和 是系统。在每个时间步长 ,分布 和 更新为基础的最新观测后 。 高斯白噪声是否屈服于 。该 在指数项作出的预期 满足
。
这里的指数退化模型适合于在最后一节中提取的健康指标,演出将在下一节进行评估。
因此,它从0开始,首先转移的健康指标。
healthIndicator = healthIndicator - healthIndicator(1);
阈值的选择通常基于机器的历史记录或一些特定领域的知识。由于该数据集中没有可用的历史数据,因此选择health指示器的最后一个值作为阈值。建议根据平滑(历史)数据选择阈值,这样可以部分缓解平滑的延迟效应。
阈值= healthIndicator(端);
如果历史数据是可用的,使用适合提供的方法exponentialDegradationModel估计先验和截距。然而,历史数据是无法用于此风力涡轮机轴承的数据集。现有斜率参数的被选择任意大方差(
),因此该模型主要依赖于观测数据。基于
,拦截
被设定为
所以模型也会从0开始。
健康指标的变化与噪声变化之间的关系可以推导为
这里假设噪声的标准差在接近阈值时引起健康指标10%的变化。因此,噪声的标准差可以表示为 。
指数衰减模型还提供了一个功能,以评估斜坡的意义。一旦检测到健康指示器的显著斜率,该模型会忘记以前的意见,然后重新启动在原有基础上先验估计。检测算法的灵敏度可以通过指定被调谐SlopeDetectionLevel。如果p值小于SlopeDetectionLevel,则表示斜坡已被探测。在这里SlopeDetectionLevel设置为0.05。
现在用上面讨论的参数创建一个指数退化模型。
MDL = exponentialDegradationModel(...“西塔”,1...'ThetaVariance',1E6,...“β”,1...'BetaVariance',1E6,...“披”,-1,...'NoiseVariance',(0。1*阈值/(阈值+ 1))^2,...'SlopeDetectionLevel',0.05);
使用predictRUL和更新方法来预测的RUL和实时更新的参数分布。
在每次迭代中保持记录totalDay =长度(healthIndicator) - 1;estRULs =零(totalDay,1);trueRULs =零(totalDay,1);CIRULs =零(totalDay,2);pdfRULs =细胞(totalDay,1);为情节的更新创建图形和轴图ax1 = subplot(2,1,1);ax2 = subplot(2,1,2);为CURRENTDAY = 1:totalDay%更新模型参数后验分布更新(mdl [currentDay healthIndicator (currentDay)))%预测剩余使用寿命[estRUL, CIRUL, pdfRUL] = predictRUL(mdl,...[currentDay healthIndicator (currentDay)),...阈值);trueRUL = totalDay - currentDay + 1;%更新RUL分布图helperPlotTrend(ax1, currentDay, healthIndicator, mdl, threshold, timeUnit);helperPlotRUL(ax2, trueRUL, estRUL, CIRUL, pdfRUL, timeUnit)%保持预测结果estRULs(CURRENTDAY)= estRUL;trueRULs(CURRENTDAY)= trueRUL;CIRULs(CURRENTDAY,:) = CIRUL;pdfRULs {CURRENTDAY} = pdfRUL;%暂停0.1秒至使动画可见暂停(0.1)结束
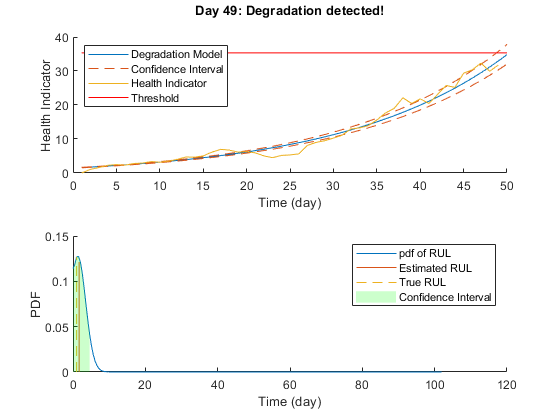
下面是实时RUL估计的动画。
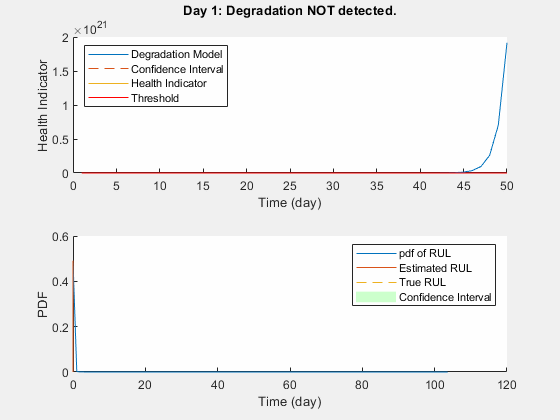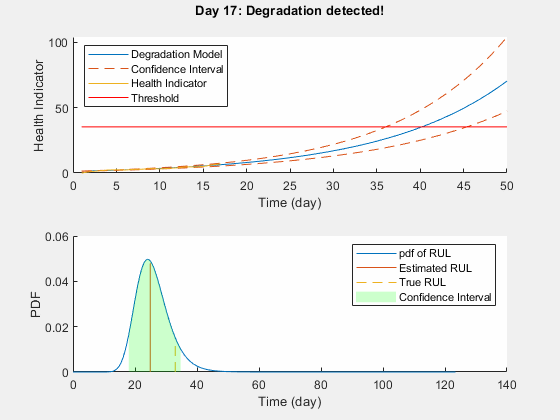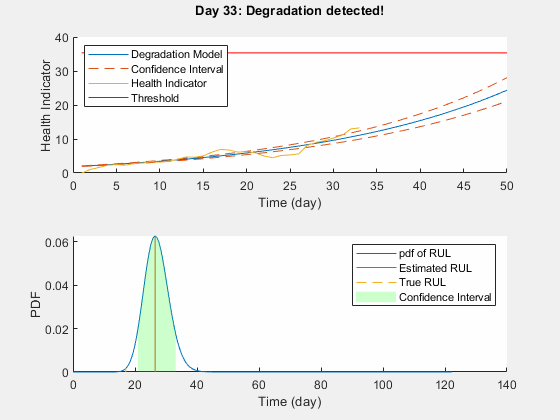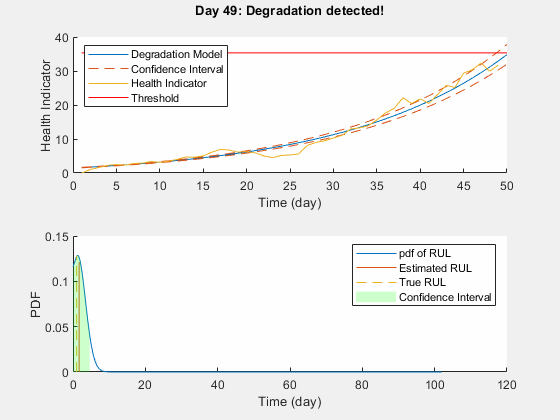
性能分析
- plot用于预后性能分析[5],其中 绑定设置为20%。估计的RUL在。之间的概率 真正的RUL的约束计算为模型的性能指标:
在哪里 是所估计的RUL在时间 , 是真正的RUL在时间 , 估计的模型参数是在什么时候
α= 0.2;detectTime = mdl.SlopeDetectionInstant;b = helperAlphaLambdaPlot(α、trueRULs、estRULs、CIRULs、...pdfRULs,检测时间,断点,时间单位);标题(“\α-\拉姆达块”)
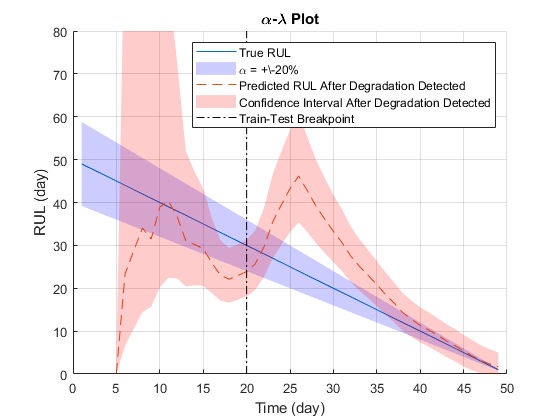
由于预设之前并不反映真实之前,该模型通常需要一些时间步长调整到一个适当的参数分布。预测随着更多的数据点都可以更准确。
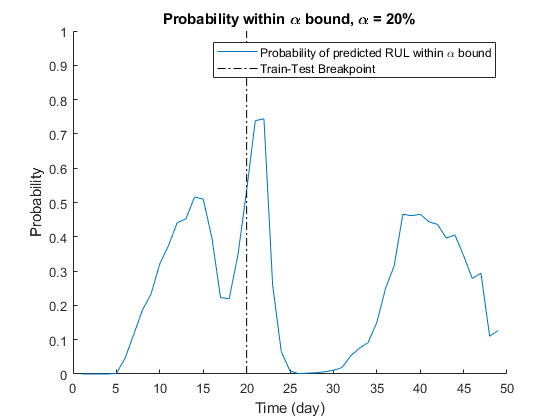
将预测的RUL的概率形象化 绑定。
图T = 1:totalDay;保持在plot([断点],[0 1],“k -”。)举行从包含([“时间”timeUnit')'])ylabel ('可能性')传说(“在\alpha范围内预测RUL的概率”,“列车试验断点”)标题('在\alpha范围内的概率,\alpha = 'num2str(阿尔法* 100)'%'])
参考文献
[1]
[2] Ali, Jaouher Ben等人。“基于无监督机器学习的风电机组轴承渐进性退化在线自动诊断研究”。应用声学132(2018):167-181。
[3]赛迪,卢特菲,等。“风力涡轮机高速通过的光谱峰度衍生指数和SVR轴轴承健康预后。”应用声学120 (2017):1 - 8。
[4] Coble, Jamie Baalis。“通过合并数据源来预测剩余有效寿命——一种自动识别预后参数的方法。”(2010)。
[5] Saxena先生,阿比纳夫,等。“指标的预后性能下线的评价。”国际杂志预测与健康管理1.1 (2010):4-23。
也可以看看
相关的话题
你也可以从以下列表中选择一个网站:
