训练多个代理执行协作任务
这个例子展示了如何设置一个多智能训练仿真软件®环境。金宝app在这个例子中,您训练两个代理协作执行的任务移动一个对象。

环境在这个例子中是一个无摩擦的二维表面含有元素由圆圈表示。目标对象所代表的C是蓝色的圆的半径2米,和机器人(红色)和B(绿色)是由更小的圆的半径1米。机器人试图移动对象C外圆环的半径8 m运用力量的碰撞。所有的元素在环境质量和遵守牛顿运动定律。此外,元素之间的接触力和环境边界建模为春季和质量阻尼系统。表面的元素可以通过外部的应用程序应用部队在X和Y方向。没有在第三维度和运动系统的总能量是守恒的。
这个例子所需创建的一组参数。
rlCollaborativeTaskParams
打开仿真软件模型。金宝app
mdl =“rlCollaborativeTask”;open_system (mdl)
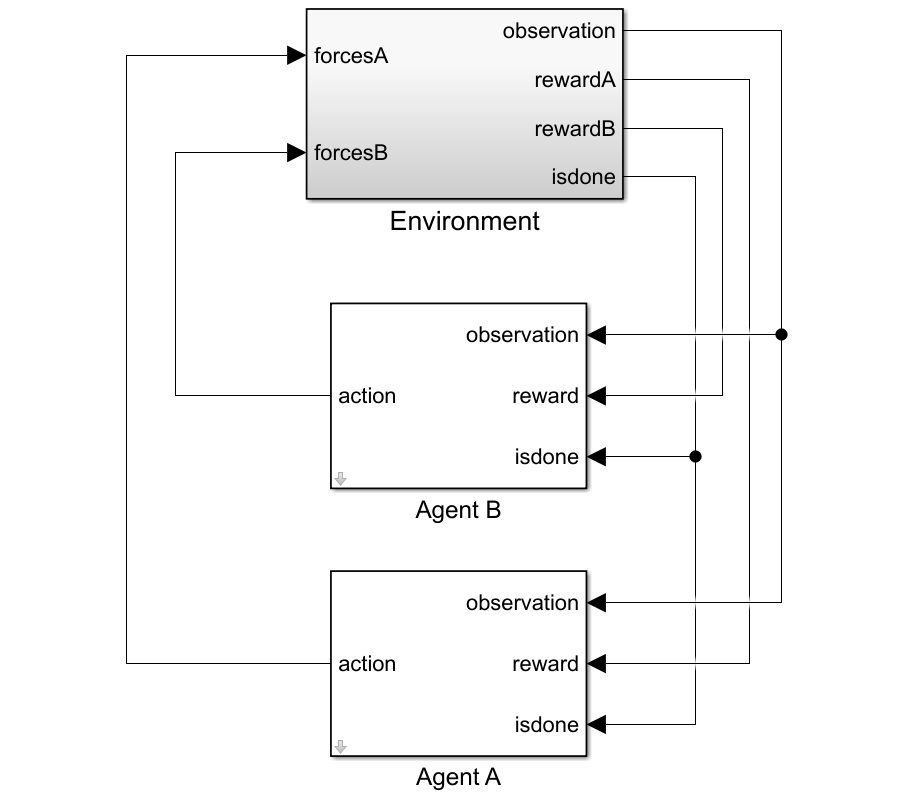
对于这个环境:
二维空间是有界从-12米到12米在X和Y方向。
接触弹簧刚度和阻尼值100 N / m和0.1 N / m / s,分别。
代理共享相同的观测位置,速度的A, B, C和动作值从最后一次一步。
仿真对象C圆环外移动时终止。
在每个时间步,代理获得以下奖励:
在这里:
和 由代理收到的奖励A和B,分别。
是一个团队奖励,即接收到代理对象C靠近边界的戒指。
和 A和B是本地处罚收到代理根据距离C和对象的大小从最后一次行动步骤。
是对象的距离C从环的中心。
和 代理之间的距离和对象B和C和代理对象C,分别。
和 A和B是代理人的行动值从最后一次一步。
这个示例使用近端与离散优化(PPO)代理政策操作空间。更多地了解PPO代理,看看近端政策优化代理。代理申请外部力量导致运动的机器人。在每一个时间步,代理人选择行动 ,在那里 下面是一个双外部应用。
创建环境
多智能体环境,创建一个指定代理的块路径使用字符串数组。同时,指定使用细胞观察和行动规范对象数组。单元阵列中的规范对象的顺序必须匹配块路径数组中指定的顺序。当代理可用MATLAB工作区环境创建的时候,观察和行动规范数组是可选的。关于多智能体环境创造的更多信息,请参阅rl金宝appSimulinkEnv。
创造的I / O规范环境。在本例中,代理是均匀和I / O规格相同。
%的观察numObs = 16;%的行动numAct = 2;%最大价值的外部作用力(N)maxF = 1.0;为每个代理% I / O规范oinfo = rlNumericSpec ([numObs, 1]);ainfo = rlFiniteSetSpec ({[maxF maxF] [maxF 0] [maxF maxF] [0 maxF] [0 0] [0 maxF] [maxF maxF] [maxF 0] [maxF maxF]});oinfo。Name =“观察”;ainfo。Name =“力量”;
创建界面的仿真软件环境金宝app。
黑色= [“rlCollaborativeTask /代理”,“B rlCollaborativeTask /代理”];obsInfos = {oinfo, oinfo};actInfos = {ainfo, ainfo};env = rl金宝appSimulinkEnv (mdl,黑色,obsInfos actInfos);
指定一个重置功能环境。重置功能resetRobots确保了机器人从随机初始位置在每集的开始。
env。ResetFcn = @(在)resetRobots (RA, RB、RC boundaryR);
创建代理
PPO代理依靠演员和评论家表示学习最优政策。在本例中,代理维护神经网络函数接近者为演员和评论家。
创建评论家神经网络和代表性。评论家网络状态值的输出函数 国家 。
%重置随机种子来提高再现性rng (0)%评论家网络criticNetwork = […featureInputLayer (oinfo.Dimension (1),“归一化”,“没有”,“名字”,“观察”)fullyConnectedLayer (128,“名字”,“CriticFC1”,“WeightsInitializer”,“他”)reluLayer (“名字”,“CriticRelu1”)fullyConnectedLayer (64,“名字”,“CriticFC2”,“WeightsInitializer”,“他”)reluLayer (“名字”,“CriticRelu2”)fullyConnectedLayer (32,“名字”,“CriticFC3”,“WeightsInitializer”,“他”)reluLayer (“名字”,“CriticRelu3”)fullyConnectedLayer (1,“名字”,“CriticOutput”));%评论家表示criticOpts = rlRepresentationOptions (“LearnRate”1的军医);criticA = rlValueRepresentation (criticNetwork oinfo,“观察”,{“观察”},criticOpts);criticB = rlValueRepresentation (criticNetwork oinfo,“观察”,{“观察”},criticOpts);
演员网络的输出概率 每个可能的行动对在某一状态 。创建一个演员神经网络和代表性。
%的演员网络actorNetwork = […featureInputLayer (oinfo.Dimension (1),“归一化”,“没有”,“名字”,“观察”)fullyConnectedLayer (128,“名字”,“ActorFC1”,“WeightsInitializer”,“他”)reluLayer (“名字”,“ActorRelu1”)fullyConnectedLayer (64,“名字”,“ActorFC2”,“WeightsInitializer”,“他”)reluLayer (“名字”,“ActorRelu2”)fullyConnectedLayer (32,“名字”,“ActorFC3”,“WeightsInitializer”,“他”)reluLayer (“名字”,“ActorRelu3”)fullyConnectedLayer(元素个数(ainfo.Elements),“名字”,“行动”)softmaxLayer (“名字”,“SM”));%的演员表示actorOpts = rlRepresentationOptions (“LearnRate”1的军医);actorA = rlStochasticActorRepresentation (actorNetwork oinfo ainfo,…“观察”,{“观察”},actorOpts);actorB = rlStochasticActorRepresentation (actorNetwork oinfo ainfo,…“观察”,{“观察”},actorOpts);
创建代理。两个特工使用相同的选项。
agentOptions = rlPPOAgentOptions (…“ExperienceHorizon”,256,…“ClipFactor”,0.125,…“EntropyLossWeight”,0.001,…“MiniBatchSize”,64,…“NumEpoch”3,…“AdvantageEstimateMethod”,gae的,…“GAEFactor”,0.95,…“SampleTime”Ts,…“DiscountFactor”,0.9995);agentA = rlPPOAgent (actorA criticA agentOptions);agentB = rlPPOAgent (actorB criticB agentOptions);
培训期间,代理收集经验,直到256年的经验地平线步骤或事件终止,然后火车从mini-batches 64经验。这个例子使用一个目标函数剪辑因素0.125提高培训稳定和折现系数为0.9995,鼓励长期回报。
培训代理商
指定以下训练训练特工的选项。
运行培训最多1000集,每集持续最多5000的时间步骤。
阻止一个代理的培训当其平均奖励连续超过100集是-10或者更多。
maxEpisodes = 1000;maxSteps = 5 e3;trainOpts = rlTrainingOptions (…“MaxEpisodes”maxEpisodes,…“MaxStepsPerEpisode”maxSteps,…“ScoreAveragingWindowLength”,100,…“阴谋”,“训练进步”,…“StopTrainingCriteria”,“AverageReward”,…“StopTrainingValue”,-10);
火车多个代理、指定代理的一个数组火车函数。代理的顺序数组中指定的代理块路径必须匹配订单在创造环境。这样做确保代理对象是与他们的环境中适当的I / O接口。训练这些代理可能需要几个小时才能完成,这取决于可用的计算能力。
垫文件rlCollaborativeTaskAgents包含一组pretrained代理。你可以加载文件和查看代理的性能。培训代理商自己,集doTraining来真正的。
doTraining = false;如果doTraining统计=火车([agentA agentB], env, trainOpts);其他的负载(“rlCollaborativeTaskAgents.mat”);结束
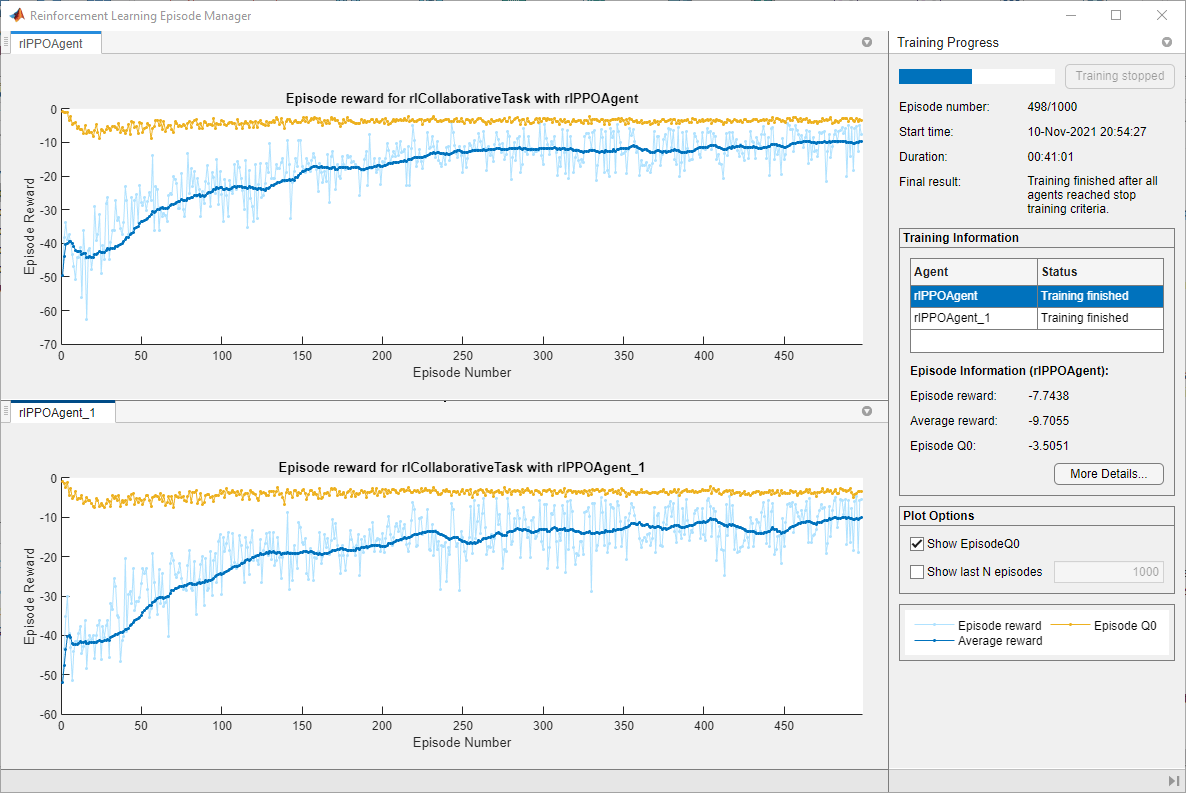
下面的图显示了一个快照的培训进度。你可以期待不同的结果由于随机性的培训过程。

模拟代理
模拟环境中的训练有素的特工。
simOptions = rlSimulationOptions (“MaxSteps”,maxSteps);经验= sim (env, [agentA agentB], simOptions);
代理模拟更多的信息,请参阅rlSimulationOptions和sim卡。
