强调使用消费信贷违约概率的测试面板数据
这个例子说明了如何与消费者(零售)信贷面板数据的工作,在不同层面观察到的可视化违约率。它也显示了如何适应一个模型来预测违约概率和执行压力测试分析。
面板数据集消费贷款使您能够识别用于买书年不同年龄的贷款,或违约率模式。您可以利用这些分数组信息来区分不同的分数级别违约率。此外,你可以用宏观经济信息来评估经济状况如何影响消费贷款的违约率。
一个标准的逻辑回归模型,类型广义线性模型,被装配到具有和不具有宏观预测零售信用面板数据。该实施例描述了如何适应更先进的模型,以考虑面板数据的影响,广义线性混合效应模型。然而,面板效应可以忽略对于该示例中的数据集和标准逻辑模型是优选的效率。
标准逻辑回归模型预测的书全部得分级别违约概率年,宏观经济变量的情况。当标准逻辑回归模型被用于压力测试分析,该模型预测的不良和严重不利的宏观经济情景默认对于给定的基线概率,以及默认概率。
有关其他信息,请参见实施例用Cox比例风险模型违约率,它遵循相同的工作流程,但使用Cox回归,而不是逻辑回归,也有终生PD和寿命预期的诚信缺失(ECL)的计算的附加信息。
面板数据说明
主数据组(数据)包含以下变量:
ID:贷款标识符。ScoreGroup:信用评分在贷款,离散成三组的开头:高风险,中等风险和低风险。YOB:年的书。默认:默认指标。这是响应变量。年: 公历年。
还有一个小的数据集(dataMacro)与相应的日历年的宏观经济数据:
年: 公历年。GDP:国内生产总值增长(年同比)。市场:市场收益率(年同比)。
变量YOB,年,GDP和市场在相应的历年年底被观察到。该评分组是原始的信用评分的离散时贷开始。的价值1对于默认意味着贷款在相应的历年拖欠。
还有第三个数据集(dataMacroStress)与基准,不利的,严重的不良情形的宏观经济变量。此表用于压力测试分析。
这个例子使用模拟数据,但同样的方法已成功地应用于实际的数据集。
加载面板数据
加载数据并查看第一10和最后10行表中的。面板数据被堆叠,在对于相同的ID的观测值存储在连续的行的意义上,创建高瘦表。该小组是不平衡的,因为不是所有的ID具有相同的若干意见。
加载RetailCreditPanelData.matfprintf中('\ n第一十行:\ n')
前十行:
DISP(数据(1:10,:))
ID ScoreGroup YOB默认年__ ___________ ___ _______ ____ 1低风险1 0 1997 1低风险2 0 1998 1低风险3 0 1999 1低风险4 0 2000 1低风险5 0 2001 1低风险6 0 2002 1低风险70 2003 1低风险8 0 2004 2中等风险1 0 1997 2中等风险2 0 1998
fprintf中(“最后十行:\ n”)
最后十行:
DISP(数据(端9:端,:))
ID ScoreGroup YOB默认年_____ ___________ ___ _______ ____ 96819高风险6 0 2003 96819高风险7 0 2004 96820中等风险1 0 1997 96820中等风险2 0 1998 96820中等风险3 0 1999 96820中等风险4 0 2000 96820中等风险50 2001年96820中等风险6 0 2002 96820中等风险7 0 2003 96820中等风险8 0 2004年
NROWS =高度(数据);UniqueIDs =唯一的(data.ID);NIDS =长度(UniqueIDs);fprintf中('总数ID的:%d \ n',NIDS)
总数的ID:96820
fprintf中('总的行数:%d \ n',NROWS)
总的行数:646724
违约率由书籍评分组和年
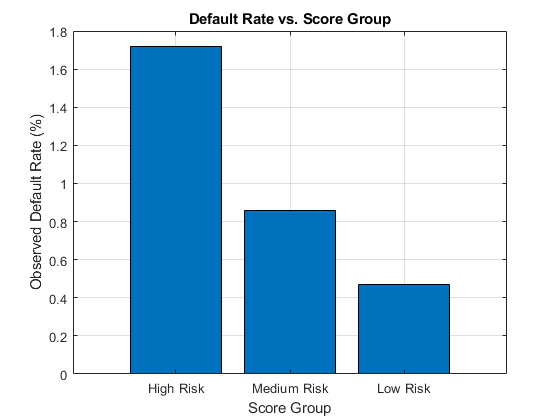
使用信用评分组作为分组变量计算每个评分组观察到的违约率。为此,使用groupsummary函数来计算平均值的默认变量,分组由ScoreGroup变量。绘制线图上的结果。正如预期的那样,违约率下降的信用质量得到改善。
DefRateByScore = groupsummary(数据,'ScoreGroup','意思','默认');NumScoreGroups =高度(DefRateByScore);DISP(DefRateByScore)
ScoreGroup GroupCount mean_Default ___________ __________ ____________高风险2.0999e + 05 0.017167中等风险2.1743e + 05 0.0086006低风险2.193e + 05 0.0046784
数字;杆(双(DefRateByScore.ScoreGroup),DefRateByScore.mean_Default * 100)集(GCA,'XTickLabel',类别(data.ScoreGroup))标题(“违约率与评分组”)xlabel(“分数集团)ylabel(“观察到的缺省率(%)”)网格上
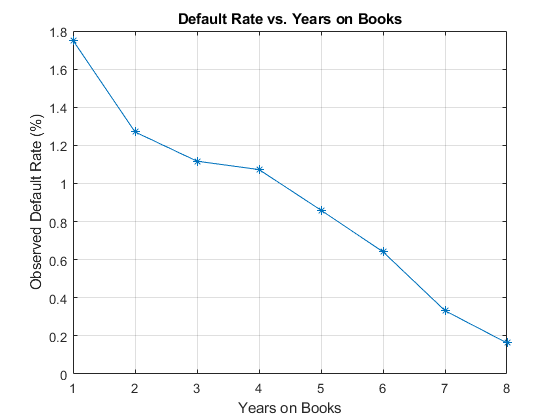
接下来,计算违约率由年书分组(由代表YOB变量)。所得到的利率条件一年的违约率。例如,第三年违约率的书籍是相对于那些在投资组合过去,第二年贷款的贷款数量在第三年拖欠的比例。换句话说,第三年的违约率是行与号码YOB=3和默认= 1,通过行与数除以YOB=3。
绘制的结果。有一个明显的下降趋势,违约率下降为年书的数量增加。年三,四有类似的违约率。然而,正是从这个情节尚不清楚这是否是贷款产品的特性或者宏观经济环境的影响。
DefRateByYOB = groupsummary(数据,'YOB','意思','默认');NumYOB =高度(DefRateByYOB);DISP(DefRateByYOB)
YOB GroupCount mean_Default ___ __________ ____________ 1 96820 0.017507 2 94535 0.012704 3 92497 0.011168 4 91068 0.010728 5 89588 0.0085949 6 88570 0.006413 7 61689 0.0033231 8 31957 0.0016272
数字;图(双(DefRateByYOB.YOB),DefRateByYOB.mean_Default * 100,' - *')标题(“违约率与上十年书”)xlabel(“年代的书”)ylabel(“观察到的缺省率(%)”)网格上
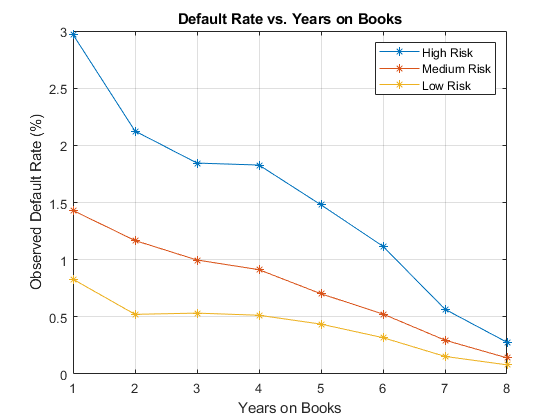
现在,两个小组通过的年图书评分组和数量,然后绘制出结果。该图显示,所有评分组的行为类似随着时间的推移,与一般呈下降趋势。年三,四是一个例外下降趋势:扁平化的费率高风险组,上三年度的低风险组。
DefRateByScoreYOB = groupsummary(数据,{'ScoreGroup','YOB'},'意思','默认');%显示输出表以显示它的结构的方式%只显示前10行,为了简洁DISP(DefRateByScoreYOB(1:10,:))
ScoreGroup YOB GroupCount mean_Default ___________ ___ __________ ____________高风险1 32601 0.029692高风险2 31338 0.021252高风险3 30138 0.018448高风险4 29438 0.018276高风险5 28661 0.014794高风险6 28117 0.011168高风险7 19606 0.0056615高风险8 10094 0.0027739中等风险1 32373 0.014302中等风险2 31775 0.011676
DISP('...')
...
DefRateByScoreYOB2 =重塑(DefRateByScoreYOB.mean_Default,...NumYOB,NumScoreGroups);数字;图(DefRateByScoreYOB2 * 100,' - *')标题(“违约率与上十年书”)xlabel(“年代的书”)ylabel(“观察到的缺省率(%)”)图例(类别(data.ScoreGroup))格上
年图书对战历年
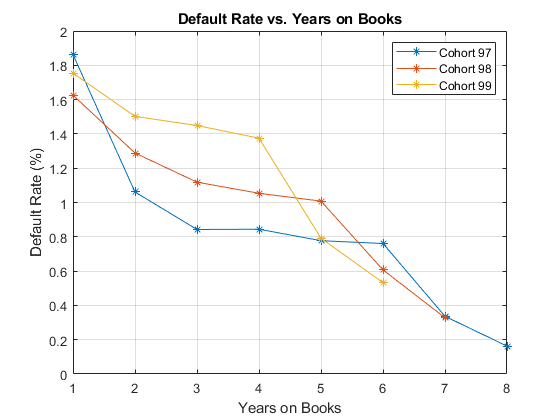
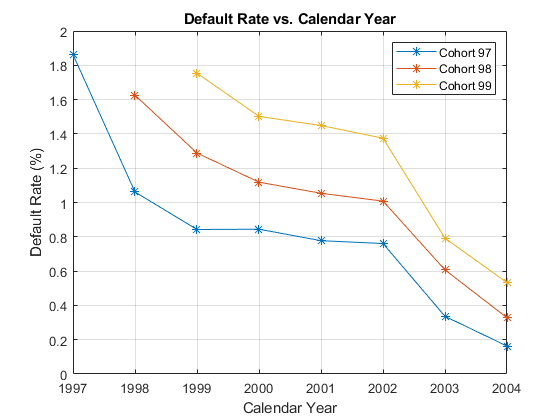
该数据包含三个同伙,或者年份:1997年,1998年,和1999年没有贷款始于1999年之后开始的面板数据的贷款。
本节将展示如何分别形象化每个队列违约率。所有同伙的违约率绘制,对双方的年图书的数量和对历年。在书的岁月模式表明贷款产品的特点。在历年模式表明宏观经济环境的影响。
从这几年的2到4买书,曲线显示了三组不同的图案。当对历年绘制,但是,三组显示从2000年至2002年。在此期间,展平的曲线类似的行为。
%获取ID的1997年,1998年和1999年的同伙IDs1997 = data.ID(data.YOB == 1&data.Year == 1997);IDs1998 = data.ID(data.YOB == 1&data.Year == 1998);IDs1999 = data.ID(data.YOB == 1&data.Year == 1999);%IDs2000AndUp是未使用的,它只是计算表明,这是空的,%无贷款在1999年之后开始IDs2000AndUp = data.ID(data.YOB == 1&data.Year> 1999);%获取默认为每一组分别率ObsDefRate1997 = groupsummary(数据(ismember(data.ID,IDs1997),:),...'YOB','意思','默认');ObsDefRate1998 = groupsummary(数据(ismember(data.ID,IDs1998),:),...'YOB','意思','默认');ObsDefRate1999 = groupsummary(数据(ismember(data.ID,IDs1999),:),...'YOB','意思','默认');对书上的多年%剧情数字;图(ObsDefRate1997.YOB,ObsDefRate1997.mean_Default * 100,' - *')保持上图(ObsDefRate1998.YOB,ObsDefRate1998.mean_Default * 100,' - *')图(ObsDefRate1999.YOB,ObsDefRate1999.mean_Default * 100,' - *')保持离标题(“违约率与上十年书”)xlabel(“年代的书”)ylabel('默认率(%)')图例(“组群97”,“队列98”,“组群99”)网格上
对历年情节%年份=唯一的(data.Year);数字;图(年,ObsDefRate1997.mean_Default * 100,' - *')保持上图(年份(2:结束),ObsDefRate1998.mean_Default * 100,' - *')图(年(3月底),ObsDefRate1999.mean_Default * 100,' - *')保持离标题(“默认速率与日历年”)xlabel('公历年')ylabel('默认率(%)')图例(“组群97”,“队列98”,“组群99”)网格上
在丛书中的得分集团和年违约率模型
您可视化数据后,可以为违约率建立预测模型。
面板数据分成训练集和测试集,定义基于ID号这些集。
NumTraining =地板(0.6 * NIDS);RNG('默认');TrainIDInd = randsample(NIDS,NumTraining);TrainDataInd = ismember(data.ID,UniqueIDs(TrainIDInd));TestDataInd =〜TrainDataInd;
第一个模型仅使用得分岁组和数量上的书籍作为违约率预测p。违约的几率被定义为P /(1-P)。逻辑模型涉及的几率的对数,或数比值向预测如下:
1M是具有值的指示符1对于中等风险贷款0否则,同样的1L对于低风险贷款。这是一种处理分类预测,如标准的方式ScoreGroup。有效地没有为每个风险等级不同的常数:啊对于高风险,AH + AM对于中等风险和AH + AL对于低风险。
为了校准模型,调用fitglm从统计和机器学习工具箱™功能。上面的公式表示为
默认〜1 + ScoreGroup + YOB
该1 + ScoreGroup术语占基线常数和风险水平调整。设置可选参数分配至二项式以指示逻辑模型期望(即,在左侧与数比值的模型)。
ModelNoMacro = fitglm(数据(TrainDataInd,:),...'默认〜1 + ScoreGroup + YOB',...'分配',“二项式”);DISP(ModelNoMacro)
广义线性回归模型:分对数(默认)〜1 + ScoreGroup + YOB分布=二项式估计系数:估计SE TSTAT p值________ _______ ___________(截距)-3.2453 0.033768 -96.106 0 ScoreGroup_Medium风险-0.7058 0.037103 -19.023 1.1014e-80 ScoreGroup_Low风险-1.2893 0.045635 -28.253 1.3076e-175 YOB -0.22693 0.008437 -26.897 2.3578e-159 388018观察,388014个误差自由度分散体:1驰^ 2统计量与常数模型:1.83e + 03,p值=0
对于数据中的任何一行,值p未观察到,只有一个0要么1默认指示器观察。校准模型发现系数,的预测值p个别行可以与恢复预测功能。
该截距系数是对于恒定高风险级(啊项),以及ScoreGroup_Medium风险和ScoreGroup_Low风险系数是调整中等风险和低风险水平(该上午和人计算)。
违约概率p和日志赔率(该模型的左侧)移动在相同的方向时的预测变化。因此,由于调整了中等风险和低风险是否定的,违约率是更好的风险水平较低,符合市场预期。对于年册数的系数也是负的,与多年在数据观察到的册数总体呈下降趋势是一致的。
以考虑面板数据的影响,使用混合效应的更先进的模型可以使用被装配fitglm从统计和机器学习工具箱™功能。虽然这种模式不被安装在这个例子中,代码非常相似:
ModelNoMacro = fitglme(数据(TrainDataInd,:), '默认〜1 + ScoreGroup + YOB +(1 | ID)', '分配', '二项式');
该(1个| ID)式中的术语增加了一个随机效应该模型。这种效果是预测其值在数据没有给出,但与模型系数一起校正。的随机值被校准为每个ID。这种额外的校准要求显着地增加,因为在非常大量的ID的计算时间,以适应模型在这种情况下,。对于该示例中的面板的数据集,所述随机术语具有可忽略的影响。随机效应的差异非常小,并引入了随机效应时,模型系数几乎没有变化。比较简单的逻辑回归模型是首选,因为它更快校准和预测,并与两个模型预测的违约率基本相同。
预测违约概率为训练和测试数据。
data.PDNoMacro =零(高度(数据),1);%预测样本内data.PDNoMacro(TrainDataInd)=预测(ModelNoMacro,数据(TrainDataInd,:));%预测外的样品data.PDNoMacro(TestDataInd)=预测(ModelNoMacro,数据(TestDataInd,:));
可视化样品中配合。
PredPDTrainYOB = groupsummary(数据(TrainDataInd,:),'YOB','意思',...{'默认','PDNoMacro'});数字;散射(PredPDTrainYOB.YOB,PredPDTrainYOB.mean_Default * 100,'*');保持上情节(PredPDTrainYOB.YOB,PredPDTrainYOB.mean_PDNoMacro * 100);保持离xlabel(“年代的书”)ylabel('默认率(%)')图例('观察到的','预料到的')标题(“模型拟合(训练数据)”)网格上

可视化出的样本外的配合。
PredPDTestYOB = groupsummary(数据(TestDataInd,:),'YOB','意思',...{'默认','PDNoMacro'});数字;散射(PredPDTestYOB.YOB,PredPDTestYOB.mean_Default * 100,'*');保持上情节(PredPDTestYOB.YOB,PredPDTestYOB.mean_PDNoMacro * 100);保持离xlabel(“年代的书”)ylabel('默认率(%)')图例('观察到的','预料到的')标题(“模型拟合(测试数据)”)网格上
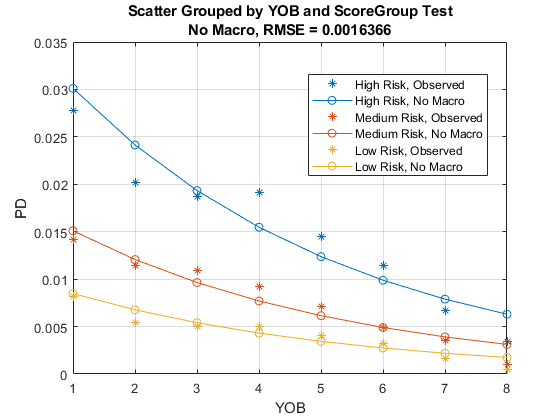
可视化的样本中,适用于所有评分组。外的样本的配合可以被计算并以类似的方式可视化。
PredPDTrainScoreYOB = groupsummary(数据(TrainDataInd,:),...{'ScoreGroup','YOB'},'意思'{'默认','PDNoMacro'});数字;HS = gscatter(PredPDTrainScoreYOB.YOB,...PredPDTrainScoreYOB.mean_Default * 100,...PredPDTrainScoreYOB.ScoreGroup,'rbmgk','*');mean_PDNoMacroMat =重塑(PredPDTrainScoreYOB.mean_PDNoMacro,...NumYOB,NumScoreGroups);保持上马力=情节(mean_PDNoMacroMat * 100);对于II = 1:NumScoreGroups马力(ⅱ)。颜色= HS(ⅱ)。颜色;结束保持离xlabel(“年代的书”)ylabel(“观察到的缺省率(%)”)图例(类别(data.ScoreGroup))标题(“模型拟合通过评分组(训练数据)”)网格上
违约率包括宏观经济变量的模型
与以前的模型所预测的趋势,随着年书的功能,具有非常规则的下降格局。这些数据,但是,显示了这一趋势的一些偏差。要尽量考虑那些偏差,加上国内生产总值年均增长率(由代表GDP变量)和股市的年回报率(由代表市场变量)到模型。
扩展数据集添加一个列GDP和一个用于市场,使用从所述数据dataMacro表。
data.GDP = dataMacro.GDP(data.Year-1996);data.Market = dataMacro.Market(data.Year-1996);DISP(数据(1:10,:))
ID ScoreGroup YOB默认年PDNoMacro GDP市场__ ___________ ___ ______ ____ _________ _____ ______ 1低风险1 0 1997年0.0084797 2.72 7.61 1低风险2 0 1998年0.0067697 3.57 26.24 1低风险3 0 1999年0.0054027 2.86 18.1 1低风险4 0 2000 0.00431052.43 3.19 1低风险5 0 2001 0.0034384 1.26 -10.51 1低风险6 0 2002 0.0027422 -0.59 -22.95 1低风险7 0 2003 0.0021867 0.63 2.78 1低风险8 0 2004 1.85 0.0017435 9.48 2中等风险1 0 1997 2.72 0.015097 7.612中等风险2 0 1998 0.012069 3.57 26.24
通过扩展模型公式,包括飞度与宏观经济变量模型GDP和市场变量。
ModelMacro = fitglm(数据(TrainDataInd,:),...'默认〜1 + ScoreGroup + YOB + GDP +市场',...'分配',“二项式”);DISP(ModelMacro)
广义线性回归模型:分对数(默认)〜1 + ScoreGroup + YOB + GDP +市场分销=二项式估计系数:估计SE TSTAT p值__________ _________ _______ ___________(截距)-2.667 0.10146 -26.287 2.6919e-152 ScoreGroup_Medium风险-0.70751 0.037108-19.066 4.8223e-81 ScoreGroup_Low风险-1.2895 0.045639 -28.253 1.2892e-175 YOB -0.32082 0.013636 -23.528 2.0867e-122 GDP -0.12295 0.039725 -3.095 0.0019681市场-0.0071812 0.0028298 -2.5377 0.011159 388018观察,388012个误差自由度分散体的:1驰^ 2统计量与常数模型:1.97E + 03,p值= 0
这两个宏观经济变量呈现负系数,与较高的经济增长降低违约率的直觉是一致的。
预测默认的训练和测试数据的概率。
data.PDMacro =零(高度(数据),1);%预测样本内data.PDMacro(TrainDataInd)=预测(ModelMacro,数据(TrainDataInd,:));%预测外的样品data.PDMacro(TestDataInd)=预测(ModelMacro,数据(TestDataInd,:));
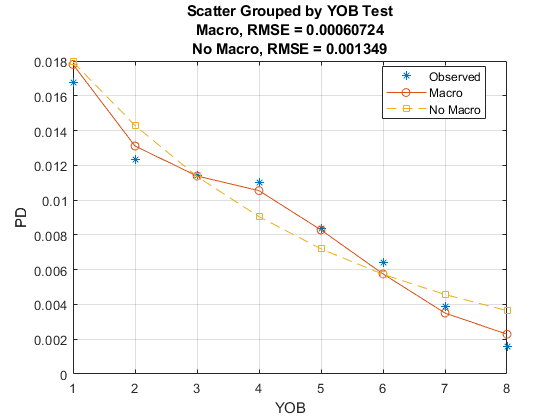
可视化样品中配合。如所希望的,该模型包括宏观经济变量,或宏模型,从通过以前的模型所预测的平滑趋势偏离。与宏模型所预测的速度与所观察到的违约率更紧密地匹配。
PredPDTrainYOBMacro = groupsummary(数据(TrainDataInd,:),'YOB','意思',...{'默认','PDMacro'});数字;散射(PredPDTrainYOBMacro.YOB,PredPDTrainYOBMacro.mean_Default * 100,'*');保持上情节(PredPDTrainYOB.YOB,PredPDTrainYOB.mean_PDNoMacro * 100);%没有宏情节(PredPDTrainYOBMacro.YOB,PredPDTrainYOBMacro.mean_PDMacro * 100);宏%保持离xlabel(“年代的书”)ylabel('默认率(%)')图例('观察到的',“没有宏”,“宏观”)标题(“宏模型拟合(训练数据)”)网格上
可视化出的样本外的配合。
PredPDTestYOBMacro = groupsummary(数据(TestDataInd,:),'YOB','意思',...{'默认','PDMacro'});数字;散射(PredPDTestYOBMacro.YOB,PredPDTestYOBMacro.mean_Default * 100,'*');保持上情节(PredPDTestYOB.YOB,PredPDTestYOB.mean_PDNoMacro * 100);%没有宏情节(PredPDTestYOBMacro.YOB,PredPDTestYOBMacro.mean_PDMacro * 100);宏%保持离xlabel(“年代的书”)ylabel('默认率(%)')图例('观察到的',“没有宏”,“宏观”)标题(“宏模型拟合(测试数据)”)网格上

可视化的样本中,适用于所有评分组。
PredPDTrainScoreYOBMacro = groupsummary(数据(TrainDataInd,:),...{'ScoreGroup','YOB'},'意思'{'默认','PDMacro'});数字;HS = gscatter(PredPDTrainScoreYOBMacro.YOB,...PredPDTrainScoreYOBMacro.mean_Default * 100,...PredPDTrainScoreYOBMacro.ScoreGroup,'rbmgk','*');mean_PDMacroMat =重塑(PredPDTrainScoreYOBMacro.mean_PDMacro,...NumYOB,NumScoreGroups);保持上马力=情节(mean_PDMacroMat * 100);对于II = 1:NumScoreGroups马力(ⅱ)。颜色= HS(ⅱ)。颜色;结束保持离xlabel(“年代的书”)ylabel(“观察到的缺省率(%)”)图例(类别(data.ScoreGroup))标题(“宏模型拟合通过评分组(训练数据)”)网格上
强调违约概率的测试
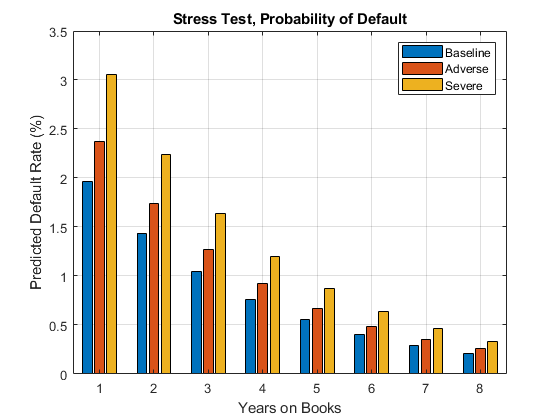
使用装有宏观模型压力测试默认的预测概率。
假设以下是用于提供,例如,通过调节器的宏观经济变量压力情景。
DISP(dataMacroStress)
国内生产总值市场_____ ______基准2.27 15.02 1.31不良重症4.56 -0.22 -5.64
建立一个基本的数据表预测违约概率。这是一个虚拟的数据表,其中一行的年图书评分组和编号的每个组合。
dataBaseline =表;[ScoreGroup,YOB] = meshgrid(1:NumScoreGroups,1:NumYOB);dataBaseline.ScoreGroup =分类(ScoreGroup(:),1:NumScoreGroups,...类别(data.ScoreGroup),“序”,真正);dataBaseline.YOB = YOB(:);dataBaseline.ID =酮(高度(dataBaseline),1);dataBaseline.GDP =零(高度(dataBaseline),1);dataBaseline.Market =零(高度(dataBaseline),1);
为了做出预测,对于评分组的年书的所有组合和数量设置相同的宏观经济条件(基线,不良或严重不良反应)。
%基线预测违约概率dataBaseline.GDP(:) = dataMacroStress.GDP(“基线”);dataBaseline.Market(:) = dataMacroStress.Market(“基线”);dataBaseline.PD =预测(ModelMacro,dataBaseline);%预测违约概率在悲观情形dataAdverse = dataBaseline;dataAdverse.GDP(:) = dataMacroStress.GDP(“不良”);dataAdverse.Market(:) = dataMacroStress.Market(“不良”);dataAdverse.PD =预测(ModelMacro,dataAdverse);%预测违约概率的严重不良反应情况dataSevere = dataBaseline;dataSevere.GDP(:) = dataMacroStress.GDP('严重');dataSevere.Market(:) = dataMacroStress.Market('严重');dataSevere.PD =预测(ModelMacro,dataSevere);
可视化的三种替代监管的情况下,整个评分组默认的平均预测概率。在这里,所有的分数组是以隐权重相等。然而,预测也可以在贷款层面做出任何给定的组合,使预测违约率与贷款组合中的实际分布一致。相同的可视化可以被单独地制造为每个评分组。
PredPDYOB =零(NumYOB,3);PredPDYOB(:,1)=平均值(重塑(dataBaseline.PD,NumYOB,NumScoreGroups),2);PredPDYOB(:,2)=平均值(重塑(dataAdverse.PD,NumYOB,NumScoreGroups),2);PredPDYOB(:,3)=平均值(重塑(dataSevere.PD,NumYOB,NumScoreGroups),2);数字;巴(PredPDYOB * 100);xlabel(“年代的书”)ylabel(“预测默认率(%)”)图例(“基线”,“不良”,'严重')标题(“压力测试,违约概率”)网格上
参考
广义线性模型文档://www.tatmou.com/help/stats/generalized-linear-regression.html。
广义线性混合效应模型文档://www.tatmou.com/help/stats/generalized-linear-mixed-effects-models.html。
美联储(Fed),综合资本分析和审查(CCAR):https://www.federalreserve.gov/bankinforeg/ccar.htm。
英国央行,压力测试:https://www.bankofengland.co.uk/financial-stability
欧洲银行管理局,欧盟范围内的压力测试:https://www.eba.europa.eu/risk-analysis-and-data/eu-wide-stress-testing。
您还可以选择从下面的列表中的网站:
