sbiopredictionci
计算模型预测的置信区间(需要统计和机器学习工具箱)
描述
ci= sbiopredictionci (fitResults)fitResults,一个NLINResults或OptimResults返回的sbiofit.ci是一个PredictionConfidenceInterval对象,该对象包含计算的置信区间数据。
ci= sbiopredictionci (fitResults,名称,值)名称,值对参数。
例子
计算估计PK参数和模型预测的置信区间
加载数据
加载样本数据以适应。数据存储为带有变量的表ID,时间,CentralConc,PeripheralConc.这一合成数据代表了三个人在输注剂量后,在中央和外周室的八个不同时间点测量的血浆浓度的时间过程。
负载data10_32R.matgData = groupedData(data);gData.Properties.VariableUnits = {”,“小时”,毫克/升的,毫克/升的};sbiotrellis (gData“ID”,“时间”,{“CentralConc”,“PeripheralConc”},“标记”,“+”,...“线型”,“没有”);

创建模型
创建一个两室模型。
pkmd = PKModelDesign;pkc1 = add隔间(pkmd,“中央”);pkc1。DosingType =“注入”;pkc1。EliminationType =“linear-clearance”;pkc1。HasResponseVariable = true;pkc2 = add隔间(pkmd,“外围”);Model = construct(pkmd);Configset = getconfigset(模型);configset.CompileOptions.UnitConversion = true;
定义剂量
确定输注剂量。
剂量= sbiodose(“剂量”,“TargetName”,“Drug_Central”);剂量。StartTime = 0;剂量。金额= 100;剂量。费率= 50;剂量。AmountUnits =毫克的;剂量。时间Units =“小时”;剂量。RateUnits =“毫克/小时”;
定义参数
定义要估计的参数。为每个参数设置参数边界。除了这些显式的边界之外,参数转换(如log、logit或probit)还施加了隐式的边界。
responseMap = {'Drug_Central = CentralConc','Drug_Peripheral = PeripheralConc'};paramsToEstimate = {“日志(中央)”,的日志(外围),“12”,“Cl_Central”};estimatedParam = estimatedInfo(paramsToEstimate,...“InitialValue”,[1 1 1 1 1],...“界限”,[0.1 3;0.1 10;0 10;0.1 2]);
合适的模型
执行未合并拟合,即对每个患者进行一组估计参数。
unpooledFit = sbiofit(模型,gData,responseMap,estimatedParam,剂量,“池”、假);
进行合并拟合,即对所有患者进行一组估计参数。
pooledFit = sbiofit(模型,gData,responseMap,estimatedParam,剂量,“池”,真正的);
计算估计参数的置信区间
计算未合并拟合中每个估计参数的95%置信区间。
ciParamUnpooled = sbioparameterci(unpooledFit);
显示结果
以表格格式显示置信区间。各估计状态的含义请参见参数置信区间估计状态.
ci2table (ciParamUnpooled)
ans = 12x7表组名估计置信区间类型Alpha状态_____ ______________ ________ __________________ _____________ ___________ 1 {'Central'} 1.422 1.1533 1.6906高斯0.05可估计1 {'Peripheral'} 1.5629 0.83143 2.3551高斯0.05约束1 {'Q12'} 0.47159 0.20093 0.80247高斯0.05约束1 {'Cl_Central'} 0.52898 0.44842 0.60955高斯0.05可估计2 {'Central'} 1.8322 1.7893 1.8751高斯0.05成功2 {'Peripheral'} 5.3368 3.9133 6.7602高斯0.05 success 2 {'Q12'} 0.27641 0.2093 0.34351高斯0.05 success 2 {'Cl_Central'} 0.86034 0.80313 0.91755高斯0.05 success 3 {'Central'} 1.6657 1.5818 1.7497高斯0.05 success 3 {'Peripheral'} 5.5632 4.7557 6.3708高斯0.05 success 3 {'Q12'} 0.78361 0.65581 0.91142高斯0.05 success 3 {'Cl_Central'} 1.0233 0.96375 1.0828高斯0.05 success
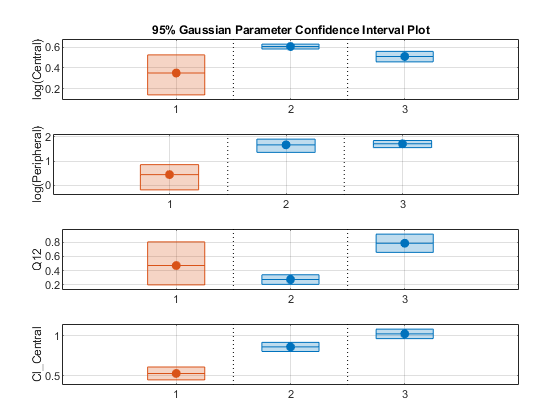
绘制置信区间。如果某个置信区间的估计状态为成功,它以蓝色(第一个默认颜色)绘制。否则,用红色(第二种默认颜色)表示,这表明可能需要对拟合参数进行进一步的研究。如果置信区间为没有有价值的,则该函数绘制一条带有居中十字的红线。如果有任何经过转换的参数,其估计值为0(对于log变换)和1或0(对于probit或logit变换),则不为这些参数估计值绘制置信区间。要查看颜色顺序,请键入get(大的,“defaultAxesColorOrder”).
组从左到右显示的顺序与它们在groupname对象的属性,该属性用于标记x轴。y标签是转换后的参数名。
情节(ciParamUnpooled)
计算合并拟合的置信区间。
ciParamPooled = sbioparameterci(pooledFit);
显示置信区间。
ci2table (ciParamPooled)
ans = 4x7表组名估计置信区间类型Alpha状态______ ______________ ________ __________________ _____________ ___________ pooled {'Central'} 1.6626 1.3287 1.9965高斯0.05估计的pooled {'Peripheral'} 2.687 0.89848 4.8323高斯0.05约束的pooled {'Q12'} 0.44956 0.11445 0.85152高斯0.05约束的pooled {'Cl_Central'} 0.78493 0.59222 0.97764高斯0.05估计
绘制置信区间。组名被标记为“pooled”以表示这种匹配。
情节(ciParamPooled)

把所有的置信区间结果画在一起。默认情况下,每个参数估计的置信区间在单独的轴上绘制。垂直线组参数估计的置信区间是在一个共同拟合中计算的。
ciAll = [ciParamUnpooled;ciParamPooled];情节(ciAll)

您还可以使用“分组”布局在参数估计分组的一个轴上绘制所有置信区间。
情节(ciAll“布局”,“分组”)

在此布局中,您可以指向每个置信区间的中心标记以查看组名。每个估计的参数由一条垂直的黑线分隔。垂直虚线组参数估计的置信区间是在一个共同拟合中计算的。在原始拟合中定义的参数边界用方括号标记。注意由于参数转换,y轴上的不同尺度。例如,的y轴12个是线性尺度,但中央是在对数尺度上,因为它是对数变换。
计算模型预测的置信区间
计算模型预测的95%置信区间,即使用估计参数的模拟结果。
%用于合并拟合ciPredPooled = sbiopredictionci(pooledFit);%用于未合并的拟合ciPredUnpooled = sbiopredictionci(unpooledFit);
绘制模型预测的置信区间
每个组的置信区间在单独的列中绘制,每个响应在单独的行中绘制。受边界限制的置信区间用红色表示。不受边界限制的置信区间用蓝色表示。
情节(ciPredPooled)
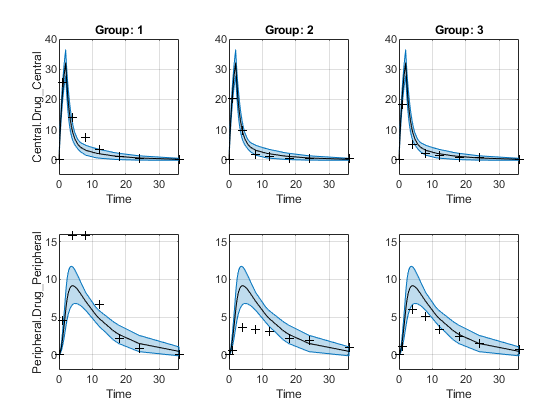
情节(ciPredUnpooled)

输入参数
输出参数
更多关于
参考文献
[1]吴,H.和M.C.尼尔。有界参数的调整置信区间行为遗传学.42 (6), 2012, pp. 886-898。
扩展功能
版本历史
在R2017b中引入
您也可以从以下列表中选择一个网站: