使用最近邻居分类
成对距离度量标准
根据其训练数据集中点的距离对查询点进行分类,可以是对新点进行分类的简单而有效的方式。您可以使用各种指标来确定下一个描述的距离。用PDIST2.找到一组数据和查询点之间的距离。
距离指标
给予A.MX.-经过-N数据矩阵X,被视为MX.(1-by-N)行向量X1那X2,......,XMX., 和我的-经过-N数据矩阵y,被视为我的(1-by-N)行向量y1那y2,......,y我的,矢量之间的各种距离XS.和yT.定义如下:
欧几里德距离
欧几里德距离是Minkowski距离的特殊情况,在哪里P.= 2。
标准化的欧几里德距离
在哪里V.是个N-经过-N对角线矩阵谁jth对角形元素是(S.(j)))2, 在哪里S.是每个维度的缩放因子的矢量。
Mahalanobis距离
在哪里C是协方差矩阵。
城市街区距离
城市街区距离是Minkowski距离的特殊情况,在哪里P.= 1。
Minkowski距离
对于特例P.= 1,Minkowski距离给出了城市街区距离。对于特例P.= 2,Minkowski距离给出了欧几里德距离。对于特例P.=∞,Minkowski距离给出了Chebychev距离。
Chebychev距离
Chebychev距离是Minkowski距离的特殊情况,在哪里P.=∞。
余弦距离
相关距离
在哪里
和
汉明距离
jaccard距离
斯普曼距离
在哪里
K.- 最终邻居搜索和RADIUS搜索
给了一套X的N点和距离功能,K.-最近的邻居 (K.nn)搜索让您找到K.最近的点X到查询点或一组点y。这K.nn搜索技术和K.基于NN的算法被广泛用作基准学习规则。相对简单的简单性K.NN搜索技术使其容易将其他分类技术与其他分类技术进行比较K.结果。该技术已在各种区域中使用,例如:
生物信息学
图像处理和数据压缩
文件检索
计算机视觉
多媒体数据库
营销数据分析
您可以使用K.nn搜索其他机器学习算法,例如:
K.NN分类
局部加权回归
缺少数据归档和插值
密度估计
你也可以使用K.NN搜索许多基于距离的学习功能,例如K-means群集。
相比之下,对于积极的实际价值R.那rangesearch.找到所有要点X这在远处R.每个点y。此固定半径搜索与其密切相关K.NN搜索,因为它支持相同的距离指标金宝app和搜索类,并使用相同的搜索算法。
K.- 使用详尽搜索最终邻居搜索
当输入数据符合以下任何条件时,knnsearch.默认使用详尽的搜索方法来查找K.- 最邻居:
列的列数
X超过10。X稀疏。距离度量是:
'seuclidean''mahalanobis''余弦''相关性'“矛曼”'汉明''jaccard'自定义距离功能
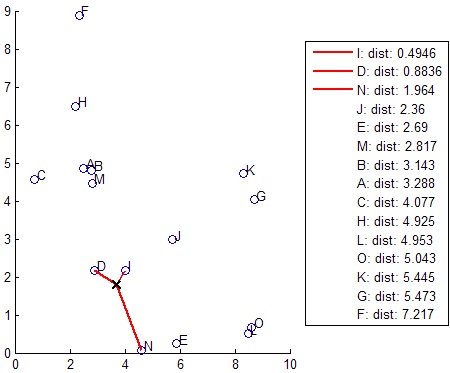
knnsearch.如果您的搜索对象是一个,还使用详尽的搜索方法令人疲惫的模型对象。详尽的搜索方法找到了每个查询点到每一点的距离X,按升序排列,并返回K.距离最小的点。例如,该图显示了K.= 3最近的邻居。
K.- 最终邻居搜索使用K.D树
当输入数据符合以下所有标准时,knnsearch.创造一个K.d-tree默认找到K.- 最邻居:
列的列数
X小于10。X不是稀疏。距离度量是:
'euclidean'(默认)'城市街区''minkowski''chebbychev'
knnsearch.也使用A.K.如果您的搜索对象是一个kdtreesearcher.模型对象。
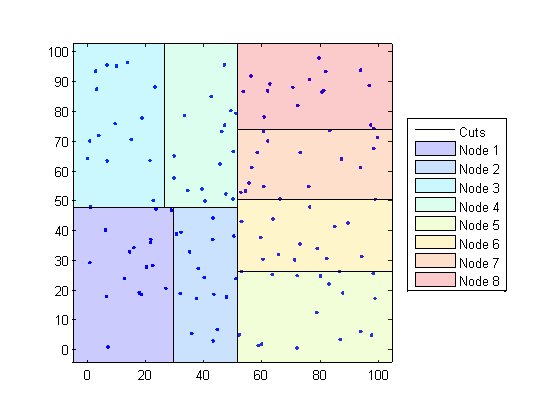
K.D-Trount最多将数据划分为节点桶装(默认为50)每个节点的点,基于坐标(与类别相反)。下图说明了使用的概念修补对象颜色代码不同的“桶”。
当你想找到的时候K.- 给定查询点的最佳邻居,knnsearch.是否有以下操作:
确定查询点所属的节点。在以下示例中,查询点(32,90)属于节点4。
找到最接近的K.该节点内的点及其与查询点的距离。在以下示例中,红色圆圈中的点与查询点等距,并且是节点4内的查询点的最接近点。
选择具有在任何方向的任何区域,在任何方向上的任何区域,从查询点到K.最接近的点。在该示例中,只有节点3与以附近的查询点为中心的固体黑圆重叠,半径等于到节点4内最近点的距离。
在该范围内搜索较近查询点的任何要点的范围内的节点。在以下示例中,红正方形中的点略近于查询点而不是节点4内的点。

用一个K.对于大于10维度(列)少于10个尺寸(列)的大数据集的D树比使用详尽的搜索方法更有效,如knnsearch.需要仅计算距离的子集。最大限度地提高效率K.D树,使用akdtreesearcher.模型。
什么是搜索模型对象?
基本上,模型对象是存储信息的便捷方式。相关模型具有与与指定的搜索方法相关的值和类型相同的属性。除了在模型中存储信息外,您还可以对模型执行某些操作。
你可以有效地执行一个K.- 最终邻居使用搜索模型搜索knnsearch.。或者,您可以使用搜索模型搜索指定的半径内的所有邻居rangesearch.。此外,还有一个通用的knnsearch.和rangesearch.在不创建或使用模型的情况下搜索的功能。
要确定哪种类型的模型和搜索方法最适合您的数据,请考虑以下内容:
您的数据是否有许多列,比如10到10个?这
令人疲惫的模型可能表现更好。你的数据稀疏了吗?使用
令人疲惫的模型。你想使用这些距离指标中的一个来找到最近的邻居吗?使用
令人疲惫的模型。'seuclidean''mahalanobis''余弦''相关性'“矛曼”'汉明''jaccard'自定义距离功能
您的数据集是否庞大(但少于10列)?使用
kdtreesearcher.模型。您是否在寻找最近的邻居进行大量查询点?使用
kdtreesearcher.模型。
分类查询数据
此示例显示如何通过以下方式对查询数据进行分类:
生长A.K.D树
进行A.K.最近的邻居搜索使用生长的树。
分配每个查询指向其各自的最近邻居之间具有最高表示的类。
根据Fisher Iris数据的最后两列对新点进行分类。仅使用最后两列使得更容易绘制。
加载渔民X = MEAS(:,3:4);G箭头(x(:,1),x(:,2),物种)传奇('地点'那'最好的')

绘制新点。
newpoint = [5 1.45];行(NewPoint(1),Newpoint(2),'标记'那'X'那'颜色'那'K'那......'Markersize'10,'行宽'2)

准备A.K.D-Tree邻居搜索器模型。
mdl = kdtreesearcher(x)
MDL =具有属性的KDTreeSearcher:Bucketsize:50距离:'euclidean'textParameter:[] X:[150x2双]
MDL.是A.kdtreesearcher.模型。默认情况下,它用于搜索邻居的距离度量是欧几里德距离。
找到最接近新点的10个样本点。
[n,d] = knnsearch(mdl,newpoint,'K',10);线(x(n,1),x(n,2),'颜色',[。5.5 .5],'标记'那'o'那......'linestyle'那'没有任何'那'Markersize',10)
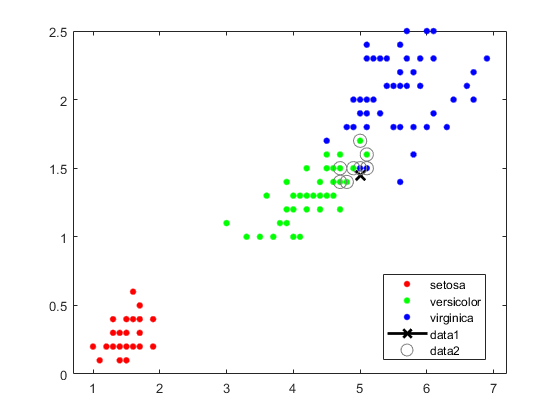
看起来knnsearch.只发现了最近的八个邻居。实际上,这个特定的数据集包含重复值。
x(n,:)
ans =.10×25.0000 1.5000 4.9000 1.5000 4.9000 1.5000 1.5000 1.1000 1.6000 1.6000 1.4000 5.0000 1.7000 4.7000 1.4000 4.7000 1.4000 4.7000 1.5000
使轴等于,所以计算的距离对应于绘图轴上的表观距离等于和放大以更好地看到邻居。
XLIM([4.45 5.5]);ylim([1 2]);轴正方形
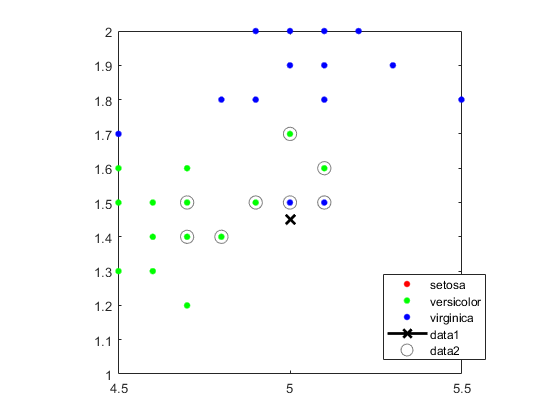
找到10个邻居的物种。
Tabulate(物种(n))
价值计数百分比Virginica 2 20.00%Versicolor 8 80.00%
使用基于10个最近邻居的大多数投票的规则,您可以将此新点分类为versicolor。
通过围绕它们的组绘制圆圈来直观地识别邻居。根据新点的位置定义圆的中心和直径。
ctr = newpoint - d(结束);直径= 2 * D(结束);%绘制了10个最近邻居周围的圆圈。h =矩形('位置',[CTR,直径,直径],......'曲率',[1 1]);H.LINESTYLE =':';

使用相同的数据集,找到10个最近的邻居到三个新点。
图nempoint2 = [5 1.45; 6 2; 2.75 .75];G箭头(x(:,1),x(:,2),物种)传奇('地点'那'最好的')[n2,d2] = knnsearch(mdl,newpoint2,'K',10);线(x(n2,1),x(n2,2),'颜色',[。5.5 .5],'标记'那'o'那......'linestyle'那'没有任何'那'Markersize',10)行(newpoint2(:,1),newpoint2(:,2),'标记'那'X'那'颜色'那'K'那......'Markersize'10,'行宽'2,'linestyle'那'没有任何')

找到每个新点的10个最近邻居的物种。
Tabulate(物种(n2(1,:))))
价值计数百分比Virginica 2 20.00%Versicolor 8 80.00%
Tabulate(物种(n2(2,:))))
价值计数Virginica 10 100.00%
Tabulate(物种(n2(3,:)))
价值计数百分比Versicolor 7 70.00%setosa 3 30.00%
有关更多示例,使用knnsearch.方法和功能,请参阅单个参考页面。
使用自定义距离度量查找最近的邻居
此示例显示了如何查找三个最近观察的指标X每次观察y关于Chi-Square距离。该距离度量用于对应分析,特别是在生态应用中。
随机生成正常分布的数据分为两个矩阵。行数可以变化,但列数必须是相等的。此示例使用2-D数据进行绘图。
RNG(1)重复性的%x = randn(50,2);y = randn(4,2);h =零(3,1);图H(1)= plot(x(:,1),x(:,2),'bx');抓住上h(2)= plot(y(:,1),y(:,2),'rs'那'Markersize',10);标题('异构数据')
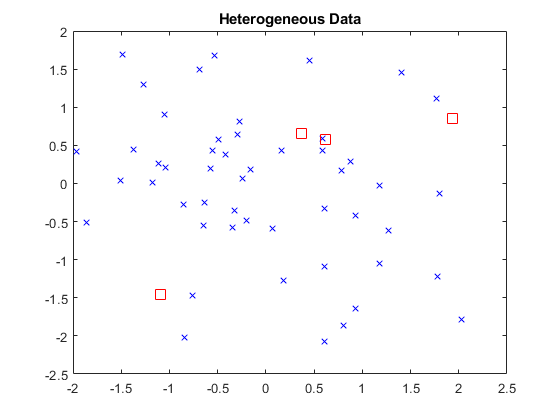
行的行X和y对应于观察,一般来说,列是尺寸(例如,预测器)。
之间的奇方距离j- 一致的积分X和Z.是
在哪里 是与维度相关的重量j。
为每个维度选择重量,并指定Chi-Square距离功能。距离功能必须:
作为输入参数一行
X,例如,X和矩阵Z.。比较
X每行Z.。返回矢量
D.长度 , 在哪里 是行的行数Z.。每个元素D.是观察之间的距离对应于X和对应于每行的观察Z.。
w = [0.4;0.6];Chisqrdist = @(x,z)sqrt((bsxfun(@ minus,x,z)。^ 2)* w);
此示例使用任意权重用于说明。
找到三个最近观察的指数X每次观察y。
k = 3;[idx,d] = knnsearch(x,y,'距离',Chisqrdist,'K',k);
idx.和D.是4×3矩阵。
IDX(J,1)是最近观察的行指数X观察j的y, 和D(j,1)是他们的距离。IDX(J,2)是下一个最近观察的行指数X观察j的y, 和D(J,2)是他们的距离。等等。
确定情节中最近的观察结果。
为了j = 1:k h(3)= plot(x(idx(:,j),1),x(idx(:,j),2),'ko'那'Markersize',10);结尾传奇(H,{'\ texttt {x}'那'\ texttt {y}'那'最近的邻居'},'口译员'那'乳胶') 标题('异构数据和最近的邻居') 抓住离开

几个观察y分享最近的邻居。
验证Chi-Square距离度量等同于欧几里德距离度量,而是具有可选的缩放参数。
[idxe,de] = knnsearch(x,y,'距离'那'seuclidean'那'K',k,......'规模',1 ./(SQRT(W))));arediffidx = sum(sum(idx〜= idxe))
arediffidx = 0.
arediffdist = sum(sum(abs(d - de)> eps))
arediffdist = 0.
三个最近邻居的两种实现之间的指标和距离实际上是等效的。
K.用于监督学习的最终邻居分类
这ClassificationKnn.分类模型可让您:
构建KNN分类器
此示例显示了如何构建一个K.用于Fisher IRIS数据的邻居分类器。
加载Fisher IRIS数据。
加载渔民x = meas;%使用所有数据进行配件y =物种;%响应数据
构建分类器使用Fitcknn.。
mdl = fitcknn(x,y)
mdl = classificationknn racatectename:'y'pationoricalpricictors:[] classnames:{'setosa''versicolor''virginica'} scoreTransform:'none'numobservations:150距离:'euclidean'numneighbors:1属性,方法
默认值K.- 最终邻居分类器仅使用单个最接近的邻居。通常,分类器更强大,与邻居更具邻居。
改变邻里大小MDL.至4., 意思是MDL.使用四个最近邻居进行分类。
mdl.numneighbors = 4;
检查KNN分类器的质量
此示例显示如何检查a的质量K.- 使用ResubStitution和交叉验证的最佳邻居分类器。
为Fisher Iris数据构建一个Knn分类器构建KNN分类器。
加载渔民x = meas;y =物种;RNG(10);重复性的%mdl = fitcknn(x,y,'numneighbors'4);
审查备份损失,缺省情况是从预测中的错误分类分数MDL.。(对于非默认成本,重量或前瞻,见失利。)。
rloss = resubloss(mdl)
rloss = 0.0400.
分类器预测4%的训练数据的错误。
从模型构造交叉验证的分类器。
cvmdl = crossval(mdl);
检查交叉验证丢失,这是在预测未用于培训的数据上时每个交叉验证模型的平均丢失。
kloss = kfoldloss(cvmdl)
kloss = 0.0333
交叉验证的分类准确性类似于重新提交的准确性。因此,你可以期待MDL.假设新数据与培训数据具有大致相同的分发,以错误分类约4%的新数据。
使用KNN分类器预测分类
此示例显示了如何预测A分类K.- 最终邻居分类器。
为Fisher Iris数据构建一个Knn分类器构建KNN分类器。
加载渔民x = meas;y =物种;mdl = fitcknn(x,y,'numneighbors'4);
预测平均花的分类。
flwr =平均(x);%平均花Flwrclass =预测(MDL,FLWR)
flwrclass =1x1细胞阵列{'versicolor'}
修改KNN分类器
此示例显示如何修改aK.- 最终邻居分类器。
为Fisher Iris数据构建一个Knn分类器构建KNN分类器。
加载渔民x = meas;y =物种;mdl = fitcknn(x,y,'numneighbors'4);
修改模型以使用三个最近的邻居,而不是默认的一个最近的邻居。
mdl.numneighbors = 3;
比较新数量邻居的重新提交预测和交叉验证损失。
损失= RERUBLOS(MDL)
损失= 0.0400.
RNG(10);重复性的%cvmdl = crossval(mdl,'kfold'5);kloss = kfoldloss(cvmdl)
kloss = 0.0333
在这种情况下,具有三个邻居的模型具有与具有四个邻居的模型相同的交叉验证损耗(参见检查KNN分类器的质量)。
修改模型以使用余弦距离而不是默认值,并检查丢失。要使用余弦距离,必须使用详尽的搜索方法来重新创建模型。
cmdl = fitcknn(x,y,'nsmethod'那'彻底的'那'距离'那'余弦');cmdl.numneighbors = 3;closs = Resubloss(cmdl)
Closs = 0.0200.
分类器现在具有比以前更低的重新提交错误。
检查新模型的交叉验证版本的质量。
cvcmdl = crossval(cmdl);kcloss = kfoldloss(cvcmdl)
kcloss = 0.0200.
cvcmdl.有一个比较更好的交叉验证损失cvmdl.。然而,一般而言,改善重新提交误差不一定产生具有更好测试样本预测的模型。
也可以看看
您还可以从以下列表中选择一个网站:
