贝叶斯优化绘图函数
内置的绘图功能
有两组内置的绘图函数。
| 模型图-D时应用≤ 2. | 描述 |
|---|---|
@plotAcquisitionFunction |
绘制采集函数曲面。 |
@plotConstraintModels |
绘制每个约束模型曲面。负值表示可行点。 也画一个P(可行的)表面。 还绘制误差模型,如果它存在,它的范围是 绘制误差= 2*概率(误差)- 1。 |
@plotObjectiveEvaluationTimeModel |
绘制目标函数评估时间模型曲面。 |
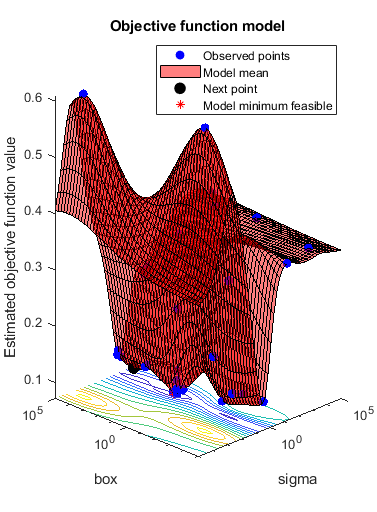
@绘图对象模型 |
画出 |
| 跟踪图-适用于所有D | 描述 |
|---|---|
@plotObjective |
绘制每个观察到的函数值与函数求值次数的关系图。 |
@plotObjectiveEvaluationTime |
绘制每个观察到的函数求值运行时与函数求值次数的关系图。 |
@plotMinObjective |
绘制观察和估计的最小功能值与功能评估数量的关系图。 |
@plotElapsedTime |
绘制三条曲线:优化的总运行时间、总函数评估时间、总建模和点选择时间,所有这些都与函数评估的数量相比较。 |
笔记
当存在耦合约束时,迭代显示和绘图功能会产生违反直觉的结果,例如:
A.最低目标可以增加。
优化可以声明一个问题不可行,即使它显示了一个较早的可行点。
这种行为的原因是,关于某个点是否可行的决策可能会随着优化的进行而改变。贝耶斯波特确定其约束模型的可行性,并且该模型会随着贝耶斯波特评估点。因此,当最小点后来被认为不可行时,“最小目标”图可以增加,迭代显示可以显示一个后来被认为不可行的可行点。
自定义绘图函数语法
自定义绘图函数与自定义输出函数具有相同的语法(参见贝叶斯优化输出函数):
停止=绘图乐趣(结果、状态)
贝耶斯波特通过了后果和状态函数的变量。你的函数返回停止,你设置为真正的停止迭代,或者错误的继续迭代。
后果是类的对象吗BayesianOptimization包含有关计算的可用信息。
状态有以下可能的值:
“初始”—贝耶斯波特即将开始迭代。请使用此状态设置绘图或执行其他初始化。“迭代”—贝耶斯波特刚刚完成一个迭代。通常,在这种状态下执行大多数绘图或其他计算。“完成”—贝耶斯波特刚刚完成了最后的迭代。清理地块,否则为地块功能关闭做好准备。
创建自定义打印函数
此示例显示如何为创建自定义打印函数贝耶斯波特.进一步说明了如何使用用户数据财产BayesianOptimization对象。
问题陈述
问题是找到支持向量机(SVM)分类的参数以最小化交叉验证损失。具体型号与中的相金宝app同用bayesopt优化交叉验证SVM分类器因此,目标函数本质上是相同的,只是它也计算用户数据,在这种情况下,支持向量机模型中适合当前参数的支持向量数。金宝app
创建一个自定义绘图函数,在优化过程中绘制支持向量机模型中的支持向量的数量。金宝app为了让plot函数访问支持向量的数量,创建第三个输出,金宝app用户数据,以返回支持向量的数目。金宝app
目标函数
创建一个目标函数,用于计算固定交叉验证分区的交叉验证损失,并返回结果模型中的支持向量数。金宝app
函数[f,viol,nsupp] = mysvmminfn(x,cdata,grp,c)“KernelFunction”,“rbf”,...“KernelScale”x.sigma,“BoxConstraint”,x.box);f=kfoldLoss(crossval(SVMModel,“CVPartition”(c));viol=[];nsupp=总和(SVMModel.IsSupport金宝appVector);终止
自定义绘制函数
创建使用中计算的信息的自定义绘图函数用户数据.在找到最佳目标函数的情况下,绘制当前约束数量和模型约束数量的函数图。
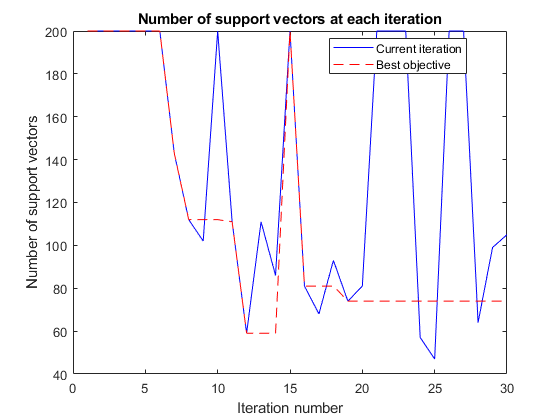
函数停止= svmsuppvec(结果,状态)持久的hs nbest besthist nsuptrace stop=false;开关状态情况下“初始”hs=数字;besthist=[];nbest=0;NsupTrace=[];情况下“迭代”图(hs)nsupp=results.UserDataTrace{end};%从UserDataTrace属性获取nsupp。nsupTrace(end+1)=nsupp;在vector中累加nsupp值。如果(results. objecvetrace (end) == min(results. objecvetrace)))%电流最好nb = nsupp;终止besthist = (besthist, nb);阴谋(1:长度(nsupptrace) nsupptrace,“b”,1:长度(最佳历史),最佳历史,“r——”)包含的迭代次数伊拉贝尔‘支持向量数’金宝app标题“每次迭代的支持向量数金宝app”传奇(“当前迭代”,“最好的目标”,“位置”,“最好的”) drawnow终止
建立模型
为每个职业生成10个基点。
rng违约grnpop = mvnrnd((1,0)、眼睛(2),10);redpop = mvnrnd([0, 1],眼(2),10);
生成每个类的100个数据点。
redpts=零(100,2);grnpts=redpts;对于i=1:100 GRNPT(i,:)=mvnrnd(grnpop(randi(10),:),eye(2)*0.02);redpts(i,:)=mvnrnd(redpop(randi(10),:),eye(2)*0.02);终止
将数据放入一个矩阵中,并生成一个向量玻璃钢标记每个点的类别。
cdata=[grnpts;redpts];grp=one(200,1);%绿色标签1,红色标签-1grp(101:200)=-1;
使用默认的支持向量机参数检查所有数据的基本分类。
SVMModel=fitcsvm(cdata、grp、,“KernelFunction”,“rbf”,“类名”,[-1 1]);
设置一个分区来修复交叉验证。没有这个步骤,交叉验证是随机的,因此目标函数是不确定的。
c=CVD(200,“KFold”10);
检查原始拟合模型的交叉验证准确性。
损失= kfoldLoss (fitcsvm (grp cdata,“CVPartition”c...“KernelFunction”,“rbf”,“BoxConstraint”,SVMModel.BoxConstraints(1),...“KernelScale”, SVMModel.KernelParameters.Scale))
损失= 0.1350
为优化准备变量
目标函数接受输入z = [rbf_sigma boxconstraint]并返回的交叉验证损失值Z.以Z作为正变量,在1e-5和1e5.选择一个广泛的范围,因为你不知道哪些值可能是好的。
西格玛=优化变量(“西格玛”,[1e-5,1e5],“转换”,“日志”); box=优化变量(“盒子”,[1e-5,1e5],“转换”,“日志”);
设置Plot函数并调用优化器
搜索最佳参数(σ,盒子)使用贝耶斯波特.对于再现性,请选择“expected-improvement-plus”采集函数。默认的采集函数取决于运行时间,因此它可以给出不同的结果。
绘制支持向量的数量作为迭代数的函数,并金宝app绘制找到的最佳参数的支持向量的数量。
obj=@(x)mysvmminfn(x,cdata,grp,c);results=bayesopt(obj,[sigma,box],...“IsObjectiveDeterministic”符合事实的“详细”0,...“AcquisitionFunctionName”,“expected-improvement-plus”,...“PlotFcn”, {@svmsuppvec、@plotObjectiveModel @plotMinObjective})
结果= BayesianOptimization属性:ObjectiveFcn: @ (x) mysvmminfn (x, cdata, grp, c) VariableDescriptions: [1 x2 optimizableVariable]选项:[1 x1 struct] MinObjective: 0.0750 XAtMinObjective: [1 x2表]MinEstimatedObjective: 0.0750 XAtMinEstimatedObjective: [1 x2表]NumObjectiveEvaluations: 30 TotalElapsedTime: 65.3092 NextPoint:[1 x2表]XTrace: [30 x2表]ObjectiveTrace: [30 x1双]ConstraintsTrace: [] UserDataTrace: {30 x1细胞}ObjectiveEvaluationTimeTrace: [30 x1双]IterationTimeTrace: [30 x1双]ErrorTrace: [30 x1双]FeasibilityTrace: [30 x1逻辑]FeasibilityProbabilityTrace: [30 x1双]IndexOfMinimumTrace: [30 x1双]ObjectiveMinimumTrace:[30x1 double] EstimatedObjectiveMinimumTrace: [30x1 double]

相关的话题
你也可以从以下列表中选择一个网站:
