重新预订GydF4y2Ba
在多种误差校正输出代码(ECOC)模型中分类观察GydF4y2Ba
句法GydF4y2Ba
描述GydF4y2Ba
标签GydF4y2Ba= ResubPredict(GydF4y2BaMDL.GydF4y2Ba)GydF4y2Ba标签GydF4y2Ba)对于训练有素的多款纠错输出代码(ECOC)模型GydF4y2BaMDL.GydF4y2Ba使用存储的预测器数据GydF4y2BaMdl。XGydF4y2Ba.GydF4y2Ba
该软件通过将观察分配给阶级的观察来预测观察的分类,产生最大的否定平均二进制损失(或等效,平均二进制损失最小)。GydF4y2Ba
标签GydF4y2Ba= ResubPredict(GydF4y2BaMDL.GydF4y2Ba那GydF4y2Ba名称,价值GydF4y2Ba)GydF4y2Ba
[GydF4y2Ba使用前面语法中的任何输入参数组合,并额外返回负平均值GydF4y2Ba二元损失GydF4y2Ba每个类(GydF4y2Ba标签GydF4y2Ba那GydF4y2BaneglGydF4y2Ba那GydF4y2BaPBScoreGydF4y2Ba] = ResubPredict(GydF4y2Ba___GydF4y2Ba)GydF4y2BaneglGydF4y2Ba)进行观察,而正向评分(GydF4y2BaPBScoreGydF4y2Ba),以获取由每个二元学习者分类的观察结果。GydF4y2Ba
[GydF4y2Ba另外,返回观测值的后验类别概率估计值(GydF4y2Ba标签GydF4y2Ba那GydF4y2BaneglGydF4y2Ba那GydF4y2BaPBScoreGydF4y2Ba那GydF4y2Ba后面GydF4y2Ba] = ResubPredict(GydF4y2Ba___GydF4y2Ba)GydF4y2Ba后面GydF4y2Ba).GydF4y2Ba
要获得后验类别概率,必须设置GydF4y2Ba“FitPosterior”,真的GydF4y2Ba使用时培训ECOC模型GydF4y2BafitcecocGydF4y2Ba.除此以外,GydF4y2Ba重新预订GydF4y2Ba抛出一个错误。GydF4y2Ba
例子GydF4y2Ba
用ECOC模型预测训练数据的标签GydF4y2Ba
载入费雪的虹膜数据集。指定预测器数据GydF4y2BaXGydF4y2Ba,响应数据GydF4y2BayGydF4y2Ba,和班级的顺序GydF4y2BayGydF4y2Ba.GydF4y2Ba
加载GydF4y2Ba渔民GydF4y2Bax = meas;Y =分类(物种);classOrder =唯一(y);GydF4y2Ba
使用支持向量机二分类器训练ECOC模型。使用SVM模板标准化预测器,并指定类的顺序。GydF4y2Ba
t = templateSVM (GydF4y2Ba“标准化”GydF4y2Ba,真的);mdl = fitcecoc(x,y,GydF4y2Ba'学习者'GydF4y2BatGydF4y2Ba“类名”GydF4y2Ba, classOrder);GydF4y2Ba
T.GydF4y2Ba是一个支持向量机模板对象。在培训期间,软件使用默认值的空属性GydF4y2BaT.GydF4y2Ba.GydF4y2BaMDL.GydF4y2Ba是一个GydF4y2BaClassifiedecoc.GydF4y2Ba模型。GydF4y2Ba
预测训练数据的标签。打印真实标签和预测标签的随机子集。GydF4y2Ba
Labels = ResubPredict(MDL);RNG(1);GydF4y2Ba%的再现性GydF4y2Ban = numel(y);GydF4y2Ba%样本大小GydF4y2Baidx = randsample (n, 10);表(Y(IDX),标签(IDX),GydF4y2Ba“VariableNames”GydF4y2Ba, {GydF4y2Ba'truelabels'GydF4y2Ba那GydF4y2Ba'predightlabels'GydF4y2Ba})GydF4y2Ba
ans =GydF4y2Ba10×2表GydF4y2Ba真实标签预测标签__________ _______________ setosa setosa versicolor versicolor virginica setosa setosa setosa versicolor versicolor versicolor versicolor setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosa setosaGydF4y2Ba
MDL.GydF4y2Ba正确地标记了指数的观察GydF4y2BaidxGydF4y2Ba.GydF4y2Ba
用自定义二元损失函数预测ECOC模型的再替换标签GydF4y2Ba
载入费雪的虹膜数据集。指定预测器数据GydF4y2BaXGydF4y2Ba,响应数据GydF4y2BayGydF4y2Ba,和班级的顺序GydF4y2BayGydF4y2Ba.GydF4y2Ba
加载GydF4y2Ba渔民GydF4y2Bax = meas;Y =分类(物种);classOrder =唯一(y);GydF4y2Ba%班级订单GydF4y2Ba
使用支持向量机二分类器训练ECOC模型。使用SVM模板标准化预测器,并指定类的顺序。GydF4y2Ba
t = templateSVM (GydF4y2Ba“标准化”GydF4y2Ba,真的);mdl = fitcecoc(x,y,GydF4y2Ba'学习者'GydF4y2BatGydF4y2Ba“类名”GydF4y2Ba, classOrder);GydF4y2Ba
T.GydF4y2Ba是一个支持向量机模板对象。在培训期间,软件使用默认值的空属性GydF4y2BaT.GydF4y2Ba.GydF4y2BaMDL.GydF4y2Ba是一个GydF4y2BaClassifiedecoc.GydF4y2Ba模型。GydF4y2Ba
支持向量机的分数被标记为从观测到决策边界的距离。因此,域是GydF4y2Ba .创建一个自定义二进制损耗函数,执行以下操作:GydF4y2Ba
绘制编码设计矩阵(GydF4y2BamGydF4y2Ba)和积极级别的分类分数(GydF4y2BaS.GydF4y2Ba)来计算每次观察的二进制损失。GydF4y2Ba
使用线性损耗。GydF4y2Ba
使用中位数汇总二进制学习者丢失。GydF4y2Ba
您可以为二进制损耗函数创建一个单独的函数,然后将其保存在MATLAB®路径上。或者,您可以指定一个匿名二进制丢失函数。在本例中,创建一个函数句柄(GydF4y2BacustomBLGydF4y2Ba)的匿名二进制损失函数。GydF4y2Ba
customBL = @(M,s)nanmedian(1 - bsxfun(@times,M,s),2)/2;GydF4y2Ba
预测训练数据的标签并估计每个类的中位数二进制损失。为随机的10个观察结果打印每个类的负二进制损失的中位数。GydF4y2Ba
[标签,NegLoss] = resubPredict (MdlGydF4y2Ba“BinaryLoss”GydF4y2Ba,海关);RNG(1);GydF4y2Ba%的再现性GydF4y2Ban = numel(y);GydF4y2Ba%样本大小GydF4y2Baidx = randsample (n, 10);ClassOrder.GydF4y2Ba
ClassOrder =.GydF4y2Ba3 x1分类GydF4y2Basetosa杂色的virginicaGydF4y2Ba
表(Y (idx)、标签(idx) NegLoss (idx:)GydF4y2Ba“VariableNames”GydF4y2Ba那GydF4y2Ba...GydF4y2Ba{GydF4y2Ba“TrueLabel”GydF4y2Ba那GydF4y2Ba“PredictedLabel”GydF4y2Ba那GydF4y2Ba“NegLoss”GydF4y2Ba})GydF4y2Ba
ans =GydF4y2Ba10×3表GydF4y2BaTrueLabel PredictedLabel NegLoss ________________________ _______________________________ setosa versicolor 0.12379 1.9569 -3.5807 versicolor -1.0172 0.62935 -1.1122 virginica -1.9087 0.621744 0.62617 setosa versicolor 0.4386 2.2441 -4.1827 versicolor versicolor 0.26672 2.2003 -3.967Versicolor -1.1237 0.9917 -1.0754 Versicolor -1.2714 0.51834 -0.74695 setosa Versicolor 0.35211 2.0677 -3.9198 setosa Versicolor 0.23357 2.1885 -3.9221GydF4y2Ba
列的顺序对应于的元素GydF4y2BaClassOrder.GydF4y2Ba.软件根据最大负损失预测标签。结果表明,线性损失的中位数可能不如其他损失的中位数。GydF4y2Ba
使用ECOC分类器估计后验概率GydF4y2Ba
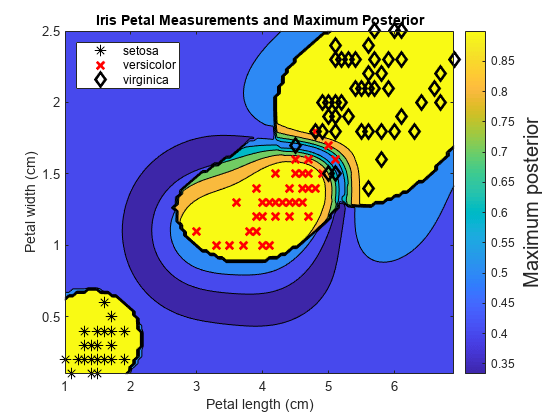
使用SVM二进制学习者培训ECOC分类器。首先预测训练样本标签和类后验概率。然后在网格中预测每个点处的最大类后概率。可视化结果。GydF4y2Ba
载入费雪的虹膜数据集。指定花瓣尺寸作为预测器,物种名称作为响应。GydF4y2Ba
加载GydF4y2Ba渔民GydF4y2BaX = MEAS(:,3:4);y =物种;RNG(1);GydF4y2Ba%的再现性GydF4y2Ba
创建一个支持向量机模板。标准化预测器,并指定高斯核。GydF4y2Ba
t = templateSVM (GydF4y2Ba“标准化”GydF4y2Ba,真的,GydF4y2Ba'骨箱'GydF4y2Ba那GydF4y2Ba“高斯”GydF4y2Ba);GydF4y2Ba
T.GydF4y2Ba是一个支持向量机模板。它的大部分属性都是空的。当软件训练ECOC分类器时,它将适用的属性设置为它们的默认值。GydF4y2Ba
使用SVM模板列车ecoc分类器。将分类分数转换为课程后概率(由此返回GydF4y2Ba预测GydF4y2Ba或GydF4y2Ba重新预订GydF4y2Ba) 使用GydF4y2Ba'fitposterior'GydF4y2Ba名称-值对的论点。属性指定类的顺序GydF4y2Ba“类名”GydF4y2Ba名称-值对的论点。方法在训练期间显示诊断消息GydF4y2Ba“详细”GydF4y2Ba名称-值对的论点。GydF4y2Ba
mdl = fitcecoc(x,y,GydF4y2Ba'学习者'GydF4y2BatGydF4y2Ba'fitposterior'GydF4y2Ba,真的,GydF4y2Ba...GydF4y2Ba“类名”GydF4y2Ba, {GydF4y2Ba“setosa”GydF4y2Ba那GydF4y2Ba“多色的”GydF4y2Ba那GydF4y2Ba“virginica”GydF4y2Ba},GydF4y2Ba...GydF4y2Ba“详细”GydF4y2Ba,2);GydF4y2Ba
训练二元学习器1 (SVM) 3与50负和50正的观察。负类指数:2正类指数:1拟合学习者1 (SVM)的后验概率。训练二元学习器2 (SVM),其中3个有50个负的和50个正的观察。负类指数:3正类指数:1拟合学习者2 (SVM)的后验概率。训练3个二元学习者(SVM),其中有50个负的和50个正的观察值。负类指数:3正类指数:2拟合后验概率学习者3 (SVM)。GydF4y2Ba
MDL.GydF4y2Ba是一个GydF4y2BaClassifiedecoc.GydF4y2Ba模型。同样的SVM模板适用于每个二元学习器,但您可以通过传递模板的单元向量来调整每个二元学习器的选项。GydF4y2Ba
预测训练样本标签和类别后验概率。在计算标签和类的后验概率时使用GydF4y2Ba“详细”GydF4y2Ba名称-值对的论点。GydF4y2Ba
[标签,~,~,后]= resubPredict (Mdl,GydF4y2Ba“详细”GydF4y2Ba,1);GydF4y2Ba
已经计算了所有学习者的预测。已经计算了所有观察的损失。计算后部概率......GydF4y2Ba
mdl.binaryloss.GydF4y2Ba
ans =“二次”GydF4y2Ba
该软件对类的类分配观察,从而产生最小的平均二进制损失。因为所有二进制学习者都是计算后验概率,所以二进制损失函数是GydF4y2Ba二次GydF4y2Ba.GydF4y2Ba
显示随机的结果。GydF4y2Ba
idx = randsample(大小(X, 1), 10日1);mdl.classnames.GydF4y2Ba
ans =.GydF4y2Ba3x1细胞GydF4y2Ba{'setosa'} {'versicolor'} {'virginica'}GydF4y2Ba
表(Y(IDX),标签(IDX),后退(IDX,:),GydF4y2Ba...GydF4y2Ba“VariableNames”GydF4y2Ba, {GydF4y2Ba“TrueLabel”GydF4y2Ba那GydF4y2Ba'predlabel'GydF4y2Ba那GydF4y2Ba“后”GydF4y2Ba})GydF4y2Ba
ans =GydF4y2Ba10×3表GydF4y2BaTrueLabel PredLabel后 ______________ ______________ ______________________________________ {' virginica’}{‘virginica} 0.0039322 0.003987 0.99208{‘virginica}{‘virginica} 0.017067 0.018263 0.96467{‘virginica}{‘virginica} 0.014948 0.015856 0.9692{“癣”}{“癣”}2.2197 e-14 0.87318 - 0.12682{‘setosa} {' setosa '}0.999 0.029985 {'versicolor'} {'versicolor'}} 0.0085642 0.98259 0.0088487 {'setosa'} {'setosa'} 0.999 0.00024992 0.0088487 {'setosa'} {'setosa'} 0.999 0.00024913 0.00074717GydF4y2Ba
的列GydF4y2Ba后面GydF4y2Ba对应于的类序GydF4y2Bamdl.classnames.GydF4y2Ba.GydF4y2Ba
在观察到的预测器空间中定义一个值的网格。预测网格中每个实例的后验概率。GydF4y2Ba
xmax = max(x);xmin = min(x);x1pts = linspace(xmin(1),xmax(1));x2pts = linspace(xmin(2),xmax(2));[x1grid,x2grid] = meshgrid(x1pts,x2pts);[〜,〜,〜,posteriorregion] =预测(mdl,[x1grid(:),x2grid(:)]);GydF4y2Ba
对于网格上的每个坐标,绘制所有类之间的最大类后验概率。GydF4y2Ba
contourf (x1Grid x2Grid,GydF4y2Ba...GydF4y2Ba重塑(max (PosteriorRegion[], 2),大小(x1Grid, 1),大小(x1Grid, 2)));h = colorbar;h.YLabel.String =GydF4y2Ba最大后验的GydF4y2Ba;h.YLabel.FontSize = 15;持有GydF4y2Ba在GydF4y2Bagh = g箭偶(x(:,1),x(:,2),y,GydF4y2Ba“krk”GydF4y2Ba那GydF4y2Ba'* xd'GydF4y2Ba8);gh(2)。L.一世NeWidth = 2; gh(3).LineWidth = 2; title('虹膜瓣测量和最大后后'GydF4y2Ba)包含(GydF4y2Ba“花瓣长度(厘米)”GydF4y2Ba) ylabel (GydF4y2Ba“花瓣宽度(cm)”GydF4y2Ba)轴GydF4y2Ba紧GydF4y2Ba传奇(gh,GydF4y2Ba“位置”GydF4y2Ba那GydF4y2Ba“西北”GydF4y2Ba)举行GydF4y2Ba离开GydF4y2Ba
用并行计算估计后验概率GydF4y2Ba
训练多类ECOC模型,并用并行计算估计后验概率。GydF4y2Ba
加载GydF4y2Ba心律失常GydF4y2Ba数据集。检查响应数据GydF4y2BayGydF4y2Ba,并确定类的数量。GydF4y2Ba
加载GydF4y2Ba心律失常GydF4y2Bay =分类(y);表格(y)GydF4y2Ba
值计数百分比1 245 54.20% 2 44 9.73% 3 15 3.32% 4 15 3.32% 5 13 2.88% 6 25 5.53% 73 0.66% 8 2 0.44% 99 1.99% 10 50 11.06% 14 4 0.88% 15 5 1.11% 16 22 4.87%GydF4y2Ba
k = numel(唯一(y));GydF4y2Ba
在数据中没有表示几个类,许多其他类具有低相对频率。GydF4y2Ba
指定一个使用了GentleBoost方法的集成学习模板和50个弱分类树学习器。GydF4y2Ba
t = templateEnsemble (GydF4y2Ba'温船'GydF4y2Ba,50,GydF4y2Ba“树”GydF4y2Ba);GydF4y2Ba
T.GydF4y2Ba是一个模板对象。其大部分属性都是空的(GydF4y2Ba[]GydF4y2Ba).软件在训练过程中对所有空属性使用默认值。GydF4y2Ba
因为响应变量包含许多类,所以指定一个稀疏随机编码设计。GydF4y2Ba
RNG(1);GydF4y2Ba%的再现性GydF4y2Ba编码= designecoc(k,GydF4y2Ba“sparserandom”GydF4y2Ba);GydF4y2Ba
使用并行计算训练ECOC模型。指定拟合后验概率。GydF4y2Ba
池= parpool;GydF4y2Ba%调用工人GydF4y2Ba
使用“本地”配置文件启动并行池(Parpool)连接到并行池(工人数:6)。GydF4y2Ba
选择= statset (GydF4y2Ba'使用指平行'GydF4y2Ba,真的);mdl = fitcecoc(x,y,GydF4y2Ba'学习者'GydF4y2BatGydF4y2Ba“选项”GydF4y2Ba选项,GydF4y2Ba'编码'GydF4y2Ba、编码、GydF4y2Ba...GydF4y2Ba'fitposterior'GydF4y2Ba,真的);GydF4y2Ba
MDL.GydF4y2Ba是一个GydF4y2BaClassifiedecoc.GydF4y2Ba模型。您可以使用点表示法访问其属性。GydF4y2Ba
游泳池援引六名工人,尽管工人的数量可能因系统而异。GydF4y2Ba
估计后验概率,并在给定随机子集的训练数据下显示被分类为无心律失常(第1类)的后验概率。GydF4y2Ba
[〜,〜,〜,后退] = Resubpredict(MDL);n = numel(y);idx = randsample(n,10,1);表(IDX,Y(IDX),后退(IDX,1),GydF4y2Ba...GydF4y2Ba“VariableNames”GydF4y2Ba, {GydF4y2Ba“ObservationIndex”GydF4y2Ba那GydF4y2Ba“TrueLabel”GydF4y2Ba那GydF4y2Ba'posteriornoarrythmia'GydF4y2Ba})GydF4y2Ba
ans =GydF4y2Ba10×3表GydF4y2BaObservationIndex TrueLabel PosteriorNoArrythmia ________________ _________ ____________________ 79 1 0.93436 248 1 0.95574 398 10 0.032378 207 1 0.97965 340 1 0.93656 206 1 0.97795 345 10 0.015642 296 2 0.13433 391 1 0.9648 406 1 0.94861GydF4y2Ba
输入参数GydF4y2Ba
输出参数GydF4y2Ba
更多关于GydF4y2Ba
算法GydF4y2Ba
参考GydF4y2Ba
[1] Allwein,E.,R. Schapire和Y.歌手。“减少二进制文件的多牌:保证金分类的统一方法。”GydF4y2Ba机床学习研究GydF4y2Ba.2000年第1卷,113-141页。GydF4y2Ba
[2] Dietterich T.和G. Bakiri。通过错误修正输出代码解决多类学习问题。GydF4y2Ba人工智能研究杂志GydF4y2Ba.第2卷,1995年,263-286页。GydF4y2Ba
[3] Escalera,S.,O. Pujol和P. Radeva。“在三元纠错输出代码中解码过程。”GydF4y2Ba图案分析和机器智能的IEEE交易GydF4y2Ba.2010年第32卷第7期120-134页。GydF4y2Ba
Pujol, S. Escalera, S. O. Pujol, P. Radeva。用于纠错输出码稀疏设计的三元码的可分性。GydF4y2Ba模式识别GydF4y2Ba.2009年第30卷第3期285-297页。GydF4y2Ba
Hastie, T.和R. Tibshirani。“两两耦合分类”。GydF4y2Ba统计数据GydF4y2Ba.卷。26,第298页,第451-471页。GydF4y2Ba
吴廷锋,林春杰,翁仁。“基于成对耦合的多类别分类的概率估计”。GydF4y2Ba机床学习研究GydF4y2Ba.第5卷,2004年,975-1005页。GydF4y2Ba
[7] Zadrozny,B。“通过耦合概率估计减少多标数到二进制。”GydF4y2BaNIPS 2001:神经信息处理系统的进步程序14GydF4y2Ba, 2001,第1041-1048页。GydF4y2Ba
扩展功能GydF4y2Ba
也可以看看GydF4y2Ba
Classifiedecoc.GydF4y2Ba|GydF4y2BafitcecocGydF4y2Ba|GydF4y2Ba预测GydF4y2Ba|GydF4y2Baresubloss.GydF4y2Ba|GydF4y2BastatsetGydF4y2Ba|GydF4y2BaQuadprog.GydF4y2Ba(优化工具箱)GydF4y2Ba
选择一个网站GydF4y2Ba
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:GydF4y2Ba.GydF4y2Ba
选择GydF4y2Ba网站GydF4y2Ba您还可以从以下列表中选择一个网站:GydF4y2Ba
美洲GydF4y2Ba
- América拉丁GydF4y2Ba(西班牙语)GydF4y2Ba
- 加拿大GydF4y2Ba(英语)GydF4y2Ba
- 美国GydF4y2Ba(英语)GydF4y2Ba
欧洲GydF4y2Ba
- 比利时GydF4y2Ba(英语)GydF4y2Ba
- 丹麦GydF4y2Ba(英语)GydF4y2Ba
- 德国GydF4y2Ba(德意志)GydF4y2Ba
- España.GydF4y2Ba(西班牙语)GydF4y2Ba
- 芬兰GydF4y2Ba(英语)GydF4y2Ba
- 法国GydF4y2Ba(Français)GydF4y2Ba
- 爱尔兰GydF4y2Ba(英语)GydF4y2Ba
- 意大利GydF4y2Ba(意大利语)GydF4y2Ba
- 卢森堡GydF4y2Ba(英语)GydF4y2Ba
- 荷兰GydF4y2Ba(英语)GydF4y2Ba
- 挪威GydF4y2Ba(英语)GydF4y2Ba
- Österreich.GydF4y2Ba(德意志)GydF4y2Ba
- 葡萄牙GydF4y2Ba(英语)GydF4y2Ba
- 瑞典GydF4y2Ba(英语)GydF4y2Ba
- 瑞士GydF4y2Ba
- 联合王国GydF4y2Ba(英语)GydF4y2Ba
亚太地区GydF4y2Ba
- 澳大利亚GydF4y2Ba(英语)GydF4y2Ba
- 印度GydF4y2Ba(英语)GydF4y2Ba
- 新西兰GydF4y2Ba(英语)GydF4y2Ba
- 中国GydF4y2Ba
- 日本GydF4y2Ba(日本語)GydF4y2Ba
- 한국GydF4y2Ba(한국어)GydF4y2Ba
