优化交叉验证的支持向量机分类器bayesopt
此示例显示如何使用该示例如何优化SVM分类bayesopt函数。分类工作在一个高斯混合模型的点的位置。在统计学习的要素, Hastie, Tibshirani, and Friedman(2009),第17页描述了这个模型。该模型首先为“绿色”类生成10个基点,分布为均值(1,0)和单位方差的2-D独立正态分布。它还为“红色”类生成10个基点,分布为均值(0,1)和单位方差的2-D独立正态分布。对于每个职业(绿色和红色),生成100个随机点数如下:
选择一个基点米随机均匀地均匀。
生成一个独立的具有二维正态分布的随机点米和方差I / 5,其中我是2×2识别矩阵。在此示例中,使用方差I / 50来更清楚地显示优化的优点。
在生成100个绿色和100个红色点后,使用fitcsvm..然后使用bayesopt对得到的支持向量机模型参数进行交叉验证优化。
生成点和分类器
为每个职业生成10个基点。
RNG.默认的GRNPOP = MVNRND([1,0],眼睛(2),10);Redpop = mvnrnd([0,1],眼睛(2),10);
查看基点。
情节(grnpop (: 1) grnpop (:, 2),“去”抱紧上绘图(REDPOP(:,1),REDPOP(:,2),“罗”抱紧关闭
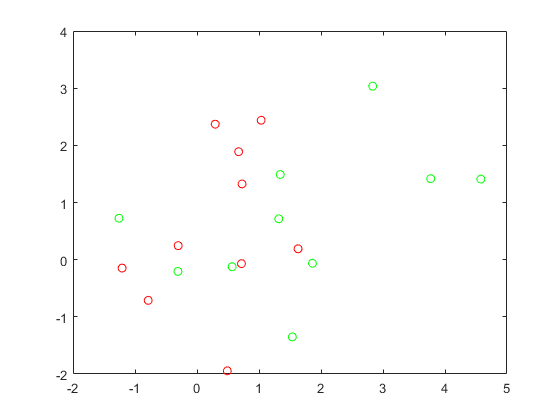
由于一些红色基点接近绿色基点,因此可以难以仅基于位置对数据点进行分类。
生成每个类的100个数据点。
Redpts = 0 (100,2);为i = 1:10 0 grnpts(我:)= mvnrnd (grnpop(兰迪(10):)、眼睛(2)* 0.02);redpts(我)= mvnrnd (redpop(兰迪(10):)、眼睛(2)* 0.02);结束
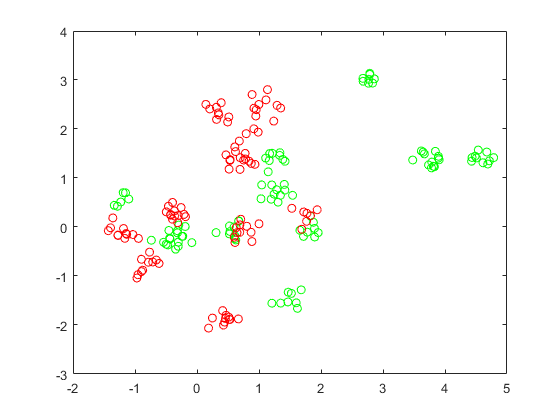
查看数据点。
图绘制(grnpts (: 1), grnpts (:, 2),“去”抱紧上绘图(已删除(:,1),已删除(:,2),“罗”抱紧关闭
准备分类数据
将数据放入一个矩阵,并生成一个向量grp标签每个点的类。
cdata = [grnpts; redpts];grp = 1 (200 1);%绿色标签1,红色标签-1grp (101:200) = 1;
准备交叉验证
为交叉验证设置分区。此步骤修复优化在每个步骤中使用的列车和测试集。
c = cvpartition (200“KFold”,10);
为贝叶斯优化准备变量
建立一个接受输入的函数z = [rbf_sigma,boxconstraint]并返回的交叉验证损失值z.取z作为正的,对数变换的变量1 e-5和1 e5.选择宽范围,因为您不知道哪个值可能是好的。
σ= optimizableVariable (“σ”(1 e-5, 1 e5),'变换',“日志”);盒= optimizableVariable (“盒子”(1 e-5, 1 e5),'变换',“日志”);
目标函数
此功能处理可计算参数的交叉验证丢失[sigma,box].有关详细信息,请参阅kfoldLoss.
bayesopt通过变量z将目标函数转换为单行表。
minfn = @ (z) kfoldLoss (fitcsvm (grp cdata,'cvpartition',c,...'骨箱',“rbf”,“BoxConstraint”,z.box,...“KernelScale”,z.sigma));
优化分类器
搜索最佳参数[sigma,box]使用bayesopt.为了再现性,选择'预期改善加'采集功能。默认的获取函数取决于运行时,因此可以给出不同的结果。
结果= bayesopt (minfn,σ,盒子,“IsObjectiveDeterministic”,真的,...“AcquisitionFunctionName”,'预期改善加')
|=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar |σ盒| | | | |结果运行时| | | (estim(观察) .) | | | |=====================================================================================================| | 1 |最好的| 0.61 | 0.49723 | 0.61 | 0.61 | 0.00013375 | 13929 | | 2 |的| 0.345 | 0.23801 | 0.345 | 0.345 | 24526 | 1.936 | | 3 |接受| 0.61 | 0.27614 | 0.345 | 0.345 | 0.0026459 | 0.00084929 | | 4 |接受| 0.345 | 0.37522 | 0.345 | 0.345 | 3506.3 | 6.7427 e-05 | | 5 |接受| 0.345 | 0.23259 | 0.345 | 0.345 | 9135.2 | 571.87 | 0.345 | | | 6 |接受0.18231 | 0.345 | 0.345 | 99701 | 10223 | | 7 | Best | 0.295 | 0.21768 | 0.295 | 0.295 | 455.88 | 9957.4 | | 8 | Best | 0.24 | 1.493 | 0.24 | 0.24 | 31.56 | 99389 | | 9 | Accept | 0.24 | 1.8306 | 0.24 | 0.24 | 10.451 | 64429 | | 10 | Accept | 0.35 | 0.29761 | 0.24 | 0.24 | 17.331 | 1.0264e-05 | | 11 | Best | 0.23 | 1.1237 | 0.23 | 0.23 | 16.005 | 90155 | | 12 | Best | 0.1 | 0.28838 | 0.1 | 0.1 | 0.36562 | 80878 | | 13 | Accept | 0.115 | 0.15901 | 0.1 | 0.1 | 0.1793 | 68459 | | 14 | Accept | 0.105 | 0.25403 | 0.1 | 0.1 | 0.2267 | 95421 | | 15 | Best | 0.095 | 0.16714 | 0.095 | 0.095 | 0.28999 | 0.0058227 | | 16 | Best | 0.075 | 0.21326 | 0.075 | 0.075 | 0.30554 | 8.9017 | | 17 | Accept | 0.085 | 0.23925 | 0.075 | 0.075 | 0.41122 | 4.4476 | | 18 | Accept | 0.085 | 0.31168 | 0.075 | 0.075 | 0.25565 | 7.8038 | | 19 | Accept | 0.075 | 0.26502 | 0.075 | 0.075 | 0.32869 | 18.076 | | 20 | Accept | 0.085 | 0.20048 | 0.075 | 0.075 | 0.32442 | 5.2118 | |=====================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | sigma | box | | | result | | runtime | (observed) | (estim.) | | | |=====================================================================================================| | 21 | Accept | 0.3 | 0.13136 | 0.075 | 0.075 | 1.3592 | 0.0098067 | | 22 | Accept | 0.12 | 0.23338 | 0.075 | 0.075 | 0.17515 | 0.00070913 | | 23 | Accept | 0.175 | 0.24124 | 0.075 | 0.075 | 0.1252 | 0.010749 | | 24 | Accept | 0.105 | 0.18186 | 0.075 | 0.075 | 1.1664 | 31.13 | | 25 | Accept | 0.1 | 0.17713 | 0.075 | 0.075 | 0.57465 | 2013.8 | | 26 | Accept | 0.12 | 0.13144 | 0.075 | 0.075 | 0.42922 | 1.1602e-05 | | 27 | Accept | 0.12 | 0.1642 | 0.075 | 0.075 | 0.42956 | 0.00027218 | | 28 | Accept | 0.095 | 0.18907 | 0.075 | 0.075 | 0.4806 | 13.452 | | 29 | Accept | 0.105 | 0.18856 | 0.075 | 0.075 | 0.19755 | 943.87 | | 30 | Accept | 0.205 | 0.19236 | 0.075 | 0.075 | 3.5051 | 93.492 |
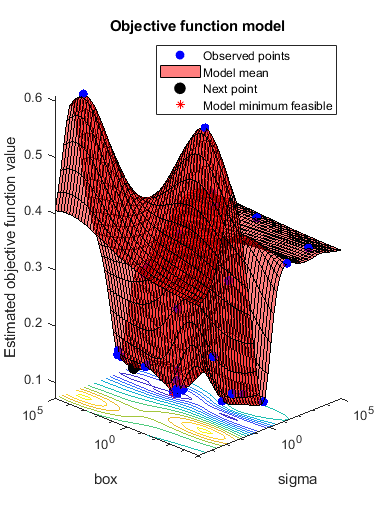
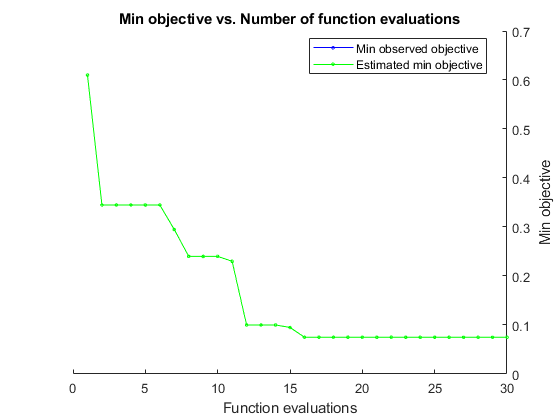
__________________________________________________________ 优化完成。maxobjective达到30个。总函数计算:30总运行时间:62.3158秒总目标函数计算时间:10.693sigma箱_______ ______ 0.30554 8.9017观测目标函数值= 0.075估计目标函数值= 0.075函数评价时间= 0.21326最佳估计可行点(根据模型):sigma箱_______ ______ 0.32869 18.076估计目标函数值= 0.075估计函数评价时间= 0.23015
results = BayesianOptimization with properties: ObjectiveFcn: [function_handle] VariableDescriptions: [1x2 optimizableVariable] Options: [1x1 struct] MinObjective: 0.0750 XAtMinObjective: [1x2 table] minestimatedobjobjective: 0.0750 xatminestimatedobjobjective: [1x2 table] numobjectiveevalues:30 TotalElapsedTime: 62.3158 NextPoint:[1 x2表]XTrace: [30 x2表]ObjectiveTrace: [30 x1双]ConstraintsTrace: [] UserDataTrace: {30 x1细胞}ObjectiveEvaluationTimeTrace: [30 x1双]IterationTimeTrace: [30 x1双]ErrorTrace: [30 x1双]FeasibilityTrace: [30 x1逻辑]FeasibilityProbabilityTrace: [30 x1双]IndexOfMinimumTrace: [30 x1双]ObjectiveMinimumTrace:[30x1 double] EstimatedObjectiveMinimumTrace: [30x1 double]
利用这些结果来训练一个新的、优化的SVM分类器。
z(1)=结果.xatminobjective.sigma;z(2)= execue.xatminobjective.box;svmmodel = fitcsvm(cdata,grp,'骨箱',“rbf”,...“KernelScale”,z(1),“BoxConstraint”, z (2));
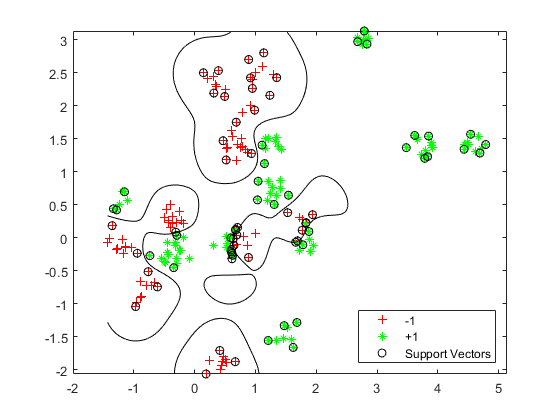
绘制分类边界。要可视化支持向量分类器,可以在网格金宝app上预测分数。
d = 0.02;[x1grid,x2grid] = meshgrid(min(cdata(:,1)):d:max(cdata(:,1)),...min(cdata(:,2)):d:max(cdata(:,2)));xgrid = [x1grid(:),x2grid(:)];[〜,得分] =预测(SVMMODEL,XGRID);h = nan(3,1);%预先配置图;h (1:2) = gscatter (cdata (: 1), cdata (:, 2), grp,“rg”,'+ *');持有上h(3)= plot(cdata(svmmodel.iss金宝appupportvector,1),...cdata (SVMModel.I金宝appsSupportVector, 2),'ko');轮廓(x1Grid x2Grid,重塑(分数(:,2),大小(x1Grid)), [0 0),'K');传奇(h, {'-1','+1','金宝app支持vectors'},'位置',“东南”);轴平等的持有关闭
评估新数据的准确性
生成并分类一些新的数据点。
GRNOBJ = GMDistribution(GRNPOP,.2 * EYE(2));Redobj = Gmdistribution(Redpop,.2 *眼睛(2));newdata =随机(grnobj,10);newdata = [newdata;随机(redobj,10)];grpdata = a那么多(20,1);GRPDATA(11:20)= -1;% red = -1v =预测(svmmodel,newdata);g = nan(7,1);图;h (1:2) = gscatter (cdata (: 1), cdata (:, 2), grp,“rg”,'+ *');持有上h (3:4) = gscatter (newData (: 1), newData (:, 2), v,'MC','**');h(5) =情节(cdata (SVMModel.IsSu金宝apppportVector, 1),...cdata (SVMModel.I金宝appsSupportVector, 2),'ko');轮廓(x1Grid x2Grid,重塑(分数(:,2),大小(x1Grid)), [0 0),'K');传奇(h (1:5), {“1”(培训),“+ 1(培训)”,“1”(分类),...“+ 1(分类)”,'金宝app支持vectors'},'位置',“东南”);轴平等的持有关闭

查看哪些新数据点被正确分类。圈出红色的正确分类点,黑色中的错误分类点。
mydiff = (v == grpData);%分类正确图;h (1:2) = gscatter (cdata (: 1), cdata (:, 2), grp,“rg”,'+ *');持有上h (3:4) = gscatter (newData (: 1), newData (:, 2), v,'MC','**');h(5) =情节(cdata (SVMModel.IsSu金宝apppportVector, 1),...cdata (SVMModel.I金宝appsSupportVector, 2),'ko');轮廓(x1Grid x2Grid,重塑(分数(:,2),大小(x1Grid)), [0 0),'K');为II = mydiff%在正确的点周围绘制红色方块h(6) =情节(newData (ii, 1), newData (ii, 2),“rs”,'Markersize',12);结束为II =不是(mydiff)%在错误点周围绘制黑色方块h(7) =情节(newData (ii, 1), newData (ii, 2),“ks”,'Markersize',12);结束传奇(h, {“1”(培训),“+ 1(培训)”,“1”(分类),...“+ 1(分类)”,'金宝app支持vectors',正确分类的,...'错误分类'},'位置',“东南”);持有关闭

另请参阅
相关主题
您还可以从以下列表中选择一个网站:
