fitcknn
适合k-最近邻分类器
语法
描述
Mdl= fitcknn (资源描述,ResponseVarName)资源描述输出(响应)资源描述。ResponseVarName.
例子
火车k-最近邻分类器
训练k- Fisher虹膜数据的最近邻分类器,其中k,预测器中最近邻居的数量为5。
加载费雪的虹膜数据。
负载fisheririsX = meas;Y =物种;
X是一个数字矩阵,包含150个鸢尾花的四个花瓣测量值。Y是包含相应虹膜种类的特征向量的单元格数组。
训练一个5-近邻分类器。标准化非分类预测数据。
Mdl = fitcknn(X,Y,“NumNeighbors”5,“标准化”, 1)
Mdl = ClassificationKNN ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'setosa' 'versicolor' 'virginica'} ScoreTransform: 'none' NumObservations: 150 Distance: 'euclidean' NumNeighbors: 5 Properties, Methods
Mdl是受过训练的ClassificationKNN分类器,它的一些属性显示在命令窗口中。
访问的属性Mdl,使用点表示法。
Mdl。ClassNames
ans =3 x1细胞{'setosa'} {'versicolor'} {'virginica'}
Mdl。之前
ans =1×30.3333 0.3333 0.3333
Mdl。之前包含类先验概率,您可以使用“之前”中的名称-值对参数fitcknn.类先验概率的顺序对应于中类的顺序Mdl。ClassNames.默认情况下,先验概率是数据中类别各自的相对频率。
你也可以在训练后重置先验概率。例如,将先验概率分别设置为0.5、0.2和0.3。
Mdl。先验= [0.5 0.2 0.3];
训练k使用闵可夫斯基度量的最近邻分类器
加载费雪的虹膜数据集。
负载fisheririsX = meas;Y =物种;
X是一个数字矩阵,包含150个鸢尾花的四个花瓣测量值。Y是包含相应虹膜种类的特征向量的单元格数组。
使用闵可夫斯基度量训练一个3近邻分类器。要使用闵可夫斯基度量,必须使用穷尽式搜索器。标准化非分类预测器数据是一个很好的实践。
Mdl = fitcknn(X,Y,“NumNeighbors”3,...“NSMethod”,“详尽”,“距离”,闵可夫斯基的,...“标准化”1);
Mdl是一个ClassificationKNN分类器。
你可以检查的性质Mdl通过双击Mdl在工作区窗口中。这将打开变量编辑器。


训练k-使用自定义距离度量的最近邻分类器
训练k-使用卡方距离的最近邻分类器。
加载费雪的虹膜数据集。
负载fisheririsX = meas;%预测Y =物种;%响应
之间的卡方距离j维点x而且z是
在哪里 重量与尺寸有关吗j.
指定卡方距离函数。距离函数必须:
取一排
X,例如,x,和矩阵Z.比较
x每一行Z.返回一个向量
D的长度 ,在那里 的行数是多少Z.的每个元素D观测值之间的距离是否对应x和每一行对应的观察值Z.
chiSqrDist = @ x, Z, wt)√((bsxfun (@minus, x, Z)。^ 2)* wt);
本例使用任意权重进行说明。
训练一个3-最近邻分类器。标准化非分类预测器数据是一个很好的实践。
K = 3;W = [0.3;0.3;0.2;0.2);KNNMdl = fitcknn(X,Y,“距离”@ (x, Z) chiSqrDist (x, Z, w),...“NumNeighbors”、钾、“标准化”1);
KNNMdl是一个ClassificationKNN分类器。
使用默认的10倍交叉验证交叉验证KNN分类器。检查分类错误。
rng (1);%用于再现性CVKNNMdl = crossval(KNNMdl);classError = kfoldLoss(CVKNNMdl)
classError = 0.0600
CVKNNMdl是一个ClassificationPartitionedModel分类器。10倍的分类误差为4%。
将该分类器与使用不同加权方案的分类器进行比较。
W2 = [0.2;0.2;0.3;0.3);CVKNNMdl2 = fitcknn(X,Y,“距离”@ (x, Z) chiSqrDist (x, Z, w2),...“NumNeighbors”、钾、“KFold”10“标准化”1);classError2 = kfoldLoss(CVKNNMdl2)
classError2 = 0.0400
第二种加权方案产生的分类器具有更好的样本外性能。
优化拟合KNN分类器
这个例子展示了如何使用自动优化超参数fitcknn.本例使用Fisher虹膜数据。
加载数据。
负载fisheririsX = meas;Y =物种;
通过使用自动超参数优化,找到最小化5倍交叉验证损失的超参数。
为了重现性,设置随机种子并使用“expected-improvement-plus”采集功能。
rng(1) Mdl = fitcknn(X,Y,“OptimizeHyperparameters”,“汽车”,...“HyperparameterOptimizationOptions”,...结构(“AcquisitionFunctionName”,“expected-improvement-plus”))
|=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar | NumNeighbors距离| | | | |结果运行时| | | (estim(观察) .) | | | |=====================================================================================================| | 最好1 | | 0.026667 | 0.54254 | 0.026667 | 0.026667 | 30 |余弦| | 2 |接受| 0.04 | 0.26232 | 0.026667 | 0.027197 | 2 | chebychev | | 3 |接受| 0.19333 | 0.15759 | 0.026667 | 0.030324 | 1 |汉明| | 4 |接受| 0.33333 | 0.13789 | 0.026667 | 0.033313 | | 31日斯皮尔曼| | 5 |的| 0.02 | 0.12 | 0.02 | 0.020648 | 6 |余弦| | 6 |接受| 0.073333 | 0.090568 | 0.02 | 0.023082 | 1 |相关| | | 7日接受| 0.06 | 0.1765 | 0.02 | 0.020875 | 2 | cityblock | | |接受8 | 0.04 | 0.09667 | 0.02 | 0.020622 | 1 |欧几里得| | | 9日接受| 0.24 | 0.18413 | 0.02 | 0.020562 | 74 | mahalanobis | | 10 | | 0.04 | 0.12729| 0.02 | 0.020649 | 1 |闵可夫斯基| | | 11日接受| 0.053333 | 0.14621 | 0.02 | 0.020722 | 1 | seuclidean | | | 12日接受| 0.19333 | 0.089278 | 0.02 | 0.020701 | 1 | jaccard | | | 13日接受| 0.04 | 0.097394 | 0.02 | 0.029203 | 1 | cos | | | 14日接受| 0.04 | 0.090084 | 0.02 | 0.031888 | 75 |余弦| | 15 |接受| 0.04 | 0.092301 | 0.02 | 0.020076 | 1 | cos | | | 16日接受| 0.093333 | 0.18574 | 0.02 | 0.020073 | 75 |欧几里得| | | 17日接受| 0.093333 | 0.098888 | 0.02 | 0.02007 |18 75 |闵可夫斯基| | |接受| 0.1 | 0.10177 | 0.02 | 0.020061 | 75 | chebychev | | | 19日接受| 0.15333 | 0.091498 | 0.02 | 0.020044 | 75 | seuclidean | | |接受20 | 0.1 | 0.12453 | 0.02 | 0.020044 | 75 | cityblock | |=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar | NumNeighbors距离| | | | |结果运行时| |(观察)| (estim) | | ||=====================================================================================================| | 21日|接受| 0.033333 | 0.12905 | 0.02 | 0.020046 | 75 |相关| | | 22日接受| 0.033333 | 0.17091 | 0.02 | 0.02656 | 9 |余弦| | | 23日接受| 0.033333 | 0.28665 | 0.02 | 0.02854 | 9 |余弦| | | 24日接受| 0.02 | 0.12217 | 0.02 | 0.028607 | 1 | chebychev | | | 25日接受| 0.02 | 0.11392 | 0.02 | 0.022264 | 1 | chebychev | | | 26日接受| 0.02 | 0.092565 | 0.02 | 0.021439 | 1| chebychev | | 27 | Accept | 0.02 | 0.098058 | 0.02 | 0.020999 | 1 | chebychev | | 28 | Accept | 0.66667 | 0.21811 | 0.02 | 0.020008 | 75 | hamming | | 29 | Accept | 0.04 | 0.17081 | 0.02 | 0.020008 | 12 | correlation | | 30 | Best | 0.013333 | 0.14369 | 0.013333 | 0.013351 |欧几里得|
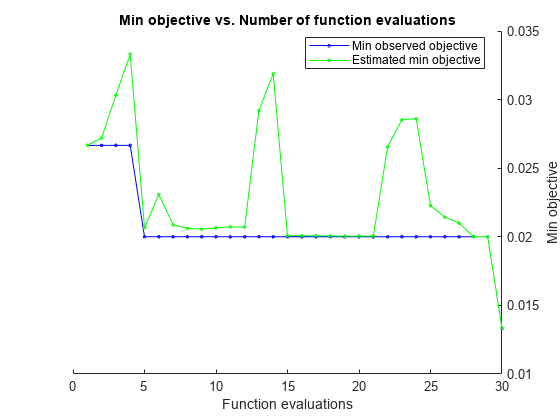
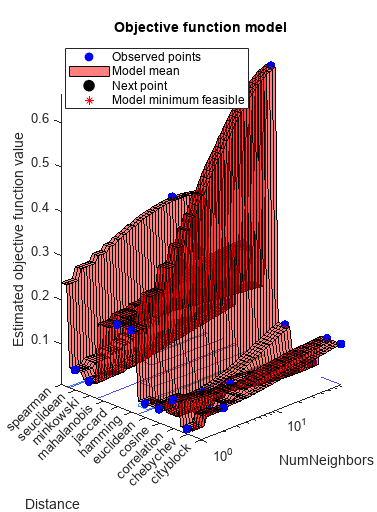
__________________________________________________________ 优化完成。最大目标达到30个。总函数评估:30总运行时间:61.4049秒总目标函数评估时间:4.5591最佳观测可行点:NumNeighbors Distance ____________ _________ 6 euclidean观测目标函数值= 0.013333估计目标函数值= 0.013351函数评估时间= 0.14369最佳估计可行点(根据模型):NumNeighbors Distance ____________ _________ 6欧几里得估计目标函数值= 0.013351估计函数评估时间= 0.14301
Mdl = ClassificationKNN ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'setosa' 'versicolor' 'virginica'} ScoreTransform: 'none' NumObservations: 150 HyperparameterOptimizationResults: [1x1 BayesianOptimization] Distance: 'euclidean' NumNeighbors: 6 Properties, Methods
输入参数
输出参数
更多关于
提示
在训练模型之后,您可以生成C/ c++代码来预测新数据的标签。生成C/ c++代码需要MATLAB编码器™.详细信息请参见代码生成简介.
算法
nan或<定义>S表示缺失的观测值。下面描述的行为fitcknn当数据集或权重包含缺失观测值时。假设你设
“标准化”,1.如果你指定
规模任意一个之前或权重,然后软件用加权标准差对观测距离进行缩放。如果你指定
浸任意一个之前或权重,然后软件将加权协方差矩阵应用于距离。换句话说,在哪里B是指数的集合吗j因为观察到xj没有任何缺失的值和wj不是失踪。
选择
虽然fitcknn可以训练一个多类KNN分类器,你可以将一个多类学习问题简化为一系列KNN二元学习器使用fitcecoc.
扩展功能
您也可以从以下列表中选择一个网站:
