分析生存或可靠性数据
这个例子展示了如何使用截尾分析生命周期数据。在生物或医学应用中,这被称为生存分析,时间可能代表有机体的生存时间或疾病治愈前的时间。在工程应用中,这被称为可靠性分析,时间可能表示设备发生故障的时间。
我们的示例模拟了汽车燃油喷射系统油门失效的时间。
寿命数据的特殊性质
生命周期数据的一些特征区别于其他类型的数据。首先,生命周期总是正值,通常代表时间。第二,有些生命周期可能不能被精确地观察到,因此人们只知道它们大于某些值。第三,通常使用的分布和分析技术是针对生命周期数据的
让我们模拟测试100个节流阀直到失败的结果。如果大多数节流器都有相当长的生命周期,但有一小部分很早就失败了,我们将生成可能观察到的数据。
rng(2,“龙卷风”); 寿命=[wblrnd(15000,3,90,1);wblrnd(1500,3,10,1)];
在本例中,假设我们在压力条件下测试节流阀,因此每一小时的测试相当于现场实际使用的100小时。出于实用原因,通常情况下,可靠性测试在固定时间后停止。在本例中,我们将使用140小时,相当于总共14,00小时0小时的实际服务。一些项目在测试期间失败,而另一些项目在整个140小时内幸存。在实际测试中,后者的时间记录为14000,我们在模拟数据中模拟了这一点。对失败时间进行排序也是常见的做法。
T = 14000;obstime = sort(min(T, lifetime));
我们知道任何通过测试的节流阀最终都会失败,但测试时间不够长,无法观察到它们失败的实际时间。它们的寿命仅已知超过14000小时。据说这些价值观受到了审查。这张图显示,大约40%的数据在14000处被审查。
失败= obstime (obstime < T);nfailed =长度(失败);幸存= obstime (obstime = = T);nsurvived =长度(存活);censored = (obstime >= T);情节([0(大小(obstime)), obstime]”,repmat(1:长度(obstime), 2, - 1),...“颜色”,“b”,“线型”,'-')行([T;3e4],repmat(n失败+(1:n被接受),2,1),“颜色”,“b”,“线型”,“:”); 行([T;T],[0;n失败+n无效],“颜色”,“k”,“线型”,'-')文本(T, 30岁,“<--这里的未知生存时间”)包含(的生存时间); 伊拉贝尔(“观察数量”)

看待分布的方式
在我们检查数据的分布之前,让我们考虑不同的方法来观察概率分布。
概率密度函数(PDF)表示在不同时间发生故障的相对概率。
幸存者函数给出了生存概率作为时间的函数,简单来说就是1减去累积分布函数(1-CDF)。
危险率给出了给定存活时间下的瞬时故障概率。它是PDF除以幸存者函数。在这个例子中,危险率是增加的,这意味着随着时间的推移(老化),项目更容易失败。
概率图是重新缩放的CDF,用于将数据与拟合分布进行比较。
下面是这四种绘图类型的示例,使用威布尔分布进行说明。威布尔分布是寿命数据建模的常见分布。
x=linspace(130000);子地块(2,2,1);地块(x,wblpdf(x,14000,2),x,wblpdf(x,18000,2),x,wblpdf(x,14000,1.1))标题(的概率。密度Fcn”次要情节(2,2,2);情节(x, 1-wblcdf (x, 14000, 2), x, 1-wblcdf (x, 18000, 2), x, 1-wblcdf (1.1 x 14000))标题(“幸存者Fcn”)子地块(2,2,3);wblhaz=@(x,a,b)(wblpdf(x,a,b)/(1-wblcdf(x,a,b));地块(x,wblhaz(x,14000,2),x,wblhaz(x,18000,2),x,wblhaz(x,14000,1.1))标题(“风险率Fcn”)子批次(2,2,4);probplot(“威布尔”wblrnd(14000 2, 40岁,1))标题(“概率图”)
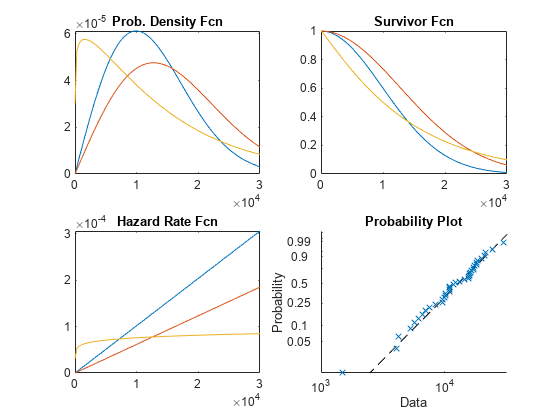
拟合威布尔分布
Weibull分布是指数分布的推广。如果寿命服从指数分布,则它们具有恒定的危险率。这意味着它们不会老化,因为在给定生存到该间隔开始的时间间隔内观察到故障的概率不取决于int的位置erval启动。威布尔分布具有可能增加或减少的危险率。
用于建模寿命数据的其他分布包括对数正态分布、伽马分布和Birnbaum-Saunders分布。
我们将绘制我们的数据的经验累积分布函数,显示在每个可能的生存时间内失败的比例。点曲线给出了这些概率的95%置信区间。
次要情节(1 1 1);[empF x, empFlo, empFup] = ecdf (obstime,“审查”、审查);楼梯(x,empF);保持在;楼梯(x、empFlo、,“:”);楼梯(x, empFup,“:”);持有从包含(“时间”); 伊拉贝尔(“比例失败”);标题(“经验CDF”)

例如,这张图显示,在时间4000时失败的比例约为12%,而此时失败概率的95%置信范围在6%到18%之间。请注意,因为我们的测试只运行了14000小时,所以经验CDF只允许我们计算出超出该限制的失败概率。几乎一半的数据在1.4万份时被审查,因此实证的CDF只上升到0.53左右,而不是1.0。
威布尔分布通常是设备故障的一个很好的模型。这个函数wblfit将Weibull分布拟合到数据,包括带有截尾的数据。计算参数估计值后,我们将使用这些估计值评估拟合Weibull模型的CDF。因为CDF值基于估计参数,我们将计算它们的置信限。
paramEsts = wblfit (obstime,“审查”、审查);[nlogl, paramCov] = wbllike (paramEsts obstime,审查);xx = linspace(1、2 * 500 (T));[wblF, wblFlo wblFup] = wblcdf (xx, paramEsts (1) paramEsts (2), paramCov);
我们可以叠加经验CDF和拟合CDF图,以判断Weibull分布模型对油门可靠性数据的拟合程度。
楼梯(x,empF);保持在处理=情节(xx, wblF“r-”,xx,wblFlo,“:”xx wblFup,“:”);持有从包含(“时间”); 伊拉贝尔(“安装失败概率”);标题(“威布尔模型与经验模型”)

请注意,Weibull模型允许我们预测并计算测试结束后的失败概率。然而,似乎拟合曲线与我们的数据不太匹配。与威布尔模型所预测的相比,我们在时间2000之前有太多的早期失败,因此,在7000到13000次之间的失败次数太少了。这并不奇怪——回想一下,我们就是用这种行为生成数据的。
添加一个光滑的非参数估计
Statistics和Machine Learning Toolbox™提供的预定义函数不包括任何类似这样的早期故障过多的发行版。相反,我们可能想用这个函数,通过经验CDF绘制一条平滑的非参数曲线ksdensity.我们将移除Weibull CDF的置信带,并添加两条曲线,一条带有默认的平滑参数,另一条带有默认值1/3的平滑参数。平滑参数越小,曲线与数据的关系越紧密。
delete(handles(2:end)) [npF,ignore,u] = ksdensity(obstime,xx,)“岑”,审查,“函数”,“提供”); 生产线(xx,npF,“颜色”,‘g’);npF3 = ksdensity (obstime, xx,“岑”,审查,“函数”,“提供”,“宽度”u / 3);线(xx, npF3“颜色”,“米”);xlim (1.3 * T[0])标题(“威布尔和非参数模型与经验模型”)传奇(“经验”,“拟合威布尔”,“非参数,默认”,“非参数,1/3违约”,...“位置”,“西北”);

采用较小平滑参数的非参数估计与数据吻合较好。然而,就像经验CDF一样,不可能在测试结束后外推非参数模型——估计的CDF水平高于最后的观察。
让我们计算这种非参数拟合的风险率,并在数据范围内绘制它。
hazrate = ksdensity (obstime, xx,“岑”,审查,“宽度”u / 3) / (1-npF3);情节(xx, hazrate)标题(“非参数模型的风险率”) xlim ([0, T])
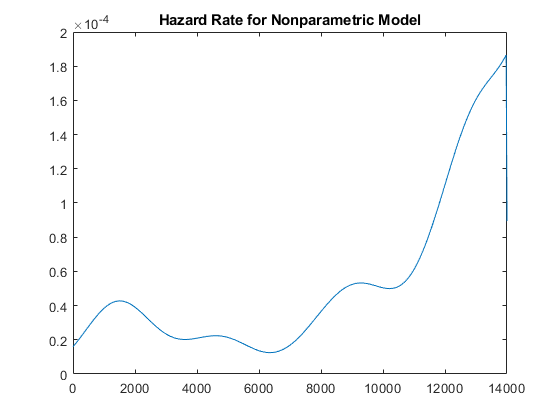
这条曲线有点“浴缸”的形状,危险率在接近2000时很高,然后下降到较低的值,然后再次上升。对于在生命早期(婴儿死亡率)和生命后期(老化)更容易发生故障的组件来说,这是典型的危险率。
还需要注意的是,在非参数模型的最大未删减观测值之上无法估计危险率,图值降至零。
替代模型
对于我们在本例中使用的模拟数据,我们发现Weibull分布并不适合。我们能够用非参数拟合很好地拟合数据,但该模型仅在数据范围内有用。
另一种选择是使用不同的参数分布。统计和机器学习工具箱包括用于其他常见寿命分布的函数,如对数正态分布、伽马和Birnbaum-Saunders,以及许多在寿命模型中不常用的其他分布。您还可以定义自定义参数模型并使其适合于生命周期数据,如拟合自定义单变量分布,第2部分的例子。
另一种选择是混合使用两种参数分布——一种表示早期失败,另一种表示其余分布。混合分布的拟合描述在拟合自定义单变量分布的例子。
你也可以从以下列表中选择一个网站:
