分类
分类混淆矩阵图
描述
例子
按精度或收回率对类进行排序
创建一个混淆矩阵图表,并根据类别真阳性率(召回率)或类别阳性预测值(精度)对图表的类别进行排序。
装入并检查心律失常数据集。
负载心律失常isLabels =独特(Y);nLabels =元素个数(isLabels)
nLabels = 13
汇总(分类(Y))
价值计数百分比124554.20%2449.73%3153.32%4153.32%5132.88%6255.53%730.66%820.44%991.99%1050111.06%1440.88%1551.11%16224.87%
数据包含16个不同的标签,描述不同程度的心律失常,但反应(Y)仅包括13个不同的标签。
训练分类树并预测树的再替代响应。
Mdl=fitctree(X,Y);predictedY=resubPredict(Mdl);
从真实标签创建一个混淆矩阵图Y以及预测的标签预测的.指定“RowSummary”作为“行规范化”在行摘要中显示真阳性率和假阳性率。另外,请指定“专栏摘要”作为“column-normalized”在列摘要中显示阳性预测值和错误发现率。
无花果=图;厘米= confusionchart (Y, predictedY,“RowSummary”,“行规范化”,“专栏摘要”,“column-normalized”);
调整混乱图表的容器大小,使百分比显示在行摘要中。
fig_Position = fig.Position;fig_Position (3) = fig_Position (3) * 1.5;fig.Position = fig_Position;
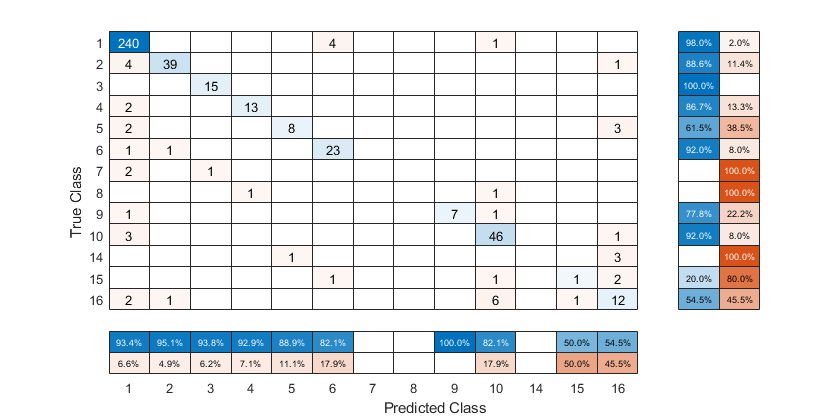
要根据真阳性率对混淆矩阵进行排序,请通过设置规范化财产“行规范化”然后使用分类.排序后,重置规范化财产返还给“绝对的”显示每个单元格中的观察总数。
厘米。归一化=“行规范化”;sortClasses(厘米,“下降对角线”)厘米。归一化=“绝对的”;
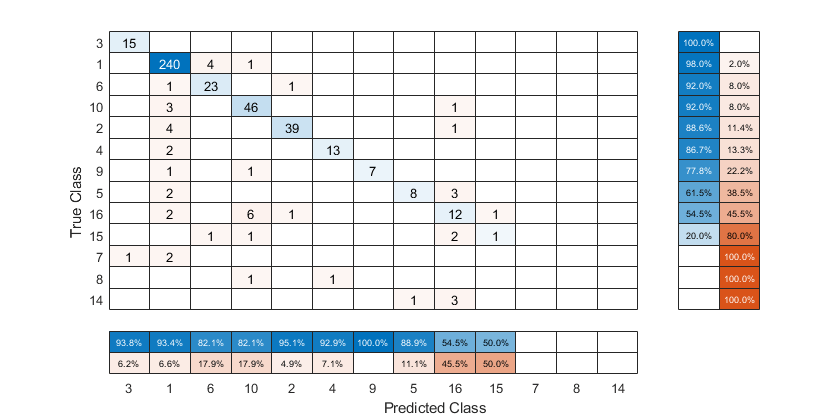
要根据阳性预测值对混淆矩阵进行排序,可以通过设置使每个列的单元格值归一化规范化财产“column-normalized”然后使用分类.排序后,重置规范化财产返还给“绝对的”显示每个单元格中的观察总数。
厘米。归一化=“column-normalized”;sortClasses(厘米,“下降对角线”)厘米。归一化=“绝对的”;
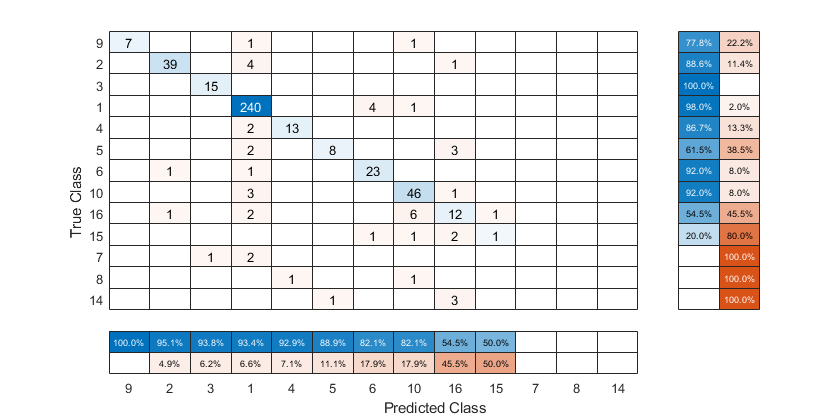
对类进行排序以聚集类似的类
使用以下命令创建混淆矩阵图:confusionchart函数,并通过使用“集群”选择的分类此示例还显示了如何使用pdist,链接和optimalleaforder功能。
生成包含八个不同类的示例数据集。
rng(“默认”)%为了再现性trueLabels=randi(81000,1);predictedLabels=trueLabels;
在前200个样本的{1,4,7}、{2,8}和{5,6}类之间插入混淆。
重命名=[4 8 3 7 6 5 1 2];predictedLabels(1:100)=重命名(predictedLabels(1:100));重命名=[7 8 3 1 6 5 4 2];predictedLabels(101:200)=重命名(predictedLabels(101:200));
从真实标签创建一个混淆矩阵图trueLabels以及预测的标签预测标签.
图cm1=混淆图(trueLabels、predictedLabels);

集群使用“集群”
使用“集群”选项
sortClasses (cm1,“集群”)

集群使用pdist,链接和optimalleaforder
而不是使用“集群”选项,您可以使用pdist,链接和optimalleaforder函数聚类混淆矩阵值。您可以使用这些函数的选项来定制集群。具体操作请参见对应功能参考页面。
假设您有一个混淆矩阵和类标签。
m = confusionmat (trueLabels predictedLabels);标签= [1 2 3 4 5 6 7 8];
使用,计算聚类矩阵并找到相应的类标签pdist,链接和optimalleaforder这个pdist函数计算欧氏距离D对之间的混淆矩阵值。的optimalleaforder函数返回分层二叉集群树的最优叶子排序连杆(D)使用的距离D.
D = pdist (m);idx = optimalleaforder(链接(D), D);clusteredM = m (idx idx);clusteredLabels =标签(idx);
使用聚集矩阵和相应的类标签创建混淆矩阵图。然后,使用类标签对类进行排序。
平方厘米= confusionchart (clusteredM clusteredLabels);clusteredLabels sortClasses(平方厘米)

排序混乱矩阵图平方厘米,您可以使用pdist,链接和optimalleaforder,与排序后的混淆矩阵图相同cm1,您可以使用“集群”选项
按固定顺序排序类
创建一个混淆矩阵图,并按固定顺序对该图的类进行排序。
加载Fisher的虹膜数据集。
负载鱼腥草X =量((51:150,1:50):);Y =物种((51:150,1:50):);
X是一个数字矩阵,包含四个花瓣测量150鸢尾。Y是包含相应虹膜种类的字符向量的细胞阵列。
列车ak-最近邻(KNN)分类器,其中预测值中的最近邻数(k)是5。一个好的做法是标准化数值预测器数据。
Mdl = fitcknn (X, Y,“纽曼尼斯堡”5.“标准化”,1);
预测训练数据的标签。
predictedY = resubPredict (Mdl);
从真实标签创建一个混淆矩阵图Y以及预测的标签预测的.
厘米= confusionchart (Y, predictedY);

默认情况下,confusionchart按照定义的自然顺序对类进行排序分类.在这个例子中,类标签是字符向量confusionchart按字母顺序对类进行排序。按固定顺序重新排列混淆矩阵图的类别。
sortClasses(厘米,“多色的”,“刚毛”,“virginica”])

输入参数
您还可以从以下列表中选择网站:
