模板乐团
集成学习模板
描述
例子
创建集成学习模板
使用模板乐团指定集成学习模板。您必须指定集成方法、学习周期的数量和弱学习者的类型。对于本例,指定AdaBoostM1方法、100个学习者和分类树弱学习者。
t = templateEnsemble (“AdaBoostM1”, 100,“树”)
t =适合分类的模板AdaBoostM1。类型:'classification'方法:'AdaBoostM1' LearnerTemplates: 'Tree' NLearn: 100 LearnRate: []
模板对象的所有属性都为空,除了方法,类型,LearnerTemplates,NLearn.当接受训练时,软件将用它们各自的默认值填充空属性。例如,软件填充LearnRate财产与1.
t是用于集成学习器的计划,指定该计划时不会发生计算。你可以通过t来fitcecoc为ECOC多类学习指定集成二进制学习者。
创建ECOC多类学习的集成模板
创建用于中的集成模板fitcecoc.
加载心律失常数据集。
负载心律失常汇总(分类(Y));
价值计数百分比124554.20%2449.73%3153.32%4153.32%5132.88%6255.53%730.66%820.44%991.99%1050111.06%1440.88%1551.11%16224.87%
rng (1);%为了再现性
有些类在数据中的相对频率很小。
为AdaBoostM1分类树集合创建一个模板,并指定使用100个学习者,收缩值为0.1。默认情况下,增加树桩(即一个节点拥有一组叶子)。由于班级的上课频率很小,所以树木必须有足够多的叶子,以对少数班级敏感。指定最小叶节点观察数为3。
tTree=模板树(“MinLeafSize”, 20);t = templateEnsemble (“AdaBoostM1”,100,t树,“LearnRate”, 0.1);
模板对象的所有属性都为空,除了方法和类型,以及函数调用中名称-值对参数值的相应属性。当你通过t对于训练函数,软件用它们各自的默认值填充空属性。
指定t作为ECOC多类模型的二元学习者。使用默认的一对一编码设计进行培训。
Mdl = fitcecoc (X, Y,“学习者”t);
Mdl是一个ClassificationECOC多级模型。Mdl。B我naryLearners是一个78×1的单元阵列压缩分类插入码模型。Mdl.BinaryLearners {j} .Trained一个100乘1的细胞阵列CompactClassificationTree模型,j= 1,...,78.
您可以通过使用下面的方法来验证二进制学习者中是否包含一个不是残桩的弱学习者视图.
视图(Mdl.BinaryLearners {1} .Trained {1},“模式”,“图”)

显示样本内(再替换)误分类错误。
L=再悬浮(Mdl,“LossFun”,“classiferror”)
L=0.0819
使用bin和并行计算加速训练ECOC分类器
使用a训练一个单一对所有ECOC分类器GentleBoost具有代理分割的决策树集成。为了加快训练速度,bin数值预测器并使用并行计算。Binning仅在以下情况下有效fitcecoc使用树学习者。训练后,使用10倍交叉验证估计分类误差。请注意,并行计算需要parallel computing Toolbox™。
加载示例数据
装入并检查心律失常数据集。
负载心律失常[n,p]=尺寸(X)
n = 452
p = 279
isLabels =独特(Y);nLabels =元素个数(isLabels)
nLabels = 13
汇总(分类(Y))
价值计数百分比124554.20%2449.73%3153.32%4153.32%5132.88%6255.53%730.66%820.44%991.99%1050111.06%1440.88%1551.11%16224.87%
数据集包含279预测因素和样本量452相对较小。在16个不同的标签中,只有13个在响应中表示(Y).每个标签描述了不同程度的心律失常,54.20%的观察是在课堂上进行的1.
训练一个对所有ECOC分类器
创建集成模板。您必须指定至少三个参数:方法、学习者的数量和学习者的类型。对于本例,请指定“GentleBoost”在方法上,,One hundred.对于学习者的数量,以及由于缺少观察结果而使用代理拆分的决策树模板。
tTree=模板树(“代孕”,“上”);tEnsemble = templateEnsemble (“GentleBoost”,100,t树);
tEnsemble是模板对象。它的大部分属性都是空的,但是软件在训练期间用它们的默认值填充它们。
使用决策树的集合作为二叉学习器来训练一个一对所有的ECOC分类器。为了加快训练速度,可以使用装箱和并行计算。
装箱(
“NumBins”,50岁) -当你有一个大的训练数据集时,你可以通过使用“NumBins”名称-值对参数。此参数仅在以下情况下有效fitcecoc使用树学习者。如果指定“NumBins”值,然后软件将每个数值预测器放入指定数量的等概率容器中,然后根据容器指数而不是原始数据生长树。你可以试着“NumBins”,50岁先改,再改“NumBins”值取决于训练的准确性和速度。并行计算(
“选项”,statset('UseParallel',true)) -使用并行计算工具箱许可证,您可以通过使用并行计算来加快计算速度,并行计算将每个二进制学习器发送给池中的worker。worker的数量取决于您的系统配置。当你对二进制学习者使用决策树时,fitcecoc针对双核及以上系统,使用英特尔线程构建块(TBB)并行化培训。因此,指定“UseParallel”选项在单台计算机上没有帮助。请在群集上使用此选项。
另外,指定先验概率为1/K哪里K=13是不同类的数量。
选项=statset(“UseParallel”,真正的);Mdl = fitcecoc (X, Y,“编码”,“onevsall”,“学习者”tEnsemble,...“先前的”,“统一”,“NumBins”, 50岁,“选项”、选择);
使用“local”配置文件启动并行池(parpool)…连接到并行池(工作人员数量:6)。
Mdl是一个ClassificationECOC模型。
交叉验证
使用10倍交叉验证交叉验证ECOC分类器。
CVMdl = crossval (Mdl,“选项”、选择);
警告:一个或多个折叠不包含所有组中的点。
CVMdl是一个分类分区模型。警告表明,当软件训练至少一倍时,有些类没有表示。因此,这些折叠不能预测缺失类的标签。可以使用单元格索引和点表示法检查折叠的结果。例如,通过输入来访问第一次折叠的结果CVMdl。训练有素的{1}.
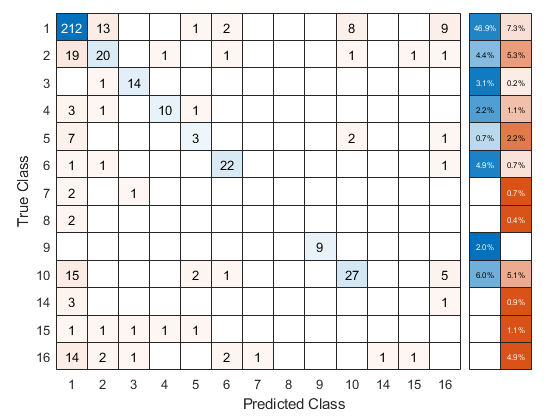
使用交叉验证的ECOC分类器来预测验证折叠标签。你可以用confusionchart.通过更改内部位置属性来移动和调整图表的大小,以确保百分比出现在行摘要中。
oofLabel = kfoldPredict (CVMdl,“选项”、选择);ConfMat = confusionchart (Y, oofLabel,“RowSummary”,“total-normalized”);ConfMat。InnerPosition = [0.10 0.12 0.85 0.85];
复制装箱数据
通过使用边沿训练模型的性质和离散化函数。
X = Mdl.X;%的预测数据Xbinned = 0(大小(X));边缘= Mdl.BinEdges;找到被分类的预测器的指数。idxNumeric =找到(~ cellfun (@isempty边缘));如果iscolumn(idxNumeric) idxNumeric = idxNumeric';结束为j = idxNumeric x = x (:,j);%如果x是一个表,则将x转换为数组。如果istable(x)x=表2阵列(x);结束%使用离散化函数将x分组到箱子中。xbinned =离散化(x,[无穷;边缘{};正]);Xbinned (:, j) = Xbinned;结束
Xbinned包含数值预测器的仓位索引,范围从1到仓位数。Xbinned值是0对于分类预测因子。如果X包含南s、 然后是相应的Xbinned值是南年代。
输入参数
输出参数
提示
NLearn从几十个到几千个不等。通常,一个具有良好预测能力的集成需要几百到几千个较弱的学习者。然而,您不需要一次训练那么多周期的合奏。你可以从培养几十个学习者开始,检查合奏表演,然后,如果有必要的话,用它来训练更多的弱学习者的简历对于分类问题,或者的简历回归问题。合奏表现取决于合奏设置和弱学习者的设置。也就是说,如果您使用默认参数指定弱学习器,则集成可以执行。因此,与集成设置一样,使用模板调整弱学习器的参数,并选择最小化泛化误差的值,是一种良好的实践。
在分类问题中(即,
类型是“分类”):如果集合聚合方法(
方法)是“包”和:错误分类成本是高度不平衡的,因此,对于袋装样本,软件抽样从类的独特观察,有很大的惩罚。
类的先验概率是高度倾斜的,软件对具有较大先验概率的类的唯一观测值进行过采样。
对于较小的样本量,这些组合可能会导致具有较大惩罚或先验概率的类别的带外观测的相对频率非常低。因此,估计的带外误差是高度可变的,可能难以解释。为了避免较大的估计带外误差方差,特别是f或小样本量,使用
成本拟合函数的名称-值对参数,或使用偏度较小的先验概率向量之前拟合函数的名称-值对参数。由于某些输入和输出参数的顺序对应于训练数据中的不同类,因此使用
一会拟合函数的名称-值对参数。为了快速确定类顺序,从训练数据中删除所有未分类的观察(即缺少标签),获取并显示所有不同类的数组,然后指定数组
一会。例如,假设响应变量(Y)是标签单元格数组。这段代码指定了变量中的类顺序一会.Ycat =分类(Y);一会=类别(Ycat)
绝对的分配<定义>对非机密的观察和类别不包括<定义>从它的输出。因此,如果将此代码用于包含标签的单元格数组或类似的代码用于类别数组,则不必删除缺少标签的观察结果以获得不同类的列表。要指定顺序,应该从最低表示的标签到最高表示的标签,然后快速确定类顺序(如前面的项目符号所示),但在将列表传递给之前,按频率排列列表中的类
一会.在前面的例子中,这段代码指定了类从最低到最多的顺序classNamesLH.Ycat =分类(Y);一会=类别(Ycat);频率= countcats (Ycat);[~, idx] =(频率)进行排序;classNamesLH =一会(idx);
算法
集成聚合算法的详细信息请参见集成算法.
如果您指定
方法作为一个boosting算法和学习者成为决策树,然后软件就会成长树桩默认情况下。一个决策桩是一个根节点连接到两个终端,叶节点。属性可以调整树的深度MaxNumSplits,MinLeafSize,MinParentSize名称-值对参数使用templateTree.该软件通过对误分类代价大的过抽样类和误分类代价小的欠抽样类进行抽样,生成袋装样本。因此,out- bag样本来自误分类代价大的类别的观察较少,而来自误分类代价小的类别的观察较多。如果您使用一个小数据集和一个高度倾斜的代价矩阵来训练一个分类集成,那么每个类的包外观察的数量可能会非常低。因此,估计的包外误差可能有很大的方差,可能很难解释。对于具有较大先验概率的类,也会出现同样的现象。
对于RUSBoost集成聚合方法(
方法),名称-值对参数RatioToSmallest指定每个类相对于最低表示类的采样比例。例如,假设训练数据中有2个类,一个和B.一个有100个观察结果B有10个观察。同样,假设最低代表的类具有米对训练数据的观察。如果你设置
“RatioToSmallest”,2,然后年代*米2 * 10=20..因此,该软件使用课堂上的20个观察结果来训练每一个学习者一个以及20个课堂观察B.如果你‘RatioToSmallest’,(2 - 2),你会得到相同的结果。如果你设置
‘RatioToSmallest’,(2,1),然后s1*米2 * 10=20.和s2*米1 * 10=10.因此,该软件使用课堂上的20个观察结果来训练每一个学习者一个以及10个课堂观察B.
对于决策树集合和双核系统及以上,
fitcensemble和fitrensemble使用英特尔并行训练®线程构建块(TBB)。关于Intel TBB的详细介绍请参见https://software.intel.com/en-us/intel-tbb.
你也可以从以下列表中选择一个网站:
