Kfoldloss.
交叉验证分类模型的分类损失
描述
例子
估计交叉验证的分类错误
加载电离层数据集。
负载电离层
种植分类树。
树= fitctree (X, Y);
使用10倍交叉验证对分类树进行交叉验证。
cvtree = crossval(树);
估计交叉验证的分类误差。
L = kfoldLoss (cvtree)
L = 0.1083.
估计交叉验证的分类错误
加载电离层数据集。
负载电离层
使用Adaboostm1培训100个决策树的分类集合。将树桩指定为弱学习者。
t = templatetree(“MaxNumSplits”1);实体= fitcensemble (X, Y,'方法',“AdaBoostM1”,“学习者”t);
使用10倍交叉验证对集成进行交叉验证。
cvens = crossval(ens);
估计交叉验证的分类误差。
l = kfoldloss(cvens)
L = 0.0655
查找使用的最佳树木数量Kfoldloss.
培训交叉验证的广义添加剂模型(GAM),10倍。然后,使用Kfoldloss.计算累积交叉验证分类误差(十进制误分类率)。利用误差来确定每个预测器的最佳树数(预测器的线性项)和每个交互项的最佳树数。
或者,您可以找到最佳值Fitcgam.使用该名称 - 值参数bayesopt函数。例如,请参见使用Bayesopt优化交叉验证的GAM.
加载电离层数据集。此数据集具有34个预测器和351个雷达返回的二进制响应,无论是坏的吗('B')或好('G').
负载电离层
使用默认的交叉验证选项创建一个交叉验证的GAM。指定“CrossVal”名称 - 值参数为“上”.指定包含所有可用的交互术语p-Values不大于0.05。
rng (“默认”)%的再现性CVMdl = fitcgam (X, Y,“CrossVal”,“上”,“互动”,'全部','maxpvalue', 0.05);
如果您指定“模式”作为'累积'为Kfoldloss.然后,该函数返回累积误差,这是每个折叠使用相同数量的树木获得的所有折叠的平均错误。显示每个折叠的树数。
CVMdl。NumTrainedPerFold
ans =.结构与字段:InteractionTrees: [1 2 2 2 2 2]
Kfoldloss.可以使用多达59个预测树和一个交互树计算累积误差。
绘制累积的、经过交叉验证的10倍的分类错误(误分类率十进制)。指定'internalideraction'作为假将相互作用项从计算中排除。
L_noInteractions = kfoldLoss (CVMdl,“模式”,'累积','internalideraction',错误的);图绘图(0:min(cvmdl.numtrainerperfold.predictortrees),l_nointactions)
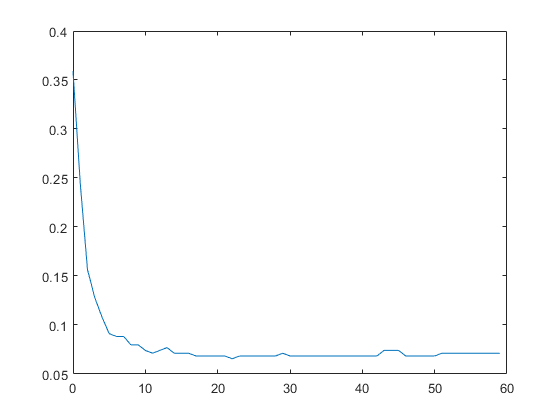
第一个元素L_noInteractions是仅使用拦截(常量)术语获得的所有折叠的平均误差。这 (J + 1) th元素的L_noInteractions是使用截距项和第一个获得的平均错误J每个线性术语的预测树木。绘制累积损失允许您监视错误如何随着GAM中的预测格数而变化的变化。
找出最小误差和用于达到最小误差的预测树的数目。
[m,i] = min(l_nointactions)
m = 0.0655.
我= 23
GAM在包含22树上的最小错误时达到最小错误。
使用线性术语和交互术语计算累积分类错误。
L = kfoldLoss (CVMdl,“模式”,'累积')
l =2×10.0712 - 0.0712
第一个元素l为使用截距(常数)项和所有预测树每个线性项获得的所有折叠的平均误差。第二要素l是使用截距项获得的平均误差,每个线性术语的所有预测树,以及每个交互项的一个交互树。添加交互术语时,错误不会减少。
如果在预测器树的数量为22时对错误感到满意,则可以通过再次培训单变量游戏并指定来创建预测模型“NumTreesPerPredictor”,22岁没有交叉验证。
输入参数
输出参数
更多关于
分类损失
分类损失功能测量分类模型的预测不准确性。当您在许多模型之间比较相同类型的损耗时,较低的损耗表示更好的预测模型。
考虑以下情景。
l为加权平均分类损失。
n为样本量。
对于二进制分类:
yj是观察到的类标签。软件将其代码为-1或1,表示负类或正类(或第一个或第二类
一会分别属性)。f(Xj)为观察(行)的阳性分类评分j预测数据X.
米j=yjf(Xj)为分类观察的分类评分j对应的类yj.积极的价值观米j表明正确的分类,并没有为平均损失贡献。负值米j表示不正确的分类,并对平均损失显着贡献。
对于支持多类分类的算法(即,金宝appK≥3):
yj*是一个矢量K- 1个零,1在对应于真实的,观察类的位置yj.例如,如果第二个观察的真正类是第三个阶级和K= 4,然后y2*= [0 0 1 0] '.类的顺序对应于订单
一会输入模型的属性。f(Xj)是长度K课程的传染媒介观察的j预测数据X.分数的顺序与表中班级的顺序相对应
一会输入模型的属性。米j=yj*”f(Xj).因此,米j标量分类得分是模型预测真实的观察类。
观测权重j是wj.该软件将观测权值归一化,使其和为相应的先验类别概率。软件还将先验概率归一化,使其和为1。因此,
给定此场景,下表描述了支持的损失函数,可以使用金宝app'lockfun'名称-值对的论点。
| 损失函数 | 的价值LossFun |
方程 |
|---|---|---|
| 二项式偏差 | “binodeviance” |
|
| 小数点被错误分类 | “classiferror” |
为得分最大的类对应的类标签。我{·}是指示函数。 |
| 交叉熵损失 | 'forrorentropy' |
加权交叉熵损失是
哪里重量 都归一化为n而不是1。 |
| 指数损失 | '指数' |
|
| 铰链的损失 | '合页' |
|
| 分对数损失 | 分对数的 |
|
| 最小预期错误分类费用 | 'Mincost' |
该软件计算加权最小期望分类成本使用这一程序的观察j= 1,......,n.
最小预期错误分类成本损失的加权平均值是
如果使用默认代价矩阵(其元素值为0表示正确分类,1表示不正确分类),则 |
| 二次损失 | “二次” |
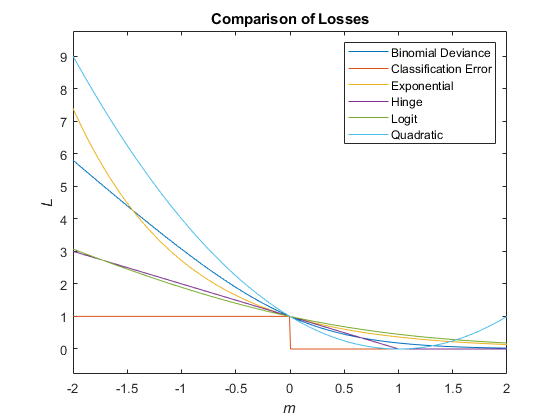
该图比较了损耗功能(除了'forrorentropy'和'Mincost'超过分数米一个观察。某些功能被归一化以通过点(0,1)。
算法
Kfoldloss.计算相应的分类损失损失对象功能。对于特定于模型的描述,请参阅相应的损失函数参考页面在下表中。
扩展能力
您还可以从以下列表中选择一个网站:
