bayesopt
使用贝叶斯优化选择最优的机器学习超参数
描述
例子
创建一个BayesianOptimization对象使用bayesopt
这个例子展示了如何创建一个BayesianOptimization通过使用bayesopt尽量减少交叉验证的损失。
优化了KNN分类器的超参数电离层,即寻找最小化交叉验证损失的KNN超参数。有bayesopt最小化以下超参数:
最近的邻居大小从1到30
距离函数
“chebychev”,“欧几里得”,闵可夫斯基的.
为了重现性,设置随机种子,设置分区,并设置AcquisitionFunctionName选择“预期改善加成”.若要抑制迭代显示,请设置“详细”来0.通过分区c和拟合数据X和Y到目标函数有趣的通过创建有趣的作为包含该数据的匿名函数。看到参数化功能.
负载电离层rng默认的num = optimizableVariable (“不”(1、30),“类型”,“整数”);dst = optimizableVariable (dst的, {“chebychev”,“欧几里得”,闵可夫斯基的},“类型”,“分类”);c = cvpartition (351“Kfold”5);有趣= @ (x) kfoldLoss (fitcknn (x, Y,“CVPartition”c“NumNeighbors”x.n,...“距离”char (x.dst),“NSMethod”,“详尽”));结果= bayesopt(有趣,(num, dst),“详细”0,...“AcquisitionFunctionName”,“预期改善加成”)
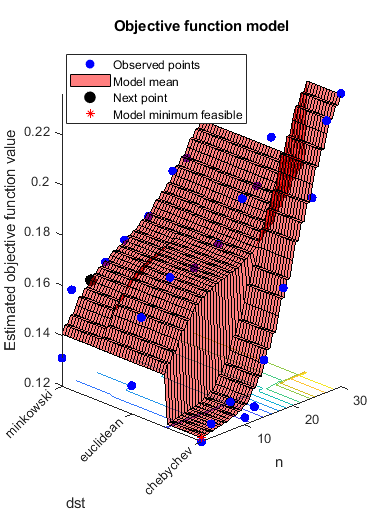
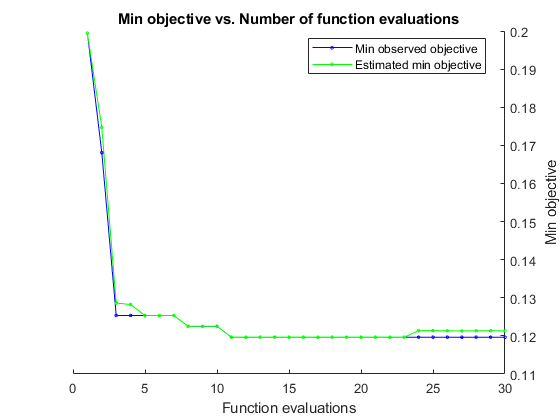
results = BayesianOptimization with properties: ObjectiveFcn: [function_handle] VariableDescriptions: [1x2 optimizableVariable] Options: [1x1 struct] MinObjective: 0.1197 XAtMinObjective: [1x2 table] minestimatedobjobjective: 0.1213 xatminestimatedobjobjective: [1x2 table] numobjectiveevalues:30 TotalElapsedTime: 91.4349 NextPoint:[1 x2表]XTrace: [30 x2表]ObjectiveTrace: [30 x1双]ConstraintsTrace: [] UserDataTrace: {30 x1细胞}ObjectiveEvaluationTimeTrace: [30 x1双]IterationTimeTrace: [30 x1双]ErrorTrace: [30 x1双]FeasibilityTrace: [30 x1逻辑]FeasibilityProbabilityTrace: [30 x1双]IndexOfMinimumTrace: [30 x1双]ObjectiveMinimumTrace:[30x1 double] EstimatedObjectiveMinimumTrace: [30x1 double]
耦合约束的贝叶斯优化
耦合约束是只能通过对目标函数求值来求值的约束。在这种情况下,目标函数是支持向量机模型的交叉验证损失。耦合约束是支持向量的个数不超过100。金宝app模型细节已经在里面了使用贝叶斯算法优化交叉验证的SVM分类器.
创建用于分类的数据。
rng默认的grnpop = mvnrnd((1,0)、眼睛(2),10);redpop = mvnrnd([0, 1],眼(2),10);redpts = 0 (100 2);grnpts = redpts;为i = 1:10 0 grnpts(我:)= mvnrnd (grnpop(兰迪(10):)、眼睛(2)* 0.02);redpts(我)= mvnrnd (redpop(兰迪(10):)、眼睛(2)* 0.02);结束cdata = [grnpts; redpts];grp = 1 (200 1);grp (101:200) = 1;c = cvpartition (200“KFold”10);σ= optimizableVariable (“σ”(1 e-5, 1 e5),“转换”,“日志”);盒= optimizableVariable (“盒子”(1 e-5, 1 e5),“转换”,“日志”);
目标函数是用于划分的SVM模型的交叉验证损失c.这个coupled constraint is the number of support vectors minus 100.5. This ensures that 100 support vectors give a negative constraint value, but 101 support vectors give a positive value. The model has 200 data points, so the coupled constraint values range from -99.5 (there is always at least one support vector) to 99.5. Positive values mean the constraint is not satisfied.
函数[目标,约束]=mysvmfun(x,cdata,grp,c)SVMModel=fitcsvm(cdata,grp,“KernelFunction”,“rbf”,...“BoxConstraint”x.box,...“KernelScale”,x.sigma);cvModel=crossval(SVMModel,“CVPartition”c);目标= kfoldLoss (cvModel);约束=总和(SVMModel.IsSupportVect金宝appor) -100.5;
通过分区c和拟合数据cdata和grp到目标函数有趣的通过创建有趣的作为包含该数据的匿名函数。看到参数化功能.
有趣= @ (x) mysvmfun (x, cdata, grp, c);
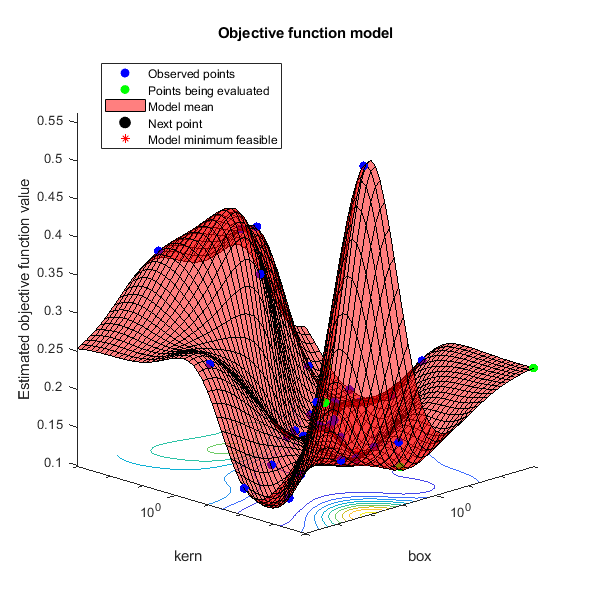
设置NumCoupledConstraints来1优化器知道存在耦合约束。设置绘制约束模型的选项。
结果= bayesopt(有趣,σ,盒子,“IsObjectiveDeterministic”,真的,...“NumCoupledConstraints”,1,“PlotFcn”,...{@plotMinObjective, @plotConstraintModels},...“AcquisitionFunctionName”,“预期改善加成”,“详细”, 0);
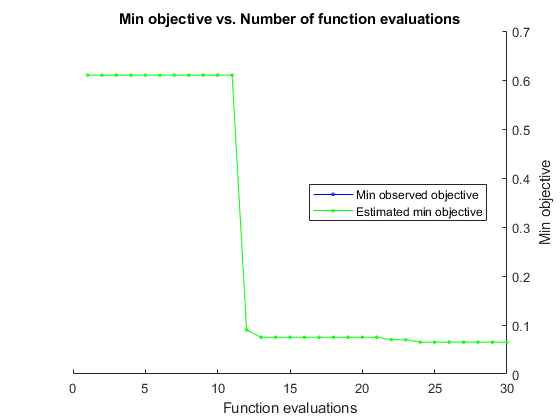
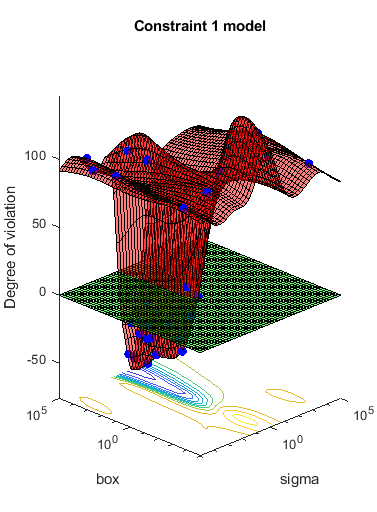
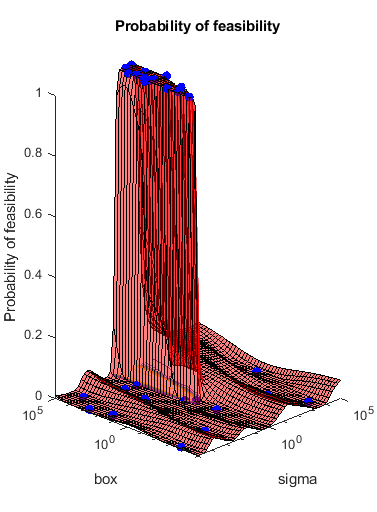
大多数点导致支持向量的数目不可行。金宝app
平行的贝叶斯优化
利用并行目标函数评价提高贝叶斯优化的速度。
为贝叶斯优化准备变量和目标函数。
目标函数是电离层数据的交叉验证错误率,这是一个二元分类问题。使用fitcsvm作为分类器,用BoxConstraint和核尺度作为优化的参数。
负载电离层盒= optimizableVariable (“盒子”(1的军医,1 e3),“转换”,“日志”);kern = optimizableVariable (“仁”(1的军医,1 e3),“转换”,“日志”);var =(盒子,kern);有趣= @ (var) kfoldLoss (fitcsvm (X, Y,“BoxConstraint”vars.box,“KernelScale”vars.kern,...“Kfold”5));
使用并行贝叶斯优化来搜索给出最低交叉验证误差的参数。
结果= bayesopt (var,有趣“UseParallel”,真正的);
复制目标函数给工人…完成向工人复制目标函数。
|===============================================================================================================| | Iter | |活跃Eval客观客观| | | BestSoFar | BestSoFar盒| | kern | | |工人结果| | |运行时|(观察)| (estim) | | ||===============================================================================================================| | 1 | 2 |接受| 0.2735 | 0.56171 | 0.13105 | 0.13108 | 0.0002608 | 0.2227 | | 2 | 2 |接受| 0.35897 | 0.4062 | 0.13105 | 0.13108 | 3.6999 | 344.01 | | 3 | 2 |接受| 0.13675 | 0.42727 | 0.13105 | 0.13108 | 0.33594 | 0.39276 | |4 | 2 |接受| 0.35897 | 0.4453 | 0.13105 | 0.13108 | 0.014127 | 449.58 | | 5 | 2 |最佳| 0.13105 | 0.45503 | 0.13105 | 0.13108 | 0.29713 | 1.0859 |
| 6 | 6 |接受| 0.35897 | 0.16605 | 0.13105 | 0.13108 | 8.1878 | 256.9 |
| 7 | 5 |最佳| 0.11396 | 0.51146 | 0.11396 | 0.11395 | 8.7331 | 0.7521 | | 8 | 5 b|接受| 0.14245 | 0.24943 | 0.11396 | 0.11395 | 0.0020774 | 0.022712 |
| 9 | 6 |最佳| 0.10826 | 4.0711 | 0.10826 | 0.10827 | 0.0015925 | 0.0050225 |
| 10 | 6 |接受| 0.25641 | 16.265 | 0.10826 | 0.10829 | 0.00057357 | 0.00025895 |
|11 | 6 |接受| 0.1339 | 15.581 | 0.10826 | 0.10829 | 1.4553 | 0.011186|
| 12 | 6 |接受| 0.16809 | 19.585 | 0.10826 | 0.10828 | 0.26919 | 0.00037649 |
| 13 | 6 |接受| 0.20513 | 18.637 | 0.10826 | 0.10828 | 369.59 | 0.099122 |
| 14 | 6 |接受| 0.12536 | 0.11382 | 0.10826 | 0.10829 | 5.7059 | 2.5642 |
| 15 | 6 |接受| 0.13675 | 2.63 | 0.10826 | 0.10828 | 984.19 | 2.2214 |
|16 | 6 |接受| 0.12821 | 2.0743 | 0.10826 | 0.11144 | 0.0063411 | 0.0090242|
| 17 | 6 |接受| 0.1339 | 0.1939 | 0.10826 | 0.11302 | 0.00010225 | 0.0076795 |
|18 | 6 |接受| 0.12821 | 0.20933 | 0.10826 | 0.11376 | 7.7447 | 1.2868|
| | 4 | 19日接受| 0.55556 | 17.564 | 0.10826 | 0.10828 | 0.0087593 | 0.00014486 | | 20 | 4 |接受| 0.1396 | 16.473 | 0.10826 | 0.10828 | 0.054844 | 0.004479 | |===============================================================================================================| | Iter | |活跃Eval客观客观| | | BestSoFar | BestSoFar |box | kern | | | workers | result | | runtime | (observed) | (estim.) | | | |===============================================================================================================| | 21 | 4 | Accept | 0.1339 | 0.17127 | 0.10826 | 0.10828 | 9.2668 | 1.2171 |
| 22 | 4 |接受| 0.12821 | 0.089065 | 0.10826 | 0.10828 | 12.265 | 8.5455 |
| 23 | 4 |接受| 0.12536 | 0.073586 | 0.10826 | 0.10828 | 1.3355 | 2.8392 |
| 24 | 4 |接受| 0.12821 | 0.08038 | 0.10826 | 0.10828 | 131.51 | 16.878 |
| 25 | 3 |接受| 0.11111 | 10.687 | 0.10826 | 0.10867 | 1.4795 | 0.041452 | | 26 | 3 |接受| 0.13675 | 0.18626 | 0.10826 | 0.10867 | 2.0513 | 0.70421 |
| 27 | 6 |接受| 0.12821 | 0.078559 | 0.10826 | 0.10868 | 980.04 | 44.19 |
| 28 | 5 |接受| 0.33048 | 0.089844 | 0.10826 | 0.10843 | 0.41821 | 10.208 | | 29 | 5 |接受| 0.16239 | 0.12688 | 0.10826 | 0.10843 | 172.39 | 141.43 |
| 30 | 5 |接受| 0.11966 | 0.14597 | 0.10826 | 0.10846 | 639.15 | 14.75 |
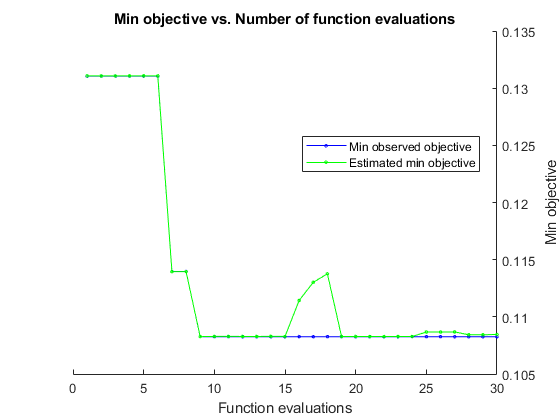
__________________________________________________________优化完成。MaxObjectiveEvaluations达到30。总功能评估:30总运行时间:48.2085秒。总目标功能评估时间:128.3472最佳观察可行点:box kern____________;0.0015925 0.0050225观察到的目标功能v值=0.10826估计目标函数值=0.10846函数评估时间=4.0711最佳估计可行点(根据模型):box-kernuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu
返回贝叶斯模型中的最佳可行点结果通过使用bestPoint函数。使用默认条件min-visited-upper-confidence-interval,确定最佳可行点为使目标函数值上置信区间最小的访问点。
zb = bestPoint(结果)
zb =1×2表框kern _________ _________ 0.0015925 0.0050225
表兹贝斯特的最佳估计值“BoxConstraint”和“KernelScale”名称-值对参数。使用这些值来训练一个新的优化分类器。
Mdl = fitcsvm (X, Y,“BoxConstraint”zbest.box,“KernelScale”, zbest.kern);
观察最优参数在Mdl.
Mdl.BoxConstraints (1)
ans = 0.0016
Mdl.KernelParameters.Scale
ans = 0.0050
输入参数
输出参数
更多关于
提示
扩展功能
你也可以从以下列表中选择一个网站:
