confusionchart
创建分类问题的混淆矩阵图
语法
描述
confusionchart (从真实标签创建混淆矩阵图trueLabels,predictedLabels)trueLabels和预测的标签predictedLabels并返回一个ConfusionMatrixChart对象混淆矩阵的行对应于真实类,列对应于预测类。对角线和非对角线单元格分别对应于正确和错误分类的观察结果。使用厘米在创建混乱矩阵图后修改它。有关属性列表,请参见ConfusionMatrixChart属性.
confusionchart (从数值混淆矩阵创建混淆矩阵图表米)米.如果您在工作空间中已经有一个数字混淆矩阵,请使用此语法。
confusionchart (控件中显示的类标签x设在和y设在。如果工作空间中已经有数字混淆矩阵和类标签,请使用此语法。米,classLabels)
confusionchart (在指定的图形、面板或制表符中创建混淆图父,___)父.
confusionchart (___,指定附加的名称,值)ConfusionMatrixChart属性使用一个或多个名称-值对参数。在所有其他输入参数之后指定属性。有关属性列表,请参见ConfusionMatrixChart属性.
厘米= confusionchart (___)ConfusionMatrixChart对象。使用厘米在创建图表后修改其属性。有关属性列表,请参见ConfusionMatrixChart属性.
例子
创建混淆矩阵图
载入费雪的虹膜数据集。
负载fisheririsX =量;Y =物种;
X是一个数字矩阵,包含四个花瓣测量150鸢尾。Y是包含相应虹膜种类的字符向量的细胞阵列。
训练k-最近邻(KNN)分类器,其中预测器中最近邻的数量(k)是5。一个好的做法是标准化数值预测器数据。
Mdl = fitcknn (X, Y,“NumNeighbors”5,“标准化”1);
预测训练数据的标签。
predictedY = resubPredict (Mdl);
从真实标签创建一个混淆矩阵图Y以及预测的标签predictedY.
cm=混淆图(Y,预测Y);
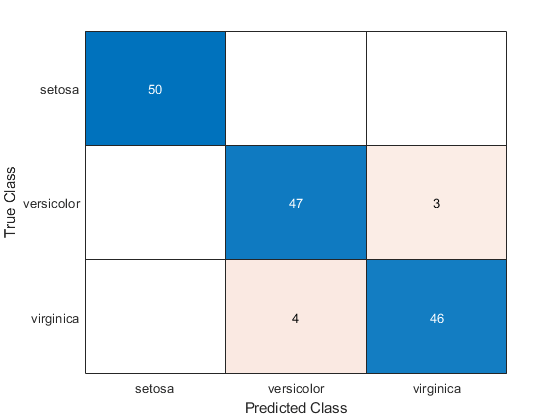
混淆矩阵显示了每个单元格中观察到的总数。混淆矩阵的行对应真实的类,列对应预测的类。对角线和非对角线细胞分别对应正确和错误分类的观察。
默认情况下,confusionchart按照定义的自然顺序对类进行排序排序.在这个例子中,类标签是字符向量confusionchart按字母顺序对类进行排序。使用sortClasses按指定顺序或混淆矩阵值对类进行排序。
的NormalizedValues属性包含混淆矩阵的值。使用点符号显示这些值。
厘米。NormalizedValues
ans =3×350 0 0 0 47 3 0 4 46
通过更改属性值修改混淆矩阵图表的外观和行为。添加标题。
厘米。Title =“使用KNN分类鸢尾花”;
添加列和行摘要。
厘米。RowSummary =“row-normalized”;厘米。ColumnSummary =“column-normalized”;
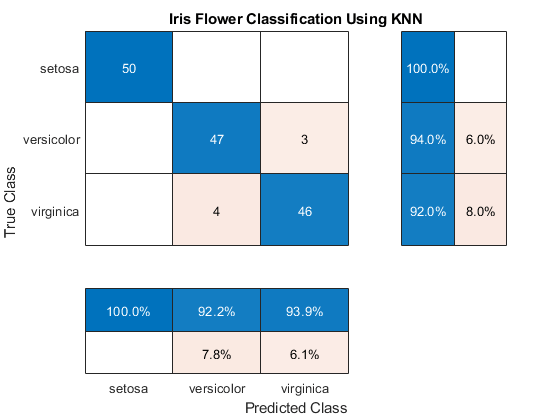
行规范化行摘要显示每个真实类正确和错误分类的观察值的百分比。列标准化列摘要显示每个预测类别正确和错误分类的观察值的百分比。
按精度或召回率对类进行排序
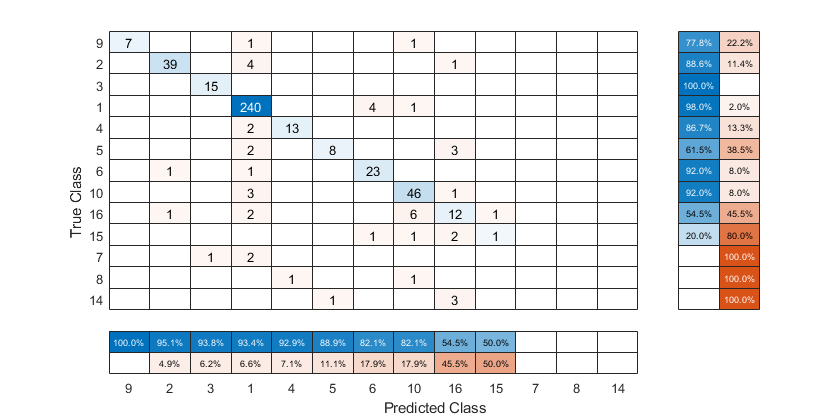
创建混淆矩阵图,并根据类别真阳性率(召回率)或类别阳性预测值(精度)对图表中的类别进行排序。
装入并检查心律失常数据集。
负载心律失常isLabels =独特(Y);nLabels =元素个数(isLabels)
nLabels = 13
汇总(分类(Y))
价值计数百分比124554.20%2449.73%3153.32%4153.32%5132.88%6255.53%730.66%820.44%991.99%1050111.06%1440.88%1551.11%16224.87%
数据包含16个不同的标签,描述不同程度的心律失常,但反应(Y)只包含13个不同的标签。
训练分类树并预测树的再替代响应。
Mdl = fitctree (X, Y);predictedY = resubPredict (Mdl);
从真实标签创建一个混淆矩阵图Y以及预测的标签predictedY.指定“行摘要”作为“row-normalized”在行汇总中显示真实阳性率和假阳性率。同时,指定“ColumnSummary”作为“column-normalized”在列摘要中显示阳性预测值和错误发现率。
无花果=图;厘米= confusionchart (Y, predictedY,“行摘要”,“row-normalized”,“ColumnSummary”,“column-normalized”);
调整混淆图容器的大小,使百分比显示在行摘要中。
fig_Position = fig.Position;fig_Position (3) = fig_Position (3) * 1.5;fig.Position = fig_Position;
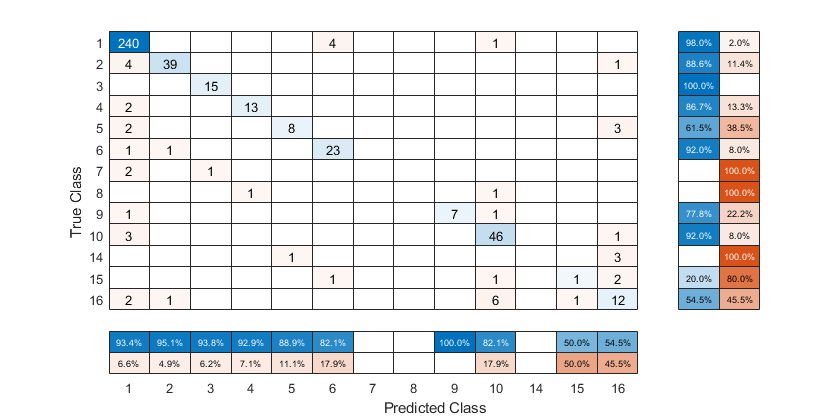
要根据真阳性率对混淆矩阵进行排序,请通过设置归一化财产“row-normalized”然后使用sortClasses.排序后,重新设置归一化属性回“绝对”显示每个单元格中观察到的总数。
厘米。归一化=“row-normalized”;sortClasses(厘米,“descending-diagonal”)厘米。归一化=“绝对”;
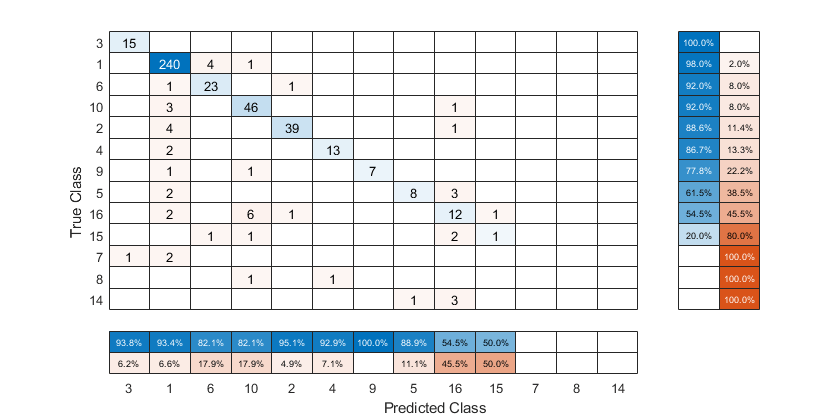
要根据阳性预测值对混淆矩阵进行排序,可以通过设置使每个列的单元格值归一化归一化财产“column-normalized”然后使用sortClasses.排序后,重新设置归一化属性回“绝对”显示每个单元格中观察到的总数。
厘米。归一化=“column-normalized”;sortClasses(厘米,“descending-diagonal”)厘米。归一化=“绝对”;
高数组分类的混淆矩阵
对一个高阵列的Fisher虹膜数据集进行分类。计算一个已知的和预测的高标签的混淆矩阵图使用confusionchart函数。
在高阵列上执行计算时,MATLAB®使用并行池(如果您有并行计算工具箱,则为默认值)™) 或本地MATLAB会话。若要在拥有并行计算工具箱时使用本地MATLAB会话运行示例,请使用地图还原器函数。
mapreduce (0)
载入费雪的虹膜数据集。
负载fisheriris
转换内存中的阵列量和物种高大的数组。
tx =高(量);泰=高(物种);
求高阵中观测的次数。
numObs =收集(长度(ty));% gather将高数组收集到内存中
使用。设置随机数生成器的种子rng和tallrng为再现性,并随机选取训练样本。结果可能会根据高数组的工作人员数量和执行环境而有所不同。有关详细信息,请参见控制代码运行的位置.
rng (“默认”) tallrng (“默认”) numTrain = floor(nummob /2);[txTrain, trIdx] = datasample (tx numTrain,“替换”,假);tyTrain=ty(trIdx);
在训练样本上拟合一个决策树分类器模型。
mdl = fitctree (txTrain tyTrain);
使用本地MATLAB会话评估tall表达式:-通过1/2:在0.82秒内完成-通过2/2:在0.62秒内完成评估在2.2秒内完成使用本地MATLAB会话评估tall表达式:-通过1/4:在0.51秒内完成-通过2/4:在0.62秒内完成-通过3/4:在0.52秒内完成-通过4/4:在0.71秒内完成评估在2.8秒内完成使用本地MATLAB会话评估tall表达式:-第1次(共4次)通过:在0.22秒内完成-第2次(共4次)通过:在0.36秒内完成-第3次(共4次)通过:在0.27秒内完成-第4次(共4次)通过:在2秒内完成评估使用本地MATLAB会话评估tall表达式:-第1次,共4次:用0.23秒完成-第2次,共4次:用0.27秒完成-第3次,共4次:用0.27秒完成-第4次,共4次:用0.47秒完成评估用1.6秒完成使用本地MATLAB会话评估tall表达式:-第1次,共4次:用0.25秒完成-第2次,共4次:用0.27秒完成-第3次,共4次:用0.65秒完成-通过4次中的第4次:在0.46秒内完成评估在2.2秒内完成
使用训练好的模型预测测试样本的标签。
txTest=tx(~trIdx,:);标签=预测(mdl、txTest);
为结果分类创建混淆矩阵图。
tyTest=ty(~trIdx);cm=混淆图(tyTest,标签)
using the Local MATLAB Session: - Pass 1 of 1: Completed in 0.14 sec Evaluation Completed in 0.39 sec使用Local MATLAB Session: - Pass 1 of 1: Completed in 0.25 sec Evaluation Completed in 0.43 sec
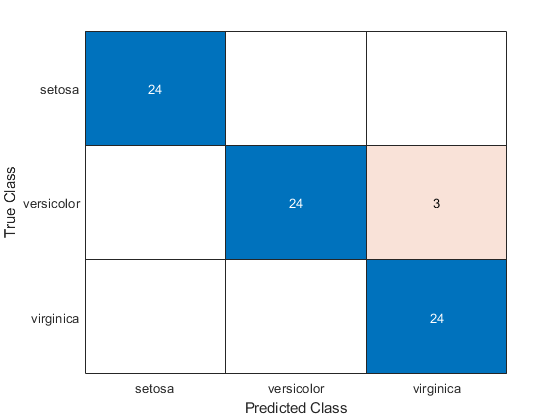
cm = ConfusionMatrixChart with properties: NormalizedValues: [3x3 double] ClassLabels: {3x1 cell}显示所有属性
混淆矩阵图显示,花斑类中的三个测量值被错误分类。所有属于setosa和virginica的测量值都被正确分类。
输入参数
输出参数
限制
MATLAB®不支持代码生成金宝app
ConfusionMatrixChart对象。
更多关于
扩展能力
你也可以从以下列表中选择一个网站:
