fitcecocGyD.F4y2Ba
适合多类机型支持向量机或其他分类金宝appGyD.F4y2Ba
语法GyD.F4y2Ba
描述GyD.F4y2Ba
MdlGyD.F4y2Ba= fitcecoc (GyD.F4y2BaTBL.GyD.F4y2Ba那GyD.F4y2BaResponseVarNameGyD.F4y2Ba)GyD.F4y2BaTBL.GyD.F4y2Ba和类标签GyD.F4y2Batbl.responsevarname.GyD.F4y2Ba.GyD.F4y2BafitcecocGyD.F4y2Ba使用GyD.F4y2BaK.GyD.F4y2Ba(GyD.F4y2BaK.GyD.F4y2Ba- 1)/2二进制支持向量机金宝app(SVM)模型,使用1对1GyD.F4y2Ba编码设计GyD.F4y2Ba, 在哪里GyD.F4y2BaK.GyD.F4y2Ba是唯一的类标签(水平)的数量。GyD.F4y2BaMdlGyD.F4y2Ba是一个GyD.F4y2BaClassificationECOCGyD.F4y2Ba模型。GyD.F4y2Ba
MdlGyD.F4y2Ba= fitcecoc (GyD.F4y2BaTBL.GyD.F4y2Ba那GyD.F4y2Ba公式GyD.F4y2Ba)GyD.F4y2BaTBL.GyD.F4y2Ba以及类标签。GyD.F4y2Ba公式GyD.F4y2Ba是响应的解释模型和预测变量的子集GyD.F4y2BaTBL.GyD.F4y2Ba用于培训。GyD.F4y2Ba
MdlGyD.F4y2Ba= fitcecoc (GyD.F4y2BaTBL.GyD.F4y2Ba那GyD.F4y2BayGyD.F4y2Ba)GyD.F4y2BaTBL.GyD.F4y2Ba以及vector中的类标签GyD.F4y2BayGyD.F4y2Ba.GyD.F4y2Ba
MdlGyD.F4y2Ba= fitcecoc (GyD.F4y2BaXGyD.F4y2Ba那GyD.F4y2BayGyD.F4y2Ba)GyD.F4y2BaXGyD.F4y2Ba以及类标签GyD.F4y2BayGyD.F4y2Ba.GyD.F4y2Ba
MdlGyD.F4y2Ba= fitcecoc (GyD.F4y2Ba___GyD.F4y2Ba那GyD.F4y2Ba名称,值GyD.F4y2Ba)GyD.F4y2Ba名称,值GyD.F4y2BaPair参数,使用前面的任何语法。GyD.F4y2Ba
例如,指定不同的二进制学习器、不同的编码设计或交叉验证。的交叉验证是一个很好的实践GyD.F4y2BaKfoldGyD.F4y2Ba名称,值GyD.F4y2Ba对参数。交叉验证的结果决定了模型的泛化程度。GyD.F4y2Ba
[GyD.F4y2Ba当您指定也返回超参数优化细节GyD.F4y2BaMdlGyD.F4y2Ba那GyD.F4y2BaHyperParameterOptimationResults.GyD.F4y2Ba) = fitcecoc (GyD.F4y2Ba___GyD.F4y2Ba那GyD.F4y2Ba名称,值GyD.F4y2Ba)GyD.F4y2BaOptimizeHyperparametersGyD.F4y2Ba名称-值对参数并使用线性或内核二进制学习器。为其他GyD.F4y2Ba学习者GyD.F4y2Ba,GyD.F4y2BaHyperParameterOptimationResults.GyD.F4y2Ba的属性GyD.F4y2BaMdlGyD.F4y2Ba包含结果。GyD.F4y2Ba
例子GyD.F4y2Ba
使用支持向量机学习器训练多类模型GyD.F4y2Ba
使用支持向量机(SVM)二进制学习者培训多种误差校正输出代码(ECOC)模型。金宝appGyD.F4y2Ba
装载Fisher的Iris数据集。指定预测器数据GyD.F4y2BaXGyD.F4y2Ba和响应数据GyD.F4y2BayGyD.F4y2Ba.GyD.F4y2Ba
负载GyD.F4y2BafisheririsGyD.F4y2BaX =量;y =物种;GyD.F4y2Ba
使用默认选项训练多类ECOC模型。GyD.F4y2Ba
Mdl = fitcecoc (X, Y)GyD.F4y2Ba
MDL = ClassificationECOC ResponseName: 'Y' CategoricalPredictors:[]类名:{ 'setosa' '云芝' '锦葵'} ScoreTransform: '无' BinaryLearners:{3×1细胞} CodingName: 'onevsone' 属性,方法GyD.F4y2Ba
MdlGyD.F4y2Ba是一个GyD.F4y2BaClassificationECOCGyD.F4y2Ba模型。默认情况下,GyD.F4y2BafitcecocGyD.F4y2Ba使用支持向量机二进制学习器和一对一编码设计。您可以访问GyD.F4y2BaMdlGyD.F4y2Ba使用点符号的属性。GyD.F4y2Ba
显示类名和编码设计矩阵。GyD.F4y2Ba
Mdl。CL.一种S.S.的名字S.GyD.F4y2Ba
ans =GyD.F4y2Ba3x1细胞GyD.F4y2Ba{'setosa'} {'versicolor'} {'virginica'}GyD.F4y2Ba
CodingMat = Mdl。CodingMatrixGyD.F4y2Ba
codingmat =GyD.F4y2Ba3×3GyD.F4y2Ba1 1 0 -1 0 1 0 -1 -1GyD.F4y2Ba
三个类的一个与一个编码设计产生了三个二进制学习者。列的列GyD.F4y2BaCodingMatGyD.F4y2Ba对应学习者,行对应班级。类的顺序与在类中的顺序相同GyD.F4y2BaMdl。CL.一种S.S.的名字S.GyD.F4y2Ba.例如,GyD.F4y2BaCodingMat (: 1)GyD.F4y2Ba是GyD.F4y2Ba[1;-1;0]GyD.F4y2Ba表示该软件使用分类为的所有观测值训练第一个支持向量机二值学习器GyD.F4y2Ba'setosa'GyD.F4y2Ba和GyD.F4y2Ba“多色的”GyD.F4y2Ba.因为GyD.F4y2Ba'setosa'GyD.F4y2Ba对应于GyD.F4y2Ba1GyD.F4y2Ba,这是积极的课程;GyD.F4y2Ba“多色的”GyD.F4y2Ba对应于GyD.F4y2Ba1GyD.F4y2Ba,所以这是负类。GyD.F4y2Ba
您可以使用单元格索引和点表示法访问每个二进制学习器。GyD.F4y2Ba
mdl.binarylearners {1}GyD.F4y2Ba第一个二元学习者GyD.F4y2Ba
ANS = CompactClassificationsVM RecordingAme:'Y'类分类:[] ClassNames:[-1 1] ScorEtransform:'none'Beta:[4x1 Double]偏置:1.4492内核参数:[1x1结构]属性,方法GyD.F4y2Ba
计算重新替换分类错误。GyD.F4y2Ba
错误= resubLoss (Mdl)GyD.F4y2Ba
错误= 0.0067GyD.F4y2Ba
训练数据的分类误差很小,但分类器可能是一个过拟合模型。您可以使用交叉验证分类器GyD.F4y2Ba横梁GyD.F4y2Ba并计算交叉验证分类错误。GyD.F4y2Ba
列车多类线性分类模型GyD.F4y2Ba
培训由多个二进制线性分类模型组成的ecoc模型。GyD.F4y2Ba
加载NLP数据集。GyD.F4y2Ba
负载GyD.F4y2BanlpdataGyD.F4y2Ba
XGyD.F4y2Ba是预测数据的稀疏矩阵,和GyD.F4y2BayGyD.F4y2Ba是类标签的分类矢量。数据中有两个以上的类。GyD.F4y2Ba
创建一个默认的线性分类模型模板。GyD.F4y2Ba
t = templateLinear ();GyD.F4y2Ba
若要调整默认值,请参阅GyD.F4y2Ba名称-值对的观点GyD.F4y2Ba在GyD.F4y2BatemplateLinearGyD.F4y2Ba页面。GyD.F4y2Ba
训练由多个二元线性分类模型组成的ECOC模型,该模型可以根据文档网页上单词的频率分布来识别产品。为了更快的训练时间,将预测器数据转置,并指定观测值对应于列。GyD.F4y2Ba
X = X ';RNG(1);GyD.F4y2Ba%的再现性GyD.F4y2Bamdl = fitcecoc(x,y,GyD.F4y2Ba'学习者'GyD.F4y2Ba,T,GyD.F4y2Ba'观察'GyD.F4y2Ba那GyD.F4y2Ba“列”GyD.F4y2Ba)GyD.F4y2Ba
Mdl = CompactClassificationECOC ResponseName: 'Y' ClassNames: [1x13 categorical] ScoreTransform: 'none' BinaryLearners: {78x1 cell} CodingMatrix: [13x78 double]属性,方法GyD.F4y2Ba
或者,您可以使用以下方法训练由默认线性分类模型组成的ECOC模型GyD.F4y2Ba“学习者”,“线性”GyD.F4y2Ba.GyD.F4y2Ba
为了节省内存,GyD.F4y2BafitcecocGyD.F4y2Ba返回由线性分类学习者组成的训练过的ECOC模型GyD.F4y2BaCompactClassificationECOCGyD.F4y2Ba模型对象。GyD.F4y2Ba
交叉验证ECOC分类器GyD.F4y2Ba
用支持向量机二值学习器交叉验证ECOC分类器,估计广义分类误差。GyD.F4y2Ba
装载Fisher的Iris数据集。指定预测器数据GyD.F4y2BaXGyD.F4y2Ba和响应数据GyD.F4y2BayGyD.F4y2Ba.GyD.F4y2Ba
负载GyD.F4y2BafisheririsGyD.F4y2BaX =量;y =物种;RNG(1);GyD.F4y2Ba%的再现性GyD.F4y2Ba
创建一个支持向量机模板,并标准化预测器。GyD.F4y2Ba
t = templatesvm(GyD.F4y2Ba“标准化”GyD.F4y2Ba,真的)GyD.F4y2Ba
T =用于分类SVM拟合模板。阿尔法:为0x1双] BoxConstraint:[] CacheSize的:[] CachingMethod: '' ClipAlphas:[] DeltaGradientTolerance:[]小量:[] GapTolerance:[] KKTTolerance:[] IterationLimit:[] KernelFunction: '' KernelScale:[]KernelOffset:[] KernelPolynomialOrder:[] NumPrint:[]女:[] OutlierFraction:[] RemoveDuplicates:[] ShrinkagePeriod:[]求解: '' StandardizeData:1个SaveSupportVectors:金宝app[] VerbosityLevel:[]版本:2所述的方法:“SVM'类型:‘分类’GyD.F4y2Ba
T.GyD.F4y2Ba是一个支持向量机模板。大多数模板对象属性都是空的。在训练ECOC分类器时,软件将适用属性设置为默认值。GyD.F4y2Ba
训练ECOC分类器,并指定类的顺序。GyD.F4y2Ba
mdl = fitcecoc(x,y,GyD.F4y2Ba'学习者'GyD.F4y2Ba,T,GyD.F4y2Ba...GyD.F4y2Ba“类名”GyD.F4y2Ba,{GyD.F4y2Ba'setosa'GyD.F4y2Ba那GyD.F4y2Ba“多色的”GyD.F4y2Ba那GyD.F4y2Ba“virginica”GyD.F4y2Ba});GyD.F4y2Ba
MdlGyD.F4y2Ba是一个GyD.F4y2BaClassificationECOCGyD.F4y2Ba分类器。您可以使用点表示法访问其属性。GyD.F4y2Ba
旨在GyD.F4y2BaMdlGyD.F4y2Ba使用10倍交叉验证。GyD.F4y2Ba
CVMdl = crossval (Mdl);GyD.F4y2Ba
CVMdlGyD.F4y2Ba是一个GyD.F4y2BaClassificationPartitionedECOCGyD.F4y2Ba旨在ECOC分类器。GyD.F4y2Ba
估计广义分类错误。GyD.F4y2Ba
genError = kfoldLoss (CVMdl)GyD.F4y2Ba
genError = 0.0400GyD.F4y2Ba
广义分类误差为4%,表明ECOC分类器具有较好的泛化能力。GyD.F4y2Ba
使用Ecoc分类器估计后验概率GyD.F4y2Ba
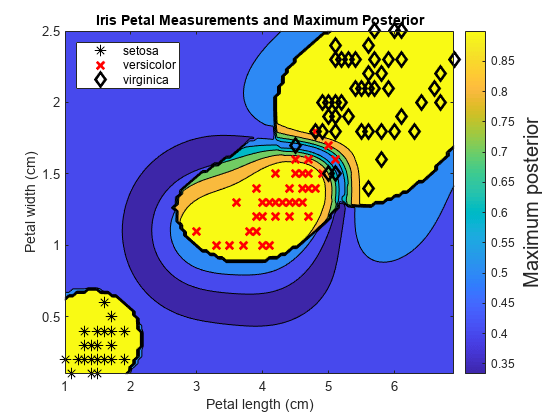
使用支持向量机二进制学习器训练ECOC分类器。首先预测训练样本标签和类的后验概率。然后预测网格中每个点的最大类别后验概率。可视化结果。GyD.F4y2Ba
装载Fisher的Iris数据集。将花瓣尺寸指定为预测器和物种名称作为响应。GyD.F4y2Ba
负载GyD.F4y2BafisheririsGyD.F4y2BaX = MEAS(:,3:4);y =物种;RNG(1);GyD.F4y2Ba%的再现性GyD.F4y2Ba
创建SVM模板。标准化预测器,并指定高斯内核。GyD.F4y2Ba
t = templatesvm(GyD.F4y2Ba“标准化”GyD.F4y2Ba,真的,GyD.F4y2Ba“KernelFunction”GyD.F4y2Ba那GyD.F4y2Ba“高斯”GyD.F4y2Ba);GyD.F4y2Ba
T.GyD.F4y2Ba是一个支持向量机模板。它的大部分属性都是空的。当软件训练ECOC分类器时,它将适用的属性设置为它们的默认值。GyD.F4y2Ba
使用SVM模板列车ecoc分类器。将分类分数转换为课程后概率(由此返回GyD.F4y2Ba预测GyD.F4y2Ba或GyD.F4y2Ba重新预订GyD.F4y2Ba) 使用GyD.F4y2Ba'fitposterior'GyD.F4y2Ba名称-值对的论点。属性指定类的顺序GyD.F4y2Ba“类名”GyD.F4y2Ba名称-值对的论点。方法在训练期间显示诊断消息GyD.F4y2Ba“详细”GyD.F4y2Ba名称-值对的论点。GyD.F4y2Ba
mdl = fitcecoc(x,y,GyD.F4y2Ba'学习者'GyD.F4y2Ba,T,GyD.F4y2Ba'fitposterior'GyD.F4y2Ba,真的,GyD.F4y2Ba...GyD.F4y2Ba“类名”GyD.F4y2Ba,{GyD.F4y2Ba'setosa'GyD.F4y2Ba那GyD.F4y2Ba“多色的”GyD.F4y2Ba那GyD.F4y2Ba“virginica”GyD.F4y2Ba},GyD.F4y2Ba...GyD.F4y2Ba“详细”GyD.F4y2Ba2);GyD.F4y2Ba
培训二进制学习者1(SVM),其中3个,50个负和50个阳性观察。负类指数:2个正类指数:1用于学习者1(SVM)的后验概率。培训二元学习者2(SVM),其中3个,50个负和50个阳性观察。负类指数:3个正类指数:1拟合学习者2(SVM)的后验概率。培训二进制学习者3(SVM),其中50个负和50个阳性观察。负类指数:3个正类指数:2学习者3(SVM)的拟合后验概率。GyD.F4y2Ba
MdlGyD.F4y2Ba是一个GyD.F4y2BaClassificationECOCGyD.F4y2Ba模型。同样的SVM模板适用于每个二进制学习,但你可以通过在模板的细胞载体调整每个二进制学习者选择。GyD.F4y2Ba
预测训练样本标签和一流的后验概率。通过使用显示标签和类后验概率的计算期间的诊断消息GyD.F4y2Ba“详细”GyD.F4y2Ba名称-值对的论点。GyD.F4y2Ba
[标签,~,~,后]= resubPredict (Mdl,GyD.F4y2Ba“详细”GyD.F4y2Ba1);GyD.F4y2Ba
对所有学习者的预测都进行了计算。计算了所有观测的损失。计算后验概率…GyD.F4y2Ba
Mdl。BinaryLossGyD.F4y2Ba
ans =“二次”GyD.F4y2Ba
该软件将观察结果分配给产生最小平均二进制损失的班级。由于所有二进制学习器都在计算后验概率,因此二进制损失函数为GyD.F4y2Ba二次GyD.F4y2Ba.GyD.F4y2Ba
显示一组随机的结果。GyD.F4y2Ba
idx = randsample(大小(X, 1), 10日1);Mdl。CL.一种S.S.的名字S.GyD.F4y2Ba
ans =GyD.F4y2Ba3x1细胞GyD.F4y2Ba{'setosa'} {'versicolor'} {'virginica'}GyD.F4y2Ba
表(Y(IDX),标签(IDX),后退(IDX,:),GyD.F4y2Ba...GyD.F4y2Ba“VariableNames”GyD.F4y2Ba,{GyD.F4y2Ba'truilabel'GyD.F4y2Ba那GyD.F4y2Ba'predlabel'GyD.F4y2Ba那GyD.F4y2Ba'后后'GyD.F4y2Ba})GyD.F4y2Ba
ANS =GyD.F4y2Ba10×3表GyD.F4y2BaTrueLabel PredLabel后 ______________ ______________ ______________________________________ {' virginica’}{‘virginica} 0.0039322 0.003987 0.99208{‘virginica}{‘virginica} 0.017067 0.018263 0.96467{‘virginica}{‘virginica} 0.014948 0.015856 0.9692{“癣”}{“癣”}2.2197 e-14 0.87318 - 0.12682{‘setosa} {' setosa '}0.999 0.029985 {'versicolor'} {'versicolor'}} 0.0085642 0.98259 0.0088487 {'setosa'} {'setosa'} 0.999 0.00024992 0.0088487 {'setosa'} {'setosa'} 0.999 0.00024913 0.00074717GyD.F4y2Ba
列的列GyD.F4y2Ba后GyD.F4y2Ba对应于的类序GyD.F4y2BaMdl。CL.一种S.S.的名字S.GyD.F4y2Ba.GyD.F4y2Ba
在观测的预测器空间中定义一个网格值。预测网格中每个实例的后验概率。GyD.F4y2Ba
xMax = max (X);xMin = min (X);x1Pts = linspace (xMin (1) xMax (1));xMax x2Pts = linspace (xMin (2), (2));[x1Grid, x2Grid] = meshgrid (x1Pts x2Pts);[~, ~, ~, PosteriorRegion] =预测(Mdl, [x1Grid (:), x2Grid (:)));GyD.F4y2Ba
对于网格上的每个坐标,请在所有类别中绘制最大类后概率。GyD.F4y2Ba
contourf (x1Grid x2Grid,GyD.F4y2Ba...GyD.F4y2Ba重塑(max (PosteriorRegion[], 2),大小(x1Grid, 1),大小(x1Grid, 2)));h = colorbar;h.YLabel.String =GyD.F4y2Ba'最大后后'GyD.F4y2Ba;h.YLabel.FontSize = 15;抓住GyD.F4y2Ba在GyD.F4y2Bagh = gscatter (X (: 1), X (:, 2), Y,GyD.F4y2Ba'KRK'GyD.F4y2Ba那GyD.F4y2Ba‘* xd‘GyD.F4y2Ba8);gh(2)。L.一世NE.宽度=2;gh(3)。L.一世NE.宽度= 2; title('虹膜瓣测量和最大后后'GyD.F4y2Ba)包含(GyD.F4y2Ba“花瓣长度(厘米)”GyD.F4y2Ba) ylabel (GyD.F4y2Ba“花瓣宽度(cm)”GyD.F4y2Ba)轴GyD.F4y2Ba紧的GyD.F4y2Ba传奇(gh,GyD.F4y2Ba'地点'GyD.F4y2Ba那GyD.F4y2Ba“西北”GyD.F4y2Ba)举行GyD.F4y2Ba从GyD.F4y2Ba
使用bin和并行计算加速训练ECOC分类器GyD.F4y2Ba
使用a列车一个与所有ecoc分类器GyD.F4y2Ba温博GyD.F4y2Ba决策树与代理分裂的集合。加快培训,箱数字预测器并使用并行计算。啤酒才有效GyD.F4y2BafitcecocGyD.F4y2Ba使用树学习者。训练后,使用10倍交叉验证估计分类误差。请注意,并行计算需要parallel computing Toolbox™。GyD.F4y2Ba
加载样本数据GyD.F4y2Ba
装入并检查GyD.F4y2Ba心律失常GyD.F4y2Ba数据集。GyD.F4y2Ba
负载GyD.F4y2Ba心律失常GyD.F4y2Ba(氮、磷)大小(X) =GyD.F4y2Ba
n = 452GyD.F4y2Ba
p = 279GyD.F4y2Ba
isLabels =独特(Y);nLabels =元素个数(isLabels)GyD.F4y2Ba
nlabels = 13.GyD.F4y2Ba
汇总(分类(Y))GyD.F4y2Ba
值计数百分比1 245 54.20%2 44 9.73%3 15 3.32%4 15 3.32%513 2.88%6 25 5.53%7 3 0.66%8 2 0.44%9 9 1.90%10 50 11.06%14 0.88%11.06%14 0.88%15 5 1.11%16 22 4.87%GyD.F4y2Ba
数据集包含GyD.F4y2Ba279GyD.F4y2Ba预测因素和样本量GyD.F4y2Ba452GyD.F4y2Ba相对较小。在16个不同的标签中,只有13个在响应中表示(GyD.F4y2BayGyD.F4y2Ba).每个标签描述各种心律失常,54.20%的观察员在课堂上GyD.F4y2Ba1GyD.F4y2Ba.GyD.F4y2Ba
训练一个对所有ECOC分类器GyD.F4y2Ba
创建集成模板。您必须指定至少三个参数:方法、学习者的数量和学习者的类型。对于本例,请指定GyD.F4y2Ba'温船'GyD.F4y2Ba对于方法,GyD.F4y2BaOne hundred.GyD.F4y2Ba对于学习者的数量,以及由于缺少观察结果而使用代理拆分的决策树模板。GyD.F4y2Ba
tTree = templateTree(GyD.F4y2Ba“代孕”GyD.F4y2Ba那GyD.F4y2Ba“上”GyD.F4y2Ba);tEnsemble = templateEnsemble (GyD.F4y2Ba'温船'GyD.F4y2Ba, 100年,tTree);GyD.F4y2Ba
tEnsembleGyD.F4y2Ba是模板对象。它的大部分属性都是空的,但是软件在训练期间用它们的默认值填充它们。GyD.F4y2Ba
使用决策树的集合作为二叉学习器来训练一个一对所有的ECOC分类器。为了加快训练速度,可以使用装箱和并行计算。GyD.F4y2Ba
啤酒(GyD.F4y2Ba
“NumBins”,50岁GyD.F4y2Ba) -当你有一个大的训练数据集时,你可以通过使用GyD.F4y2Ba“NumBins”GyD.F4y2Ba名称-值对的论点。此参数仅在以下情况下有效GyD.F4y2BafitcecocGyD.F4y2Ba使用树学习者。如果您指定了GyD.F4y2Ba“NumBins”GyD.F4y2Ba值,然后将软件将每个数字预测器置于指定数量的eciprobable bins中,然后在箱上的树木上生长树木指数而不是原始数据。你可以试试GyD.F4y2Ba“NumBins”,50岁GyD.F4y2Ba先改,再改GyD.F4y2Ba“NumBins”GyD.F4y2Ba值取决于准确性和训练速度。GyD.F4y2Ba并行计算(GyD.F4y2Ba
'选项',statset('deverypallellel',true)GyD.F4y2Ba) - 用一个并行计算工具箱许可证,则可以加快通过使用并行计算,它发送每个二进制学习者到池中一个工人的计算。工人的数量取决于您的系统配置。当你对二进制学习者使用决策树时,GyD.F4y2BafitcecocGyD.F4y2Ba使用英特尔®线程构建块(TBB)并行训练双核或以上系统。因此,指定GyD.F4y2Ba“UseParallel”GyD.F4y2Ba选项在单个计算机上没有帮助。在集群上使用此选项。GyD.F4y2Ba
另外,指定先验概率为1/GyD.F4y2BaK.GyD.F4y2Ba, 在哪里GyD.F4y2BaK.GyD.F4y2Ba= 13是不同类的数量。GyD.F4y2Ba
选项= statset(GyD.F4y2Ba“UseParallel”GyD.F4y2Ba,真的);mdl = fitcecoc(x,y,GyD.F4y2Ba“编码”GyD.F4y2Ba那GyD.F4y2Ba'Onevsall'GyD.F4y2Ba那GyD.F4y2Ba'学习者'GyD.F4y2BatEnsemble,GyD.F4y2Ba...GyD.F4y2Ba'事先的'GyD.F4y2Ba那GyD.F4y2Ba“统一”GyD.F4y2Ba那GyD.F4y2Ba“NumBins”GyD.F4y2Ba, 50岁,GyD.F4y2Ba“选项”GyD.F4y2Ba,选项);GyD.F4y2Ba
使用“local”配置文件启动并行池(parpool)…连接到并行池(工作人员数量:6)。GyD.F4y2Ba
MdlGyD.F4y2Ba是一个GyD.F4y2BaClassificationECOCGyD.F4y2Ba模型。GyD.F4y2Ba
交叉验证GyD.F4y2Ba
使用10倍交叉验证交叉验证ECOC分类器。GyD.F4y2Ba
cvmdl = crossval(mdl,GyD.F4y2Ba“选项”GyD.F4y2Ba,选项);GyD.F4y2Ba
警告:一个或多个折叠不包含来自所有组的点。GyD.F4y2Ba
CVMdlGyD.F4y2Ba是一个GyD.F4y2BaClassificationPartitionedECOCGyD.F4y2Ba模型。警告表示某些类未在软件列到至少一个折叠时表示。因此,这些折叠无法预测缺失类的标签。您可以使用小区索引和点表示法检查折叠的结果。例如,通过进入访问第一个折叠的结果GyD.F4y2BaCVMdl。训练有素的{1}GyD.F4y2Ba.GyD.F4y2Ba
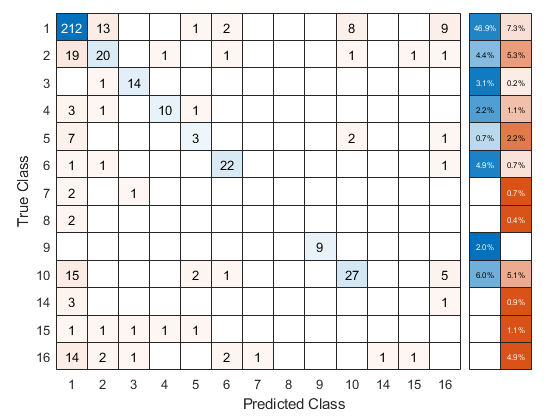
使用交叉验证的ECOC分类器来预测验证折叠标签。你可以用GyD.F4y2BaconfusionchartGyD.F4y2Ba.通过更改内部位置属性来移动和调整图表的大小,以确保百分比出现在行摘要中。GyD.F4y2Ba
Ooflabel = kfoldpredict(cvmdl,GyD.F4y2Ba“选项”GyD.F4y2Ba,选项);Confmat = ConfusionChart(Y,Ooflabel,GyD.F4y2Ba'rowsmumary'GyD.F4y2Ba那GyD.F4y2Ba“total-normalized”GyD.F4y2Ba);ConfMat。在NE.rPosition = [0.10 0.12 0.85 0.85];
复制分箱数据GyD.F4y2Ba
通过使用GyD.F4y2Ba毕业生GyD.F4y2Ba训练模型的性质和GyD.F4y2Ba离散化GyD.F4y2Ba函数。GyD.F4y2Ba
X = Mdl.X;GyD.F4y2Ba%预测仪数据GyD.F4y2BaXbinned = 0(大小(X));边缘= Mdl.BinEdges;GyD.F4y2Ba%查找分级预测的指标。GyD.F4y2BaidxNumeric =找到(~ cellfun (@isempty边缘));GyD.F4y2Ba如果GyD.F4y2Baiscolumn(idxNumeric) idxNumeric = idxNumeric';GyD.F4y2Ba结束GyD.F4y2Ba为GyD.F4y2Baj = idxNumeric x = x (:,j);GyD.F4y2Ba如果x是表,%将x转换为数组。GyD.F4y2Ba如果GyD.F4y2BaIstable (x) x = table2array(x);GyD.F4y2Ba结束GyD.F4y2Ba%使用离散函数将x分组到bins中。GyD.F4y2Baxbinned =离散化(x,[无穷;边缘{};正]);Xbinned (:, j) = Xbinned;GyD.F4y2Ba结束GyD.F4y2Ba
xbinned.GyD.F4y2Ba包含用于数字预测器的容器索引,范围从1到容器数量。GyD.F4y2Baxbinned.GyD.F4y2Ba值是GyD.F4y2Ba0.GyD.F4y2Ba对于分类预测器。如果GyD.F4y2BaXGyD.F4y2Ba包含GyD.F4y2Ba南GyD.F4y2Bas,然后相应的GyD.F4y2Baxbinned.GyD.F4y2Ba值是GyD.F4y2Ba南GyD.F4y2Ba年代。GyD.F4y2Ba
优化Ecoc分类器GyD.F4y2Ba
自动优化HyperParametersGyD.F4y2BafitcecocGyD.F4y2Ba.GyD.F4y2Ba
加载GyD.F4y2BafisheririsGyD.F4y2Ba数据集。GyD.F4y2Ba
负载GyD.F4y2BafisheririsGyD.F4y2BaX =量;y =物种;GyD.F4y2Ba
找到通过使用自动封路计优化来最小化五倍交叉验证损耗的高参数。为了再现性,设置随机种子并使用GyD.F4y2Ba'预期改善加'GyD.F4y2Ba采集功能。GyD.F4y2Ba
rngGyD.F4y2Ba默认的GyD.F4y2Bamdl = fitcecoc(x,y,GyD.F4y2Ba“OptimizeHyperparameters”GyD.F4y2Ba那GyD.F4y2Ba'汽车'GyD.F4y2Ba那GyD.F4y2Ba...GyD.F4y2Ba“HyperparameterOptimizationOptions”GyD.F4y2Ba结构(GyD.F4y2Ba'获取功能名称'GyD.F4y2Ba那GyD.F4y2Ba...GyD.F4y2Ba'预期改善加'GyD.F4y2Ba)))GyD.F4y2Ba
| ==================================================================================================================== ||磨练|eval |目标|目标|Bestsofar |Bestsofar |编码|boxconstraint | KernelScale | | | result | | runtime | (observed) | (estim.) | | | | |====================================================================================================================| | 1 | Best | 0.10667 | 0.98396 | 0.10667 | 0.10667 | onevsone | 5.6939 | 200.36 | | 2 | Best | 0.066667 | 3.6612 | 0.066667 | 0.068735 | onevsone | 94.849 | 0.0032549 | | 3 | Accept | 0.08 | 0.4554 | 0.066667 | 0.066837 | onevsall | 0.01378 | 0.076021 | | 4 | Accept | 0.08 | 0.24984 | 0.066667 | 0.066676 | onevsall | 889 | 38.798 | | 5 | Best | 0.04 | 0.52661 | 0.04 | 0.040502 | onevsone | 0.021561 | 0.01569 | | 6 | Accept | 0.04 | 0.32599 | 0.04 | 0.039999 | onevsone | 0.48338 | 0.02941 | | 7 | Accept | 0.04 | 0.33704 | 0.04 | 0.039989 | onevsone | 305.45 | 0.18647 | | 8 | Best | 0.026667 | 0.36611 | 0.026667 | 0.026674 | onevsone | 0.0010168 | 0.10757 | | 9 | Accept | 0.086667 | 0.24971 | 0.026667 | 0.026669 | onevsone | 0.001007 | 0.3275 | | 10 | Accept | 0.046667 | 1.3398 | 0.026667 | 0.026673 | onevsone | 736.18 | 0.071026 | | 11 | Accept | 0.04 | 0.35546 | 0.026667 | 0.035679 | onevsone | 35.928 | 0.13079 | | 12 | Accept | 0.033333 | 0.31774 | 0.026667 | 0.030065 | onevsone | 0.0017593 | 0.11245 | | 13 | Accept | 0.026667 | 0.26496 | 0.026667 | 0.026544 | onevsone | 0.0011306 | 0.062222 | | 14 | Accept | 0.026667 | 0.34133 | 0.026667 | 0.026089 | onevsone | 0.0011124 | 0.079161 | | 15 | Accept | 0.026667 | 0.24303 | 0.026667 | 0.026184 | onevsone | 0.0014395 | 0.073096 | | 16 | Best | 0.02 | 0.207 | 0.02 | 0.021144 | onevsone | 0.0010299 | 0.035054 | | 17 | Accept | 0.02 | 0.33381 | 0.02 | 0.020431 | onevsone | 0.0010379 | 0.03138 | | 18 | Accept | 0.033333 | 0.25211 | 0.02 | 0.024292 | onevsone | 0.0011889 | 0.02915 | | 19 | Accept | 0.02 | 0.31439 | 0.02 | 0.022327 | onevsone | 0.0011336 | 0.042445 | | 20 | Best | 0.013333 | 0.32092 | 0.013333 | 0.020178 | onevsone | 0.0010854 | 0.048345 | |====================================================================================================================| | Iter | Eval | Objective | Objective | BestSoFar | BestSoFar | Coding | BoxConstraint| KernelScale | | | result | | runtime | (observed) | (estim.) | | | | |====================================================================================================================| | 21 | Accept | 0.5 | 13.143 | 0.013333 | 0.020718 | onevsall | 689.42 | 0.001007 | | 22 | Accept | 0.33333 | 0.33577 | 0.013333 | 0.018299 | onevsall | 0.0011091 | 1.2155 | | 23 | Accept | 0.33333 | 0.38918 | 0.013333 | 0.017851 | onevsall | 529.11 | 372.18 | | 24 | Accept | 0.04 | 0.20733 | 0.013333 | 0.017879 | onevsone | 853.41 | 22.141 | | 25 | Accept | 0.046667 | 0.21844 | 0.013333 | 0.018114 | onevsone | 744.03 | 6.3339 | | 26 | Accept | 0.10667 | 0.31981 | 0.013333 | 0.018226 | onevsone | 0.0010775 | 999.54 | | 27 | Accept | 0.04 | 0.26125 | 0.013333 | 0.018557 | onevsone | 0.0020893 | 0.001005 | | 28 | Accept | 0.10667 | 0.30651 | 0.013333 | 0.019634 | onevsone | 0.0010666 | 12.404 | | 29 | Accept | 0.32 | 12.703 | 0.013333 | 0.018352 | onevsall | 951.6 | 0.027202 | | 30 | Accept | 0.04 | 0.24213 | 0.013333 | 0.018597 | onevsone | 936.87 | 1.7813 |
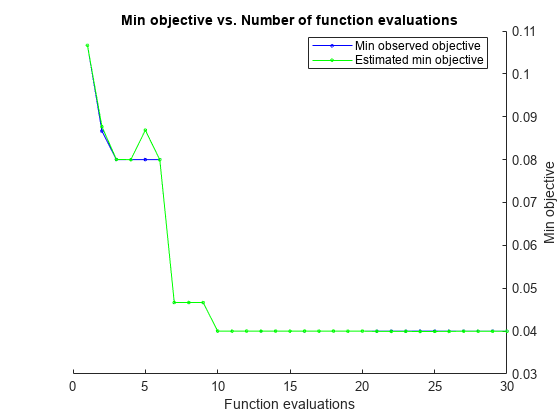
__________________________________________________________ 优化完成。maxobjective达到30个。总函数计算:30总运行时间:62.709秒总目标函数计算时间:39.5724最佳观测可行点:编码框约束KernelScale ________ _____________ ___________ onevsone 0.0010854 0.048345观测目标函数值= 0.013333估计目标函数值= 0.018594函数计算时间= 0.32092最佳估计可行点(根据模型):编码框约束KernelScale ________ _____________ ___________ onevsone 0.0011336 0.042445估计的目标函数值= 0.018597估计的函数计算时间= 0.2867GyD.F4y2Ba
mdl = classificationecoc racitchename:'y'pationoricalpricictors:[] classnames:{'setosa''versicolor''virginica'} scoreTransform:'none'binarylearners:{3x1 cell} codingname:'Onevsone'HyperParetErtimizationResults:[1x1贝叶斯optimization]属性,方法GyD.F4y2Ba
用支持向量机和高阵训练多类ECOC模型GyD.F4y2Ba
创建两个在高数据上培训的多种多组ECOC型号。为另一个模型和内核二进制学习者使用线性二进制学习者。比较两种模型的重新提交分类错误。GyD.F4y2Ba
一般而言,您可以通过使用执行多款数据的高数据分类GyD.F4y2BafitcecocGyD.F4y2Ba用线性或核二进制学习器。当你使用GyD.F4y2BafitcecocGyD.F4y2Ba要在高数组上训练模型,你不能直接使用SVM二进制学习器。但是,您可以使用使用svm的线性或内核二进制分类模型。GyD.F4y2Ba
当您在高数组上执行计算时,MATLAB®使用一个并行池(如果您有parallel Computing Toolbox™,则默认)或本地MATLAB会话。如果您希望在拥有Parallel Computing Toolbox时使用本地MATLAB会话运行该示例,则可以通过使用GyD.F4y2BamapreduceGyD.F4y2Ba函数。GyD.F4y2Ba
创建引用包含Fisher虹膜数据集的文件夹的数据存储。指定GyD.F4y2Ba“NA”GyD.F4y2Ba值作为缺少数据的值GyD.F4y2Ba数据存储GyD.F4y2Ba取代他们GyD.F4y2Ba南GyD.F4y2Ba值。创建预测器和响应数据的高版本。GyD.F4y2Ba
ds =数据存储(GyD.F4y2Ba'fisheriris.csv'GyD.F4y2Ba那GyD.F4y2Ba“TreatAsMissing”GyD.F4y2Ba那GyD.F4y2Ba“NA”GyD.F4y2Ba);t =高(ds);GyD.F4y2Ba
使用“local”配置文件启动并行池(parpool)…连接到并行池(工作人员数量:6)。GyD.F4y2Ba
X = [t.SepalLength t.SepalWidth t.PetalLength t.PetalWidth];Y = t.Species;GyD.F4y2Ba
标准化预测数据。GyD.F4y2Ba
Z = zscore (X);GyD.F4y2Ba
火车使用高数据和线性二进制学习者的多种多组ECOC模型。默认情况下,当您将高阵列传递到GyD.F4y2BafitcecocGyD.F4y2Ba,软件培训使用SVM的线性二进制学习者。因为响应数据只包含三个唯一类,所以将编码方案从一个与所有(默认值)更改为毫无(默认值)(在您使用内存数据时是默认值)。GyD.F4y2Ba
为了再现性,使用。设置随机数生成器的种子GyD.F4y2BarngGyD.F4y2Ba和GyD.F4y2BatallrngGyD.F4y2Ba.结果可能会根据高数组的工作人员数量和执行环境而有所不同。有关详细信息,请参阅GyD.F4y2Ba控制代码运行的位置GyD.F4y2Ba.GyD.F4y2Ba
rng (GyD.F4y2Ba'默认'GyD.F4y2Ba) tallrng (GyD.F4y2Ba'默认'GyD.F4y2Ba) mdlLinear = fitcecoc(Z,Y,GyD.F4y2Ba“编码”GyD.F4y2Ba那GyD.F4y2Ba“onevsone”GyD.F4y2Ba)GyD.F4y2Ba
训练二元学习者1(线性)3。训练二元学习者2(线性)3。训练二元学习者3(线性)的3。GyD.F4y2Ba
mdlLinear = CompactClassificationECOC ResponseName: 'Y' ClassNames: {'setosa' 'versicolor' 'virginica'} ScoreTransform: 'none' BinaryLearners: {3×1 cell} CodingMatrix: [3×3 double]属性,方法GyD.F4y2Ba
mdlLinearGyD.F4y2Ba是一个GyD.F4y2BaCompactClassificationECOCGyD.F4y2Ba模型由三个二元学习者组成。GyD.F4y2Ba
训练一个使用高数据和内核二进制学习器的多类ECOC模型。首先,创建一个GyD.F4y2BaTemplateKernel.GyD.F4y2Ba对象以指定内核二进制学习者的性能;特别是,增加扩展的维数,以GyD.F4y2Ba
.GyD.F4y2Ba
tKernel = templateKernel (GyD.F4y2Ba“NumExpansionDimensions”GyD.F4y2Ba2 ^ 16)GyD.F4y2Ba
tKernel =适合Kernel分类的模板。betaterance: [] BlockSize: [] BoxConstraint: [] Epsilon: [] NumExpansionDimensions: 65536 GradientTolerance: [] HessianHistorySize: [] IterationLimit: [] KernelScale: [] Lambda: [] Learner: 'svm' LossFunction: [] Stream: [] VerbosityLevel: [] Version: 1 Method: 'Kernel' Type: 'classification'GyD.F4y2Ba
默认情况下,内核二进制学习器使用支持向量机。GyD.F4y2Ba
通过GyD.F4y2BaTemplateKernel.GyD.F4y2Ba对象GyD.F4y2BafitcecocGyD.F4y2Ba然后把编码改成一对一。GyD.F4y2Ba
mdlKernel = fitcecoc (Z, Y,GyD.F4y2Ba'学习者'GyD.F4y2BatKernel,GyD.F4y2Ba“编码”GyD.F4y2Ba那GyD.F4y2Ba“onevsone”GyD.F4y2Ba)GyD.F4y2Ba
培训二进制学习者1(内核)。培训二进制学习者2(内核)的3.培训二进制学习者3(内核)中的3个。GyD.F4y2Ba
mdlkernel = compactClassificyecoc racitchename:'y'classnames:{'setosa''versicolor''virginica'} scoreTransform:'无'BinaryLearners:{3×1个单元} CodingMatrix:[3×3双]属性,方法GyD.F4y2Ba
mdlKernelGyD.F4y2Ba也是A.GyD.F4y2BaCompactClassificationECOCGyD.F4y2Ba模型由三个二元学习者组成。GyD.F4y2Ba
比较两种模型的重新提交分类错误。GyD.F4y2Ba
errorlinear =收集(丢失(mdllinear,z,y)))GyD.F4y2Ba
使用Parallel Pool 'local'计算tall表达式GyD.F4y2Ba
errorlinear = 0.0333.GyD.F4y2Ba
errorKernel =收集(损失(mdlKernel, Z, Y))GyD.F4y2Ba
评估使用并行池“本地”高表达: - 的1遍1:在15秒评价完成在16秒完成GyD.F4y2Ba
errorkernel = 0.0067.GyD.F4y2Ba
mdlKernelGyD.F4y2Ba误分类训练数据的百分比小于GyD.F4y2BamdlLinearGyD.F4y2Ba.GyD.F4y2Ba
输入参数GyD.F4y2Ba
输出参数GyD.F4y2Ba
限制GyD.F4y2Ba
fitcecocGyD.F4y2Ba金宝app仅支持稀疏矩阵用于训练线性分类模型。对于所有其他型号,提供预测数据的完整矩阵来代替。GyD.F4y2Ba
更多关于GyD.F4y2Ba
编码设计GyD.F4y2Ba
一种GyD.F4y2Ba编码设计GyD.F4y2Ba是一个矩阵,其中元素是由每个二进制学习者训练哪个类的元素,即,多字符问题如何减少到一系列二元问题。GyD.F4y2Ba
编码设计的每一行对应一个不同的类,每一列对应一个二元学习者。在三元编码设计中,对于特定的列(或二元学习者):GyD.F4y2Ba
包含1的一行指示二元学习者将对应类中的所有观察结果分组为一个积极类。GyD.F4y2Ba
包含-1的行将二进制学习者指导将相应阶级的所有观测分组到负类中。GyD.F4y2Ba
包含0的行指示二进制学习者忽略对应类中的所有观察值。GyD.F4y2Ba
基于汉明测度的大、最小、成对行距离的编码设计矩阵是最优的。关于双行距离的详细信息请参见GyD.F4y2Ba随机编码设计矩阵GyD.F4y2Ba和GyD.F4y2Ba[4]GyD.F4y2Ba.GyD.F4y2Ba
此表描述了流行的编码设计。GyD.F4y2Ba
| 编码设计GyD.F4y2Ba | 描述GyD.F4y2Ba | 学习者人数GyD.F4y2Ba | 最小的成对行距离GyD.F4y2Ba |
|---|---|---|---|
| one-versus-all(卵子)GyD.F4y2Ba | 对于每个二元学习者来说,有一类是正面的,其余的是负面的。这个设计用尽了积极的课堂作业的所有组合。GyD.F4y2Ba | K.GyD.F4y2Ba | 2GyD.F4y2Ba |
| 一对 - 一(ovo)GyD.F4y2Ba | 对于每一个二元学习者,一个类是积极的,另一个类是消极的,其余的则被忽略。该设计排除了类对分配的所有组合。GyD.F4y2Ba | K.GyD.F4y2Ba(GyD.F4y2BaK.GyD.F4y2Ba- 1) / 2GyD.F4y2Ba |
1GyD.F4y2Ba |
| 二进制文件完成GyD.F4y2Ba | 这种设计将类划分为所有的二进制组合,并且不忽略任何类。也就是说,所有班级任务都是GyD.F4y2Ba |
2GyD.F4y2BaK.GyD.F4y2Ba- 1GyD.F4y2Ba- 1GyD.F4y2Ba | 2GyD.F4y2BaK.GyD.F4y2Ba- 2GyD.F4y2Ba |
| 三元完成GyD.F4y2Ba | 此设计将类分为所有三元组合。也就是说,所有班级任务都是GyD.F4y2Ba |
(3.GyD.F4y2BaK.GyD.F4y2Ba- 2GyD.F4y2BaK.GyD.F4y2Ba+ 1GyD.F4y2Ba+ 1)/ 2GyD.F4y2Ba |
3.GyD.F4y2BaK.GyD.F4y2Ba- 2GyD.F4y2Ba |
| 序数GyD.F4y2Ba | 对于第一个二元学习者,第一堂课是消极的,其余的是积极的。对于第二个二元学习者,前两个类是否定的,其余类是肯定的,以此类推。GyD.F4y2Ba | K.GyD.F4y2Ba- 1GyD.F4y2Ba | 1GyD.F4y2Ba |
| 密集的随机GyD.F4y2Ba | 对于每个二进制学习者,软件将类分配为正或负类,每种类型中的至少一个。有关更多详细信息,请参阅GyD.F4y2Ba随机编码设计矩阵GyD.F4y2Ba.GyD.F4y2Ba | 随机,但大约10个日志GyD.F4y2Ba2GyD.F4y2BaK.GyD.F4y2Ba |
变量GyD.F4y2Ba |
| 稀疏随机GyD.F4y2Ba | 对于每个二进制学习者,软件随机将类别分配为正或负,概率为0.25,并忽略概率0.5的类。有关更多详细信息,请参阅GyD.F4y2Ba随机编码设计矩阵GyD.F4y2Ba.GyD.F4y2Ba | 随机,但大约15个日志GyD.F4y2Ba2GyD.F4y2BaK.GyD.F4y2Ba |
变量GyD.F4y2Ba |
这张图比较了编码设计中二进制学习器的数量随增加而增加的情况GyD.F4y2BaK.GyD.F4y2Ba.GyD.F4y2Ba

提示GyD.F4y2Ba
二进制学习者数量的增长与类的数量。对于许多类的问题时,GyD.F4y2Ba
二进制组合GyD.F4y2Ba和GyD.F4y2Ba短跑GyD.F4y2Ba编码设计是低效的。然而:GyD.F4y2Ba如果GyD.F4y2BaK.GyD.F4y2Ba≤4,则使用GyD.F4y2Ba
短跑GyD.F4y2Ba编码设计而不是GyD.F4y2BasparserandomGyD.F4y2Ba.GyD.F4y2Ba如果GyD.F4y2BaK.GyD.F4y2Ba≤5,则使用GyD.F4y2Ba
二进制组合GyD.F4y2Ba编码设计而不是GyD.F4y2BadenserandomGyD.F4y2Ba.GyD.F4y2Ba
您可以通过输入显示培训的ECOC分类器的编码设计矩阵GyD.F4y2Ba
mdl.codingmatrix.GyD.F4y2Ba进入命令窗口。GyD.F4y2Ba您应该使用对应用程序的熟悉知识来形成一个编码矩阵,并考虑到计算约束。如果你有足够的计算能力和时间,那么尝试几个编码矩阵,并选择一个性能最好的(例如,检查每个模型使用的混淆矩阵GyD.F4y2Ba
confusionchartGyD.F4y2Ba).GyD.F4y2Ba分析交叉验证(GyD.F4y2Ba
LeaveoutGyD.F4y2Ba)对于具有许多观察的数据集是效率低下。相反,使用GyD.F4y2BaK.GyD.F4y2Ba倍交叉验证(GyD.F4y2BaKFoldGyD.F4y2Ba).GyD.F4y2Ba
培训模型后,您可以生成C / C ++代码,该代码预测新数据的标签。生成C / C ++代码需要GyD.F4y2BaMATLAB编码器™GyD.F4y2Ba.有关详细信息,请参阅GyD.F4y2Ba代码生成简介GyD.F4y2Ba.GyD.F4y2Ba
算法GyD.F4y2Ba
参考文献GyD.F4y2Ba
艾尔温,E.夏皮尔,Y.辛格。《将多类减少为二进制:一种统一的保证金分类方法》。GyD.F4y2Ba机器学习研究杂志GyD.F4y2Ba.2000年第1卷,113-141页。GyD.F4y2Ba
[2] Fürnkranz,约翰内斯,《轮循分类》。GyD.F4y2Baj·马赫。学习。Res。GyD.F4y2Ba, 2002年第2卷,721-747页。GyD.F4y2Ba
Pujol, S. Escalera, S. O. Pujol, P. Radeva。《论三元纠错输出码的译码过程》。GyD.F4y2Ba模式分析与机器智能学报GyD.F4y2Ba.2010年第32卷第7期120-134页。GyD.F4y2Ba
Pujol, S. Escalera, S. O. Pujol, P. Radeva。用于纠错输出码稀疏设计的三元码的可分性。GyD.F4y2Ba模式recog。吧。GyD.F4y2Ba, Vol. 30, Issue 3, 2009, pp. 285-297。GyD.F4y2Ba
扩展功能GyD.F4y2Ba
另请参阅GyD.F4y2Ba
ClassificationECOCGyD.F4y2Ba|GyD.F4y2BaClassificationPartitionedECOCGyD.F4y2Ba|GyD.F4y2BaClassificationPartitionedKernelECOCGyD.F4y2Ba|GyD.F4y2BaClassificationPartitionedLinearECOCGyD.F4y2Ba|GyD.F4y2BaCompactClassificationECOCGyD.F4y2Ba|GyD.F4y2BadesignecocGyD.F4y2Ba|GyD.F4y2Ba损失GyD.F4y2Ba|GyD.F4y2Ba预测GyD.F4y2Ba|GyD.F4y2Ba实例化GyD.F4y2Ba
选择一个网站GyD.F4y2Ba
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:GyD.F4y2Ba.GyD.F4y2Ba
选择GyD.F4y2Ba网站GyD.F4y2Ba您还可以从以下列表中选择一个网站:GyD.F4y2Ba
美洲GyD.F4y2Ba
- América拉丁GyD.F4y2Ba(Español)GyD.F4y2Ba
- 加拿大GyD.F4y2Ba(英语)GyD.F4y2Ba
- 美国GyD.F4y2Ba(英语)GyD.F4y2Ba
欧洲GyD.F4y2Ba
- 比利时GyD.F4y2Ba(英语)GyD.F4y2Ba
- 丹麦GyD.F4y2Ba(英语)GyD.F4y2Ba
- 德国GyD.F4y2Ba(德语)GyD.F4y2Ba
- 西班牙GyD.F4y2Ba(Español)GyD.F4y2Ba
- 芬兰GyD.F4y2Ba(英语)GyD.F4y2Ba
- 法国GyD.F4y2Ba(法语)GyD.F4y2Ba
- 爱尔兰GyD.F4y2Ba(英语)GyD.F4y2Ba
- 意大利GyD.F4y2Ba(意大利语)GyD.F4y2Ba
- 卢森堡GyD.F4y2Ba(英语)GyD.F4y2Ba
- 荷兰GyD.F4y2Ba(英语)GyD.F4y2Ba
- 挪威GyD.F4y2Ba(英语)GyD.F4y2Ba
- 奥地利GyD.F4y2Ba(德语)GyD.F4y2Ba
- 葡萄牙GyD.F4y2Ba(英语)GyD.F4y2Ba
- 瑞典GyD.F4y2Ba(英语)GyD.F4y2Ba
- 瑞士GyD.F4y2Ba
- 英国GyD.F4y2Ba(英语)GyD.F4y2Ba
亚太地区GyD.F4y2Ba
- 澳大利亚GyD.F4y2Ba(英语)GyD.F4y2Ba
- 印度GyD.F4y2Ba(英语)GyD.F4y2Ba
- 新西兰GyD.F4y2Ba(英语)GyD.F4y2Ba
- 中国GyD.F4y2Ba
- 日本GyD.F4y2Ba(日本语)GyD.F4y2Ba
- 한국GyD.F4y2Ba(한국어)GyD.F4y2Ba
