主要内容
knnsearch.
找到K.- 使用输入数据的最佳邻居
描述
例子
找到最近的邻居
找到病人在医院与病人最相似的数据集y,根据年龄和体重。
加载医院数据集。
加载医院;X =[医院。年龄hospital.Weight);Y = [20 162;30 169;40 168;50 170;60 171];%新患者
执行一个knnsearch.之间的X和y查找最近邻的索引。
Idx = knnsearch (X, Y);
找到病人X最近的年龄和体重y.
x(idx,:)
ans =.5×225 171 25 171 39 164 49 170 50 172
找到K.使用不同距离指标的最佳邻居
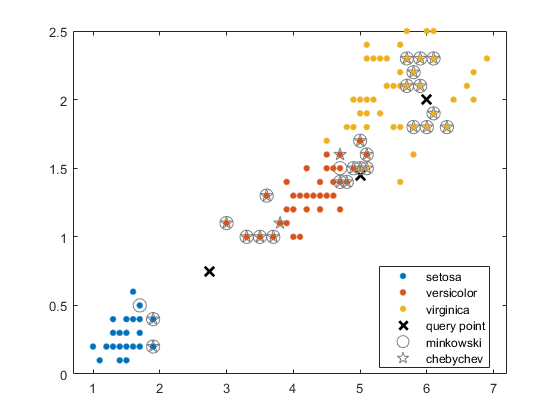
找到10个最近的邻居X每个点y,首先使用闵可夫斯基距离度量,然后使用切比切夫距离度量。
装载Fisher的Iris数据集。
加载fisheririsX =量(:,3:4);原始花的测量值Y = [5 1.45;6 2;2.75 .75];%新花卉数据
执行一个knnsearch.之间的X以及查询点y使用Minkowski和Chebychev距离度量。
(马里兰州mIdx) = knnsearch (X, Y,'K'10“距离”那闵可夫斯基的那'P'5);[CIDX,CD] = knnsearch(x,y,'K'10“距离”那'chebbychev');
可视化两个最近邻的搜索结果。绘制训练数据。用标记x绘制查询点。用圆圈表示Minkowski最近的邻居。用五角形来表示切比切夫最近的邻居。
Gsfatter(x(:,1),x(:,2),物种)线(y(:,1),y(:,2),“标记”那'X'那'颜色'那“k”那...'Markersize'10'行宽'2,'linestyle'那'没有任何')线(X (mIdx, 1), X (mIdx, 2),'颜色',(。5。5。5),“标记”那'o'那...'linestyle'那'没有任何'那'Markersize'10)线(X (cIdx, 1), X (cIdx, 2),'颜色',(。5。5。5),“标记”那'P'那...'linestyle'那'没有任何'那'Markersize'10)传说('setosa'那“多色的”那'virginica'那“查询点”那...闵可夫斯基的那'chebbychev'那“位置”那“最佳”)
输入参数
输出参数
提示
一个固定的正整数K.那
knnsearch.找到K.要点X这是每个点最近的y.找到所有要点X在每个点的固定距离内y,使用rangesearch.knnsearch.不保存搜索对象。要创建搜索对象,请使用createns.
算法
有关特定搜索算法的信息,请参见k近邻搜索和半径搜索.
选择功能
如果你设置knnsearch.函数的'nsmethod'名称值对参数适当的值(“详尽”用于详尽的搜索算法或'kdtree'对于一个K.d-树算法),然后将搜索结果等价于使用knnsearch.对象的功能。不像knnsearch.函数,knnsearch.对象功能需要一个令人疲惫的或者一个KDTreeSearcher模型对象。
参考
[1]弗里德曼,J.H.,J. Bentely和R. A. Finkel。“一种在对数预期时间中找到最佳匹配的算法。”数学软件上的ACM交易3,没有。3(1977): 209 - 226。
扩展功能
介绍了R2010a
你也可以从以下列表中选择一个网站:
