基于机器学习和深度学习的雷达目标分类
这个例子展示了如何用机器和深度学习方法对雷达返回进行分类。机器学习方法使用小波散射特征提取和支持向量机。金宝app此外,本文还介绍了两种深度学习方法:使用SqueezeNet的迁移学习和长短期记忆(LSTM)递归神经网络。注意,本示例中使用的数据集不需要高级技术,但描述了工作流,因为这些技术可以扩展到更复杂的问题。
介绍
目标分类是现代雷达系统的一项重要功能。本例使用机器和深度学习对圆柱体和圆锥体的雷达回波进行分类。虽然本示例使用了合成的I/Q样本,但该工作流适用于真实的雷达返回。
RCS合成
下一节将展示如何创建合成数据来训练学习算法。
下面的代码模拟半径为1米,高度为10米的圆柱体的RCS模式。雷达的工作频率是850兆赫兹。
c = 3 e8;fc = 850 e6;[cylrcs, az, el] = rcscylinder (1,1 10 c, fc);helperTargetRCSPatternPlot (az, el, cylrcs);
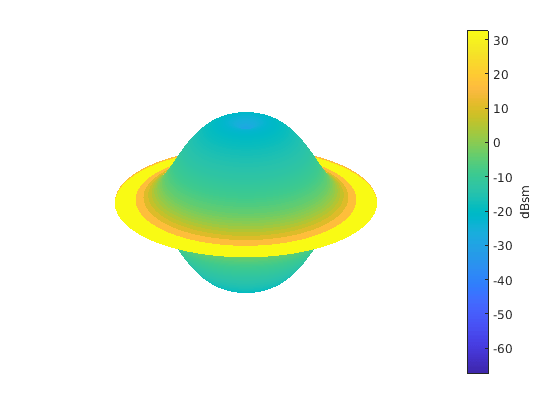
该模式可以应用于后向散射雷达目标,以模拟从不同方面的角度返回。
cyltgt =分阶段。BackscatterRadarTarget (“PropagationSpeed”c...“OperatingFrequency”足球俱乐部,“AzimuthAngles”阿兹,“ElevationAngles”埃尔,“RCSPattern”, cylrcs);
下面的图表显示了如何模拟随时间的100次圆柱返回。假设圆柱体在进行运动时,在瞄准镜周围引起微小振动,因此,从一个样品到下一个样品的角度发生变化。
rng默认的;N = 100;阿兹= 2 * randn (1, N);el = 2 * randn (1, N);cylrtn = cyltgt ((1, N), [az; el]);情节(mag2db (abs (cylrtn)));包含(“时间指数”) ylabel (“目标回报(dB)”);标题('圆柱的目标返回');
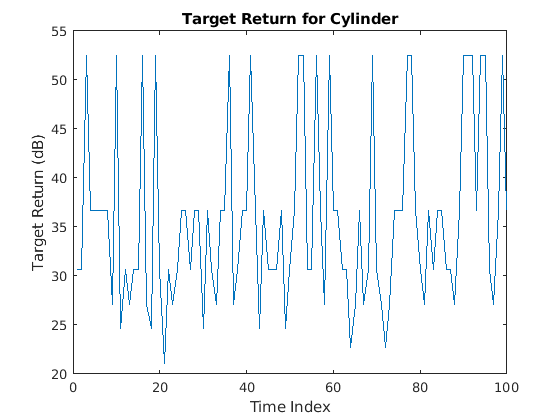
同样可以产生圆锥的返回。为了创建训练集,对任意选择的5个圆柱体半径重复上述过程。此外,对于每个半径,通过改变入射角,跟随10条随机生成的正弦波曲线,模拟10条运动轨迹。每个运动轮廓中有701个样本,所以有701 × 50个样本。对圆柱体目标重复这一过程,得到一个701 × 100矩阵的训练数据,包含50个圆柱体和50个锥体轮廓。在测试集中,我们使用25个圆柱体和25个锥体轮廓来创建701 × 50的训练集。由于计算时间长,将训练数据预先计算并加载如下。
负载(“RCSClassificationReturnsTraining”);负载(“RCSClassificationReturnsTest”);
作为一个例子,下一个图显示了从每个形状的一个运动配置文件的返回。图中显示了入射方位角和目标返回值随时间的变化情况。
subplot(2,2,1) plot(cylinderAspectAngle(1,:)) ylim([-90 90]) grid在标题(“柱面角度与时间”);包含(“时间指数”);ylabel (的视线角(度));次要情节(2,2,3)情节(RCSReturns.Cylinder_1);ylim (50 [-50]);网格在标题(“缸返回”);包含(“时间指数”);ylabel (“目标回报(dB)”);次要情节(2 2 2)情节(coneAspectAngle (1:));ylim(90年[-90]);网格在;标题(“圆锥角度与时间”);包含(“时间指数”);ylabel (的视线角(度));次要情节(2、2、4);情节(RCSReturns.Cone_1);ylim (50 [-50]);网格在;标题(“锥返回”);包含(“时间指数”);ylabel (“目标回报(dB)”);

小波散射
在小波散射特征提取器中,数据通过一系列小波变换、非线性和平均来产生时间序列的低方差表示。小波时间散射产生的信号表示对输入信号的移位不敏感,而不牺牲类的可辨别性。
在小波时间散射网络中需要指定的关键参数是时不变的尺度、小波变换的次数以及每个小波滤波器组中每倍频程的小波数。在许多应用中,两个滤波器组的级联就足以实现良好的性能。在这个例子中,我们构造了一个带有两个滤波器组的小波时间散射网络:第一个滤波器组每八度有4个小波,第二个滤波器组每八度有2个小波。不变性尺度设置为701个样本,即数据的长度。
sn = waveletScattering (“SignalLength”, 701,“InvarianceScale”, 701,“QualityFactors”(4 - 2));
然后,我们得到训练集和测试集的散射变换。
应变= sn.featureMatrix (RCSReturns {:,:},“转换”,“日志”);圣= sn.featureMatrix (RCSReturnsTest {:,:},“转换”,“日志”);
对于这个例子,使用沿每条路径的散射系数的平均值。
TrainFeatures =挤压(平均(压力,2))的;TestFeatures =挤压(平均(圣,2))的;
为培训和学习创建标签
TrainLabels = repelem(分类({“气缸”,“锥”}),[50 50])”;TestLabels = repelem(分类({“气缸”,“锥”}),[25] 25日)';
模型训练
将二次核支持金宝app向量机模型拟合到散射特征上,得到交叉验证的精度。
模板= templateSVM (“KernelFunction”,多项式的,...“PolynomialOrder”2,...“KernelScale”,“汽车”,...“BoxConstraint”, 1...“标准化”,真正的);classificationSVM = fitcecoc (...TrainFeatures,...TrainLabels,...“学习者”模板,...“编码”,“onevsone”,...“类名”分类({“气缸”,“锥”}));partitionedModel = crossval (classificationSVM,“KFold”5);[validationPredictions, validationScores] = kfoldPredict(partitionedModel);validationAccuracy = (1 - kfoldLoss(partitionedModel,“LossFun”,“ClassifError”)) * 100
validationAccuracy = 100
目标分类
使用训练过的支持向量机,对测试集得到的散射特征进行分类。
predLabels =预测(classificationSVM TestFeatures);精度= sum(predLabels == TestLabels) /numel(TestLabels)*100
精度= 100
绘制混淆矩阵。
图(“单位”,“归一化”,“位置”,[0.2 0.2 0.5 0.5]);ccDCNN = confusionchart (TestLabels predLabels);ccDCNN。Title =“混乱图”;ccDCNN。ColumnSummary =“column-normalized”;ccDCNN。RowSummary =“row-normalized”;

对于更复杂的数据集,深度学习工作流可能会提高性能。
CNN的迁移学习
SqueezeNet是一种深度卷积神经网络(CNN),用于ImageNet大规模视觉识别挑战(ILSVRC)中训练的1000类图像。在本例中,我们重用了预先训练过的SqueezeNet,将雷达返回归为以下两类之一。
负载SqueezeNet。
snet = squeezenet;
SqueezeNet由68层组成。像所有的dcnn一样,SqueezeNet将卷积算子级联,然后是非线性和池化或平均。SqueezeNet需要一个尺寸为227 × 227 × 3的图像输入,您可以通过下面的代码看到。
snet.Layers (1)
ans = ImageInputLayer with properties: Name: 'data' InputSize: [227 227 3] Hyperparameters DataAugmentation: 'none' NormalizationDimension: 'auto' Mean: [1×1×3 single]
此外,将SqueezeNet配置为识别1000个不同的类,您可以通过下面的代码看到。
snet.Layers (68)
ans = ClassificationOutputLayer with properties: Name: 'ClassificationLayer_predictions' Classes: [1000×1 categorical] ClassWeights: 'none' OutputSize: 1000 Hyperparameters LossFunction: 'crossentropyex'
在接下来的部分中,我们将修改SqueezeNet的选择层,以便将其应用到我们的分类问题中。
连续小波变换
SqueezeNet的设计目的是区分图像的差异,并对结果进行分类。因此,为了使用SqueezeNet对雷达回波进行分类,必须将一维雷达回波时间序列转换为图像。一种常见的方法是使用时频表示(TFR)。信号的时频表示有多种选择,其中哪一种最合适取决于信号的特性。为了确定哪个TFR可能适合这个问题,从每个类中随机选择和绘制一些雷达返回。
rng默认的;idxCylinder = randperm (50, 2);idxCone = randperm (50, 2) + 50;
很明显,前面显示的雷达回波的特征是变慢的变化,被前面描述的大的瞬态下降打断。小波变换非常适合于稀疏地表示这些信号。小波收缩,以局部瞬态现象与高时间分辨率和拉伸,以捕获缓慢变化的信号结构。获得并绘制其中一个圆柱体的连续小波变换。
类(RCSReturns {: idxCylinder (1)},“VoicesPerOctave”, 8)
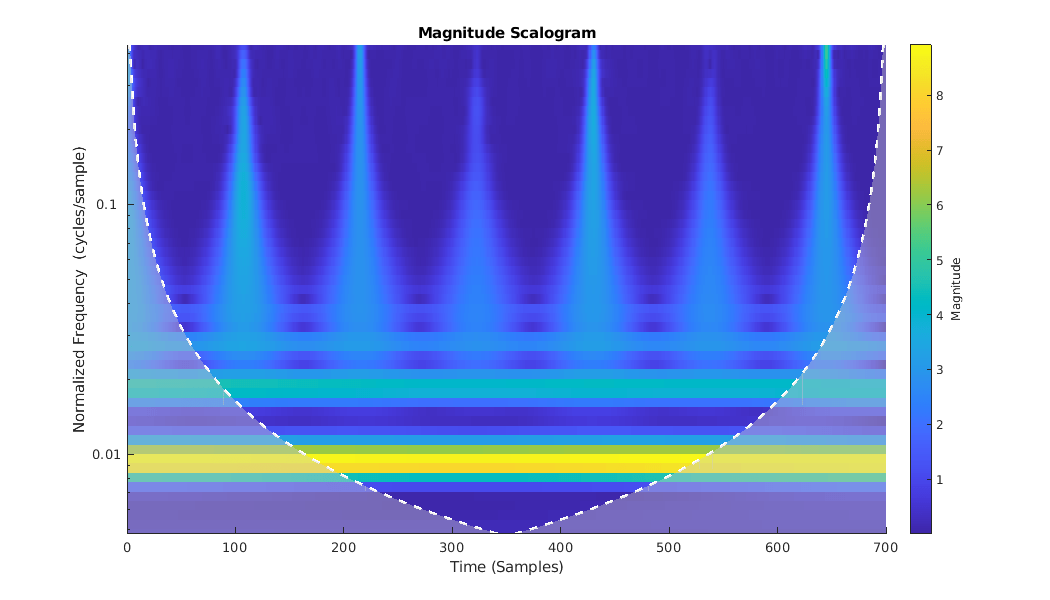
CWT同时捕捉慢变化(低频)波动和瞬态现象。对比圆柱返回的CWT与圆锥目标返回的CWT。
类(RCSReturns {: idxCone (2)},“VoicesPerOctave”8);
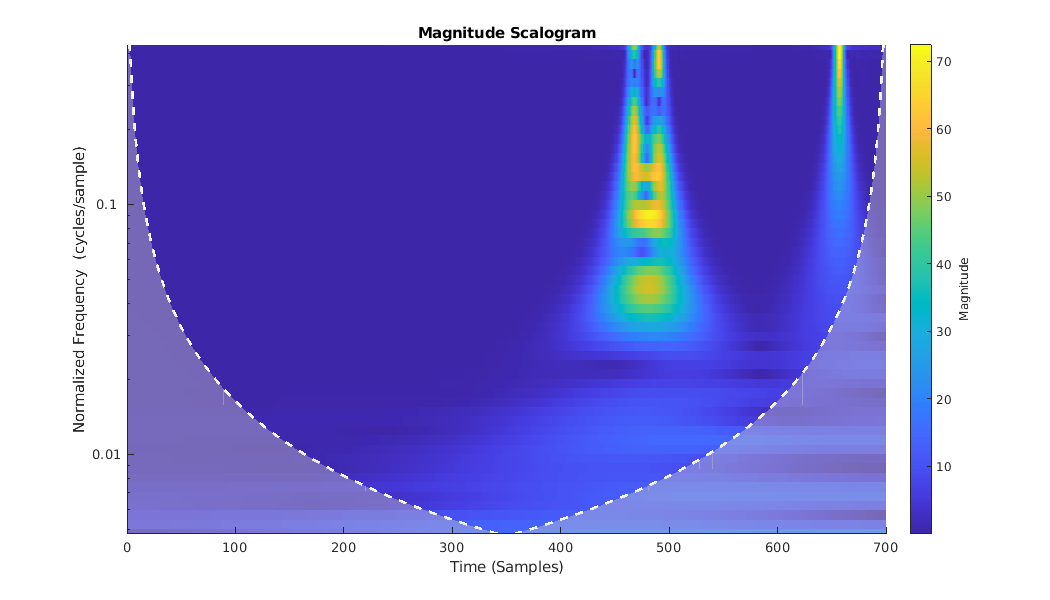
由于瞬态在确定目标返回是否来自圆柱体或锥体目标时具有明显的重要性,我们选择CWT作为理想的TFR。在获得每个目标回波的CWT后,我们将每个雷达回波的CWT进行成像。这些图像被调整大小以与SqueezeNet的输入层兼容,我们利用SqueezeNet对结果图像进行分类。
形象准备
辅助功能,helpergenWaveletTFImg,获取每个雷达返回的CWT,重新设计CWT以与SqueezeNet兼容,并将CWT写入jpeg文件。运行helpergenWaveletTFImg,选择一个parentDir你有写的权限。这个示例使用tempdir,但您可以使用计算机上您拥有写权限的任何文件夹。helper函数创建培训和测试设置文件夹下parentDir以及创造油缸和锥子文件夹下都培训和测试.这些文件夹中填充了jpeg图像,用作SqueezeNet的输入。
parentDir = tempdir;helpergenWaveletTFImg (parentDir RCSReturns RCSReturnsTest)
生成时频表示……创建圆柱体时频表示…创建圆锥时间频率表示完成…创建圆柱体时频表示完成…创建圆锥时间频率表示完成…完成
现在使用imageDataStore管理文件夹中的文件访问,以培训SqueezeNet。为培训和测试数据创建数据存储。
trainingData = imageDatastore (fullfile (parentDir“培训”),“IncludeSubfolders”,真的,...“LabelSource”,“foldernames”);testData = imageDatastore (fullfile (parentDir“测试”),“IncludeSubfolders”,真的,...“LabelSource”,“foldernames”);
为了使用SqueezeNet解决这个二进制分类问题,我们需要修改几个层。首先,我们改变了SqueezeNet中最后一个可学习层(层64),使其具有与我们的新类数量2相同的1乘1卷积数量。
lgraphSqueeze = layerGraph (snet);convLayer = lgraphSqueeze.Layers (64);numClasses =元素个数(类别(trainingData.Labels));numClasses newLearnableLayer = convolution2dLayer (1,...“名字”,“binaryconv”,...“WeightLearnRateFactor”10...“BiasLearnRateFactor”10);lgraphSqueeze = replaceLayer (lgraphSqueeze convLayer.Name newLearnableLayer);classLayer = lgraphSqueeze.Layers(结束);newClassLayer = classificationLayer (“名字”,“二元”);lgraphSqueeze = replaceLayer (lgraphSqueeze classLayer.Name newClassLayer);
最后,设置对SqueezeNet进行再培训的选项。设置初始学习率为1e-4,最大周期数为15,minibatch大小为10。使用带动量的随机梯度下降。
劳工关系= 1的军医;mxEpochs = 15;mbSize = 10;选择= trainingOptions (“个”,“InitialLearnRate”劳工关系,...“MaxEpochs”mxEpochs,“MiniBatchSize”mbSize,...“阴谋”,“训练进步”,“ExecutionEnvironment”,“cpu”);
培训网络。如果你有一个兼容的GPU,trainNetwork自动使用GPU和训练应该在1分钟内完成。如果你没有兼容的GPU,trainNetwork使用CPU和训练应该花费大约5分钟。训练时间会因一些因素而有所不同。在这种情况下,训练在cpu上进行,通过设置ExecutionEnvironment参数cpu.
CWTnet = trainNetwork (trainingData lgraphSqueeze,选择);
初始化输入数据规范化。
|========================================================================================| | 时代| |迭代时间| Mini-batch | Mini-batch |基地学习 | | | | ( hh: mm: ss) | | |丧失准确性 | |========================================================================================|
| 1 | 1 | 00:00:00:06 | 60.00% | 2.6639 | 1.0000e-04 |
| 5 | 50 | 00:01:08 | 100.00% | 0.0001 | 1.0000e-04 |
| 10 | 100 | 00:02:11 | 100.00% | 0.0002 | 1.0000e-04 |
| 15 | 150 | 00:03:12 | 100.00% | 2.2264e-05 | 1.0000e-04 |
|========================================================================================|
使用训练过的网络来预测保留测试集中的目标收益。
predictedLabels =分类(CWTnet testData,“ExecutionEnvironment”,“cpu”);精度= sum(predictedLabels == testData.Labels)/50*100
精度= 100
绘制混淆图,以及精确度和回忆度。在这种情况下,100%的测试样本分类正确。
图(“单位”,“归一化”,“位置”,[0.2 0.2 0.5 0.5]);ccDCNN = confusionchart (testData.Labels predictedLabels);ccDCNN。Title =“混乱图”;ccDCNN。ColumnSummary =“column-normalized”;ccDCNN。RowSummary =“row-normalized”;

LSTM
在本例的最后一节中,将描述一个LSTM工作流。首先定义LSTM层:
LSTMlayers = [...sequenceInputLayer (1) bilstmLayer (100“OutputMode”,“最后一次”) fulllyconnectedlayer (2) softmaxLayer classificationLayer];选择= trainingOptions (“亚当”,...“MaxEpochs”30岁的...“MiniBatchSize”, 150,...“InitialLearnRate”, 0.01,...“GradientThreshold”, 1...“阴谋”,“训练进步”,...“详细”假的,“ExecutionEnvironment”,“cpu”);trainLabels = repelem(分类({“气缸”,“锥”}), 50 50);trainLabels = trainLabels (:);trainData = num2cell (table2array (RCSReturns) ', 2);testData = num2cell (table2array (RCSReturnsTest) ', 2);testLabels = repelem(分类({“气缸”,“锥”}), [25] 25);testLabels = testLabels (:);RNNnet = trainNetwork (trainData trainLabels、LSTMlayers选项);
并给出了该系统的精度。
predictedLabels =分类(RNNnet testData,“ExecutionEnvironment”,“cpu”);精度= sum(predictedLabels == testLabels)/50*100
精度= 100
结论
这个例子展示了一个使用机器和深度学习技术进行雷达目标分类的工作流程。虽然本示例使用合成数据进行训练和测试,但它可以很容易地扩展以适应真实的雷达返回。由于信号的特点,小波技术被用于机器学习和CNN方法。
使用这个数据集,我们也获得了类似的精度,只需将原始数据输入LSTM。在更复杂的数据集中,原始数据可能在本质上太不稳定,以至于模型无法从原始数据中学习到可靠的特征,因此在使用LSTM之前,您可能不得不求助于特征提取。
你也可以从以下列表中选择一个网站: