预测gydF4y2Ba
使用多款纠错输出代码(ECOC)模型进行分类观察gydF4y2Ba
语法gydF4y2Ba
描述gydF4y2Ba
标签gydF4y2Ba=预测(gydF4y2BaMdlgydF4y2Ba,gydF4y2BaXgydF4y2Ba)gydF4y2Ba标签gydF4y2Ba)用于表或矩阵中的预测数据gydF4y2BaXgydF4y2Ba,基于训练的多类纠错输出码(ECOC)模型gydF4y2BaMdlgydF4y2Ba.经过训练的ECOC模型可以是完整的,也可以是紧凑的。gydF4y2Ba
标签gydF4y2Ba=预测(gydF4y2BaMdlgydF4y2Ba,gydF4y2BaXgydF4y2Ba,gydF4y2Ba名称,值gydF4y2Ba)gydF4y2Ba
[gydF4y2Ba使用前面语法中的任何输入参数组合,并额外返回:gydF4y2Ba标签gydF4y2Ba,gydF4y2BaNegLossgydF4y2Ba,gydF4y2BaPBScoregydF4y2Ba] =预测(gydF4y2Ba___gydF4y2Ba)gydF4y2Ba
一系列否定的平均水平gydF4y2Ba二进制损失gydF4y2Ba(gydF4y2Ba
NegLossgydF4y2Ba).对于每一个gydF4y2BaXgydF4y2Ba,gydF4y2Ba预测gydF4y2Ba指定产生最大负平均二进制损失(或,等价地,最小平均二进制损失)的类的标签。gydF4y2Ba一组积极等级的分数(gydF4y2Ba
PBScoregydF4y2Ba)对于每个二进制学习者分类的观察。gydF4y2Ba
[gydF4y2Ba另外,返回观测值的后验类别概率估计值(gydF4y2Ba标签gydF4y2Ba,gydF4y2BaNegLossgydF4y2Ba,gydF4y2BaPBScoregydF4y2Ba,gydF4y2Ba后gydF4y2Ba] =预测(gydF4y2Ba___gydF4y2Ba)gydF4y2Ba后gydF4y2Ba).gydF4y2Ba
要获得后验类别概率,必须设置gydF4y2Ba'fitposterior',真实gydF4y2Ba在培训ECOC模式时使用gydF4y2Bafitcecoc.gydF4y2Ba.除此以外,gydF4y2Ba预测gydF4y2Ba抛出错误。gydF4y2Ba
例子gydF4y2Ba
用ECOC模型预测训练数据的测试样本标签gydF4y2Ba
载入费雪的虹膜数据集。指定预测器数据gydF4y2BaXgydF4y2Ba,响应数据gydF4y2BaYgydF4y2Ba,和班级的顺序gydF4y2BaYgydF4y2Ba.gydF4y2Ba
负载gydF4y2BafisheririsgydF4y2BaX =量;Y =分类(物种);classOrder =独特(Y);rng (1);gydF4y2Ba%的再现性gydF4y2Ba
使用支持向量机二分类器训练ECOC模型。指定30%的拒绝样本,使用SVM模板标准化预测器,并指定类顺序。gydF4y2Ba
t = templatesvm(gydF4y2Ba'标准化'gydF4y2Ba,真正的);PMdl = fitcecoc (X, Y,gydF4y2Ba“坚持”gydF4y2Ba,0.30,gydF4y2Ba“学习者”gydF4y2Ba,t,gydF4y2Ba'classnames'gydF4y2Ba,classorder);mdl = pmdl.tromed {1};gydF4y2Ba%提取训练过的紧凑分类器gydF4y2Ba
PMDL.gydF4y2Ba是一个gydF4y2BaClassificationedecoc.gydF4y2Ba模型。它有物业gydF4y2Ba训练有素的gydF4y2Ba,一个1 × 1单元数组,其中包含gydF4y2BaCompactClassificationECOCgydF4y2Ba使用培训集培训的软件的模型。gydF4y2Ba
预测样品标签。打印真实标签和预测标签的随机子集。gydF4y2Ba
testInds =测试(PMdl.Partition);gydF4y2Ba%提取测试指标gydF4y2BaXTest = X (testInds:);欧美= Y (testInds:);标签=预测(Mdl XTest);idx = randsample (sum (testInds), 10);表(欧美(idx),标签(idx),gydF4y2Ba......gydF4y2Ba'variablenames'gydF4y2Ba, {gydF4y2Ba'truelabels'gydF4y2Ba,gydF4y2Ba“PredictedLabels”gydF4y2Ba})gydF4y2Ba
ans =.gydF4y2Ba10×2表gydF4y2Ba真实标签预测标签__________ _______________ setosa setosa versicolor vericolor vericolor setosa setosa setosa setosa setosagydF4y2Ba
MdlgydF4y2Ba正确地标记所有与指数的测试样本观测之外gydF4y2BaidxgydF4y2Ba.gydF4y2Ba
用自定义二元损耗函数预测ECOC模型的试样标签gydF4y2Ba
载入费雪的虹膜数据集。指定预测器数据gydF4y2BaXgydF4y2Ba,响应数据gydF4y2BaYgydF4y2Ba,和班级的顺序gydF4y2BaYgydF4y2Ba.gydF4y2Ba
负载gydF4y2BafisheririsgydF4y2BaX =量;Y =分类(物种);classOrder =独特(Y);gydF4y2Ba%课堂秩序gydF4y2Barng (1);gydF4y2Ba%的再现性gydF4y2Ba
使用支持向量机二分类器训练ECOC模型,并指定30%的坚持样本。使用SVM模板标准化预测器,并指定类的顺序。gydF4y2Ba
t = templatesvm(gydF4y2Ba'标准化'gydF4y2Ba,真正的);PMdl = fitcecoc (X, Y,gydF4y2Ba“坚持”gydF4y2Ba,0.30,gydF4y2Ba“学习者”gydF4y2Ba,t,gydF4y2Ba'classnames'gydF4y2Ba,classorder);mdl = pmdl.tromed {1};gydF4y2Ba%提取训练过的紧凑分类器gydF4y2Ba
PMDL.gydF4y2Ba是一个gydF4y2BaClassificationedecoc.gydF4y2Ba模型。它有物业gydF4y2Ba训练有素的gydF4y2Ba,一个1 × 1单元数组,其中包含gydF4y2BaCompactClassificationECOCgydF4y2Ba使用培训集培训的软件的模型。gydF4y2Ba
支持向量机的分数被标记为从观测到决策边界的距离。因此,gydF4y2Ba 是域名。创建一个定制二进制丢失函数,执行以下操作:gydF4y2Ba
绘制编码设计矩阵(gydF4y2Ba米gydF4y2Ba)和正向分类得分(gydF4y2Ba年代gydF4y2Ba)来计算每次观察的二进制损失。gydF4y2Ba
使用线性的损失。gydF4y2Ba
使用中值合计二进制学习器损失。gydF4y2Ba
您可以为二进制损耗函数创建一个单独的函数,然后将其保存在MATLAB®路径上。或者,您可以指定一个匿名二进制丢失函数。在本例中,创建一个函数句柄(gydF4y2BaCustomBl.gydF4y2Ba)匿名二进制损失函数。gydF4y2Ba
customBL = @(M,s) median(1 - bsxfun(@times,M,s),2,gydF4y2Ba'omitnan'gydF4y2Ba/ 2;gydF4y2Ba
预测测试样本标签并估计每个类的中位数二进制损失。为随机的10个测试样本观察结果打印每个类的负二进制损失的中位数。gydF4y2Ba
testInds =测试(PMdl.Partition);gydF4y2Ba%提取测试指标gydF4y2BaXTest = X (testInds:);欧美= Y (testInds:);[标签,dropsа] =预测(MDL,XTEST,gydF4y2Ba'二元乐'gydF4y2Ba,海关);idx = randsample (sum (testInds), 10);ClassOrder.gydF4y2Ba
classOrder =gydF4y2Ba3 x1分类gydF4y2BaSetosa Versicolor Virginica.gydF4y2Ba
表(ytest(idx),标签(idx),dropsа(idx,:),gydF4y2Ba'variablenames'gydF4y2Ba,gydF4y2Ba......gydF4y2Ba{gydF4y2Ba'truilabel'gydF4y2Ba,gydF4y2Ba'predightlabel'gydF4y2Ba,gydF4y2Ba'opoloss'gydF4y2Ba})gydF4y2Ba
ans =.gydF4y2Ba10×3表gydF4y2BaTrueLabel PredictedLabel NegLoss __________ ______________ __________________________________ setosa云芝0.18569 1.989 -3.6747云芝弗吉尼亚-1.3316 -0.12346 -0.044933 setosa云芝0.13897 1.9274 -3.5664弗吉尼亚弗吉尼亚-1.5133 -0.38288 0.39616花斑癣菌-0.87209 0.74813 -1.376 setosa云芝0.4838 1.9987 -3.9825弗吉尼亚弗吉尼亚-1.9363-0.67586 1.1122 Virginica Virginica -1.5789 -0.8337 0.91265 Setosa Versicolor 0.50999 2.1223 -4.1323 Setosa Versicolor 0.36117 2.0608 -3.922gydF4y2Ba
列的顺序对应于的元素gydF4y2BaClassOrder.gydF4y2Ba.该软件根据最大否定损耗预测标签。结果表明,线性损耗的中位数可能无法表现和其他损失。gydF4y2Ba
使用Ecoc分类器估计后验概率gydF4y2Ba
使用支持向量机二进制学习器训练ECOC分类器。首先预测训练样本标签和类的后验概率。然后预测网格中每个点的最大类别后验概率。可视化结果。gydF4y2Ba
载入费雪的虹膜数据集。将花瓣尺寸指定为预测器和物种名称作为响应。gydF4y2Ba
负载gydF4y2BafisheririsgydF4y2BaX =量(:,3:4);Y =物种;rng (1);gydF4y2Ba%的再现性gydF4y2Ba
创建SVM模板。标准化预测器,并指定高斯内核。gydF4y2Ba
t = templatesvm(gydF4y2Ba'标准化'gydF4y2Ba,真的,gydF4y2Ba'骨箱'gydF4y2Ba,gydF4y2Ba“高斯”gydF4y2Ba);gydF4y2Ba
tgydF4y2Ba是一个支持向量机模板。它的大部分属性都是空的。当软件训练ECOC分类器时,它将适用的属性设置为它们的默认值。gydF4y2Ba
使用支持向量机模板训练ECOC分类器。将分类分数转换为分类后验概率(由gydF4y2Ba预测gydF4y2Ba或gydF4y2BaresubPredictgydF4y2Ba)使用gydF4y2Ba“FitPosterior”gydF4y2Ba名称-值对的论点。属性指定类的顺序gydF4y2Ba'classnames'gydF4y2Ba名称-值对的论点。方法在训练期间显示诊断消息gydF4y2Ba“详细”gydF4y2Ba名称-值对的论点。gydF4y2Ba
Mdl = fitcecoc (X, Y,gydF4y2Ba“学习者”gydF4y2Ba,t,gydF4y2Ba“FitPosterior”gydF4y2Ba,真的,gydF4y2Ba......gydF4y2Ba'classnames'gydF4y2Ba, {gydF4y2Ba'setosa'gydF4y2Ba,gydF4y2Ba'versicolor'gydF4y2Ba,gydF4y2Ba“virginica”gydF4y2Ba},gydF4y2Ba......gydF4y2Ba“详细”gydF4y2Ba2);gydF4y2Ba
培训二进制学习者1(SVM),其中3个,50个负和50个阳性观察。负类指数:2个正类指数:1用于学习者1(SVM)的后验概率。培训二元学习者2(SVM),其中3个,50个负和50个阳性观察。负类指数:3个正类指数:1拟合学习者2(SVM)的后验概率。培训二进制学习者3(SVM),其中50个负和50个阳性观察。负类指数:3个正类指数:2学习者3(SVM)的拟合后验概率。gydF4y2Ba
MdlgydF4y2Ba是一个gydF4y2BaClassificationECOCgydF4y2Ba模型。相同的SVM模板适用于每个二进制学习者,但您可以通过传递在模板的单元格向量中调整每个二进制学习者的选项。gydF4y2Ba
预测训练样本标签和类别后验概率。在计算标签和类的后验概率时使用gydF4y2Ba“详细”gydF4y2Ba名称-值对的论点。gydF4y2Ba
[标签,〜,〜,后退] = ResubPredict(MDL,gydF4y2Ba“详细”gydF4y2Ba1);gydF4y2Ba
对所有学习者的预测都进行了计算。计算了所有观测的损失。计算后验概率…gydF4y2Ba
mdl.binaryloss.gydF4y2Ba
ans ='二次'gydF4y2Ba
该软件将观察结果分配给产生最小平均二进制损失的班级。由于所有二进制学习器都在计算后验概率,因此二进制损失函数为gydF4y2Ba二次gydF4y2Ba.gydF4y2Ba
显示一组随机的结果。gydF4y2Ba
idx = randsample(大小(X, 1), 10日1);mdl.classnames.gydF4y2Ba
ans =gydF4y2Ba3 x1细胞gydF4y2Ba{'setosa'} {'versicolor'} {'virginica'}gydF4y2Ba
表(Y (idx)、标签(idx)、后(idx:)gydF4y2Ba......gydF4y2Ba'variablenames'gydF4y2Ba, {gydF4y2Ba'truilabel'gydF4y2Ba,gydF4y2Ba“PredLabel”gydF4y2Ba,gydF4y2Ba'后后'gydF4y2Ba})gydF4y2Ba
ans =.gydF4y2Ba10×3表gydF4y2BaTrueLabel PredLabel后路______________ ______________ ______________________________________ { '锦葵'} { '锦葵'} 0.0039322 0.003987 0.99208 { '锦葵'} { '锦葵'} 0.017067 0.018263 0.96467 { '锦葵'} { '锦葵'} 0.014948 0.015856 0.9692 { '云芝'}{'versicolor'} 2.2197e-14 0.87318 0.87318 0.12682 {'setosa'} {'setosa'} {'setosa'} {'setosa'} 0.999 0.0.00025092 0.00074638 {'Versicolor'} {'Versicolor'} {'Versicolor'} {Versicolor'} {versicolor'}2.2194E-14 0.97001 0.029985 {'setosa'} {'setosa'} 0.999 0.00024991 0.0007474 {'versicolor'} {'versicolor'} 0.0085642 0.9859 0.008877 {setosa'} 0.98259 0.0088487gydF4y2Ba
列的列gydF4y2Ba后gydF4y2Ba对应于的类序gydF4y2Bamdl.classnames.gydF4y2Ba.gydF4y2Ba
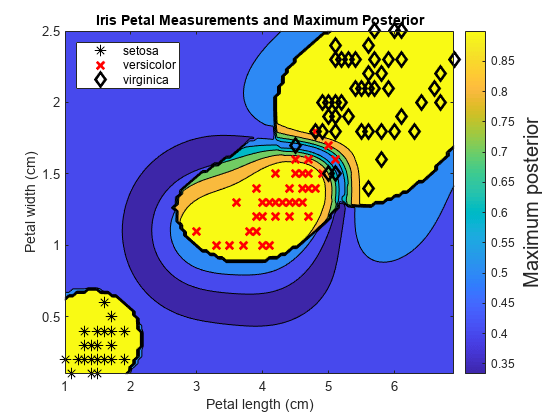
在观测的预测器空间中定义一个网格值。预测网格中每个实例的后验概率。gydF4y2Ba
xMax = max (X);xMin = min (X);x1Pts = linspace (xMin (1) xMax (1));xMax x2Pts = linspace (xMin (2), (2));[x1Grid, x2Grid] = meshgrid (x1Pts x2Pts);[~, ~, ~, PosteriorRegion] =预测(Mdl, [x1Grid (:), x2Grid (:)));gydF4y2Ba
对于网格上的每个坐标,请在所有类别中绘制最大类后概率。gydF4y2Ba
contourf(x1grid,x2grid,gydF4y2Ba......gydF4y2Ba重塑(max (PosteriorRegion[], 2),大小(x1Grid, 1),大小(x1Grid, 2)));h = colorbar;h.YLabel.String =gydF4y2Ba'最大后后'gydF4y2Ba;h.ylabel.fontsize = 15;抓住gydF4y2Ba在gydF4y2Bagh = g箭偶(x(:,1),x(:,2),y,gydF4y2Ba'krk'gydF4y2Ba,gydF4y2Ba‘* xd‘gydF4y2Ba,8);GH(2).LineWidth = 2;GH(3).LineWidth = 2;标题(gydF4y2Ba“虹膜瓣尺寸和最大后部”gydF4y2Ba)包含(gydF4y2Ba'花瓣长度(cm)'gydF4y2Ba) ylabel (gydF4y2Ba'花瓣宽度(cm)'gydF4y2Ba)轴gydF4y2Ba紧的gydF4y2Ba传奇(GH,gydF4y2Ba“位置”gydF4y2Ba,gydF4y2Ba'西北'gydF4y2Ba) 抓住gydF4y2Ba从gydF4y2Ba
使用并行计算估计检验样本后验概率gydF4y2Ba
训练多类ECOC模型,并用并行计算估计后验概率。gydF4y2Ba
加载gydF4y2Ba心律失常gydF4y2Ba数据集。检查响应数据gydF4y2BaYgydF4y2Ba,并确定类的数量。gydF4y2Ba
负载gydF4y2Ba心律失常gydF4y2BaY =分类(Y);汇总(Y)gydF4y2Ba
值计数百分比1 245 54.20%2 44 9.73%3 15 3.32%4 15 3.32%513 2.88%6 25 5.53%7 3 0.66%8 2 0.44%9 9 1.90%10 50 11.06%14 0.88%11.06%14 0.88%15 5 1.11%16 22 4.87%gydF4y2Ba
K =元素个数(独特(Y));gydF4y2Ba
有几个类没有显示在数据中,而许多其他类的相对频率较低。gydF4y2Ba
指定一个使用了GentleBoost方法的集成学习模板和50个弱分类树学习器。gydF4y2Ba
t = templateEnsemble (gydF4y2Ba“GentleBoost”gydF4y2Ba, 50岁,gydF4y2Ba“树”gydF4y2Ba);gydF4y2Ba
tgydF4y2Ba是模板对象。它的大部分属性是空的(gydF4y2Ba[]gydF4y2Ba).该软件在培训期间使用所有空属性的默认值。gydF4y2Ba
因为响应变量包含许多类,所以指定一个稀疏随机编码设计。gydF4y2Ba
rng (1);gydF4y2Ba%的再现性gydF4y2Ba编码= designecoc (K,gydF4y2Ba'sparserandom'gydF4y2Ba);gydF4y2Ba
使用并行计算训练ECOC模型。指定15%的坚持样本,并拟合后验概率。gydF4y2Ba
池= parpool;gydF4y2Ba%调用工人gydF4y2Ba
使用“local”配置文件启动并行池(parpool)…连接到并行池(工作人员数量:6)。gydF4y2Ba
选择= statset (gydF4y2Ba“UseParallel”gydF4y2Ba,真正的);PMdl = fitcecoc (X, Y,gydF4y2Ba'学习者'gydF4y2Ba,t,gydF4y2Ba“选项”gydF4y2Ba选项,gydF4y2Ba“编码”gydF4y2Ba、编码、gydF4y2Ba......gydF4y2Ba“FitPosterior”gydF4y2Ba,真的,gydF4y2Ba“坚持”gydF4y2Ba,0.15);mdl = pmdl.tromed {1};gydF4y2Ba%提取训练过的紧凑分类器gydF4y2Ba
PMDL.gydF4y2Ba是一个gydF4y2BaClassificationedecoc.gydF4y2Ba模型。它有物业gydF4y2Ba训练有素的gydF4y2Ba,一个1 × 1单元数组,其中包含gydF4y2BaCompactClassificationECOCgydF4y2Ba使用培训集培训的软件的模型。gydF4y2Ba
池调用6个工作人员,但是工作人员的数量可能因系统而异。gydF4y2Ba
估计后验概率,并显示被分类为没有心律失常(第1类)的后验概率,给出一组随机的测试样本观察数据。gydF4y2Ba
testInds =测试(PMdl.Partition);gydF4y2Ba%提取测试指标gydF4y2BaXTest = X (testInds:);欧美= Y (testInds:);[~, ~, ~,后]=预测(Mdl XTest,gydF4y2Ba“选项”gydF4y2Ba,选项);idx = randsample (sum (testInds), 10);表(IDX,YTEST(IDX),后退(IDX,1),gydF4y2Ba......gydF4y2Ba'variablenames'gydF4y2Ba, {gydF4y2Ba“TestSampleIndex”gydF4y2Ba,gydF4y2Ba'truilabel'gydF4y2Ba,gydF4y2Ba'posteriornoarrhalythmia'gydF4y2Ba})gydF4y2Ba
ans =.gydF4y2Ba10×3表gydF4y2BaTestSampleIndex TrueLabel posteriorno心律失常_______________ _________ _____________________ 11 6 0.60631 41 4 0.23674 512 0.13802 33 10 0.43831 12 1 0.94332 8 1 0.97278 37 1 0.62807 24 10 0.96876 56 16 0.29375 30 1 0.64512gydF4y2Ba
输入参数gydF4y2Ba
输出参数gydF4y2Ba
更多关于gydF4y2Ba
算法gydF4y2Ba
参考gydF4y2Ba
艾尔温,E.夏皮尔,Y.辛格。《将多类减少为二进制:一种统一的保证金分类方法》。gydF4y2Ba机器学习研究杂志gydF4y2Ba.2000年第1卷,113-141页。gydF4y2Ba
[2] Dietterich,T.和G. Bakiri。“通过纠错输出代码来解决多字母学习问题。”gydF4y2Ba人工智能研究杂志gydF4y2Ba.第2卷,1995年,263-286页。gydF4y2Ba
Pujol, S. Escalera, S. O. Pujol, P. Radeva。《论三元纠错输出码的译码过程》。gydF4y2Ba模式分析与机器智能学报gydF4y2Ba.卷。32,第7号,2010年第70页,第120-134页。gydF4y2Ba
[4] Escalera,S.,O. Pujol和P. Radeva。“用于纠错输出代码稀疏设计的三元代码的可分离。”gydF4y2Ba模式识别gydF4y2Ba.2009年第30卷第3期285-297页。gydF4y2Ba
[5] Hastie,T.和R. Tibshirani。“通过成对耦合进行分类。”gydF4y2Ba统计数据gydF4y2Ba.1998年第26卷第2期第451-471页。gydF4y2Ba
吴廷锋,林春杰,翁仁。“基于成对耦合的多类别分类的概率估计”。gydF4y2Ba机器学习研究杂志gydF4y2Ba.卷。5,2004,PP。975-1005。gydF4y2Ba
[7] zrozny,“通过耦合概率估计将多类分解为二进制”。gydF4y2BaNIPS 2001:神经信息处理系统的进步程序14gydF4y2Ba, 2001,第1041-1048页。gydF4y2Ba
扩展功能gydF4y2Ba
另请参阅gydF4y2Ba
ClassificationECOCgydF4y2Ba|gydF4y2BaCompactClassificationECOCgydF4y2Ba|gydF4y2Bafitcecoc.gydF4y2Ba|gydF4y2Ba损失gydF4y2Ba|gydF4y2BaresubPredictgydF4y2Ba|gydF4y2Ba实例化gydF4y2Ba|gydF4y2BaquadproggydF4y2Ba(优化工具箱)gydF4y2Ba
选择网站gydF4y2Ba
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:gydF4y2Ba.gydF4y2Ba
选择gydF4y2Ba网站gydF4y2Ba您还可以从以下列表中选择一个网站:gydF4y2Ba
美洲gydF4y2Ba
- América拉丁gydF4y2Ba(西班牙语)gydF4y2Ba
- 加拿大gydF4y2Ba(英语)gydF4y2Ba
- 美国gydF4y2Ba(英语)gydF4y2Ba
欧洲gydF4y2Ba
- 比利时gydF4y2Ba(英语)gydF4y2Ba
- 丹麦gydF4y2Ba(英语)gydF4y2Ba
- 德意志gydF4y2Ba(德语)gydF4y2Ba
- 西班牙gydF4y2Ba(西班牙语)gydF4y2Ba
- 芬兰gydF4y2Ba(英语)gydF4y2Ba
- 法国gydF4y2Ba(法语)gydF4y2Ba
- 爱尔兰gydF4y2Ba(英语)gydF4y2Ba
- 意大利gydF4y2Ba(意大利语)gydF4y2Ba
- 卢森堡gydF4y2Ba(英语)gydF4y2Ba
- 荷兰gydF4y2Ba(英语)gydF4y2Ba
- 挪威gydF4y2Ba(英语)gydF4y2Ba
- 奥地利gydF4y2Ba(德语)gydF4y2Ba
- 葡萄牙gydF4y2Ba(英语)gydF4y2Ba
- 瑞典gydF4y2Ba(英语)gydF4y2Ba
- 瑞士gydF4y2Ba
- 英国gydF4y2Ba(英语)gydF4y2Ba
亚太地区gydF4y2Ba
- 澳大利亚gydF4y2Ba(英语)gydF4y2Ba
- 印度gydF4y2Ba(英语)gydF4y2Ba
- 新西兰gydF4y2Ba(英语)gydF4y2Ba
- 中国gydF4y2Ba
- 日本gydF4y2Ba(日本语)gydF4y2Ba
- 한국gydF4y2Ba(한국어)gydF4y2Ba
