分类符号
包:classreg.learning.classif
超类:压缩分类插入码
集成分类器
描述
分类符号将一组经过训练的弱学习者模型和这些学习者接受训练的数据相结合。它可以通过聚合来自弱学习者的预测来预测新数据的整体反应。它存储用于训练的数据,可以计算恢复替代预测,并可以根据需要恢复训练。
建设
使用。创建分类集成对象fitcensemble.
属性
|
的单元格数组指定为数值预测器的Bin边p数值向量,p是预测器的数量。每个向量包括一个数字预测器的箱边。用于分类预测器的单元格数组中的元素为空,因为软件没有将分类预测器存储在存储单元中。 只有当您指定 您可以复制被分类的预测器数据 X = mdl.X;%预测数据Xbinned = 0 (size(X));边缘= mdl.BinEdges;找到被分类的预测器的指数。idxNumeric =找到(~ cellfun (@isempty边缘));if iscolumn(idxNumeric) idxNumeric = idxNumeric';end for j = idxNumeric x = x (:,j);%如果x是一个表,则将x转换为数组。If istable(x) x = table2array(x);将x组到bin中
Xbinned包含数值预测器的仓位索引,范围从1到仓位数。Xbinned对于分类预测器,值为0。如果X包含南S,然后对应的Xbinned值是南年代。 |
|
分类预测指标,指定为一个正整数向量。 |
|
中的元素列表 |
|
描述如何 |
|
方阵, |
|
扩展的预测器名称,存储为字符向量的单元格数组。 如果模型对分类变量使用编码,那么 |
|
拟合信息的数字数组。的 |
|
字符向量描述的含义 |
|
超参数的交叉验证优化描述,存储为
|
|
集合中带有弱学习者名称的字符向量的单元数组。每个学习者的名字只出现一次。例如,如果你有100棵树, |
|
描述创建方法的字符向量 |
|
训练参数 |
|
在训练数据中包含观测数的数值标量。 |
|
受过训练的弱学习者的数量 |
|
预测器变量名称的单元格数组,按其在 |
|
每个类的先验概率的数字向量。元素的顺序 |
|
描述原因的字符向量 |
|
带有响应变量名称的字符向量 |
|
用于转换分数的函数句柄,或表示内置转换函数的字符向量。 添加或更改 斯考恩斯酒店函数' 或 ens.ScoreTransform=@函数 |
|
训练的分类模型的细胞向量。
|
|
中弱学习者训练权值的数值向量 |
|
逻辑大小矩阵 如果集合不是类型 |
|
缩放 |
|
训练集合的预测值矩阵或表 |
|
数字向量、分类向量、逻辑向量、字符数组或字符向量的单元数组。每一行的 |
对象的功能
契约 |
紧凑的系综分类 |
compareHoldout |
使用新数据比较两种分类模型的准确度 |
crossval |
交叉验证合奏 |
边缘 |
分类的优势 |
石灰 |
局部可解释的模型不可知解释(LIME) |
损失 |
分类错误 |
保证金 |
分类边距 |
partialDependence |
计算部分依赖 |
局部依赖 |
创建部分依赖图(PDP)和个人条件期望图(ICE) |
预测 |
使用分类模型的集合对观测结果进行分类 |
predictorImportance |
决策树分类集成中预测器重要性的估计 |
脱贫工人 |
删除紧凑分类集合的成员 |
resubEdge |
边的再替换分类 |
resubLoss |
再代换造成的分类错误 |
再精 |
再替换的分类边缘 |
resubPredict |
在分类模型集合中对观察进行分类 |
的简历 |
恢复训练合奏 |
沙普利 |
沙普利值 |
testckfold |
通过重复交叉验证比较两种分类模型的准确率 |
复制语义
价值。要了解值类如何影响复制操作,请参见复制对象.
例子
列车加强型分类系统
加载电离层数据集。
负载电离层
使用所有测量值和AdaBoostM1方法。
Mdl=fitcensemble(X,Y,“方法”,“AdaBoostM1”)
Mdl=ClassificationnSemble ResponseName:'Y'分类预测值:[]类名:{'b''g'}ScoreTransform:'none'NumObjections:351 NumTrained:100方法:'AdaBoostM1'LearnerNames:{'Tree'}ReasonForTermination:'在完成所请求的训练周期数后正常终止。'FitInfo:[100x1 double]FitInfoDescription:{2x1 cell}属性、方法
Mdl是一个分类符号模型对象。
Mdl。Trained是存储经过训练的分类树的100 × 1细胞向量的属性(CompactClassificationTree模型对象)组成集成。
绘制第一个经过训练的分类树的图。
视图(Mdl。训练{1},“模式”,“图”)
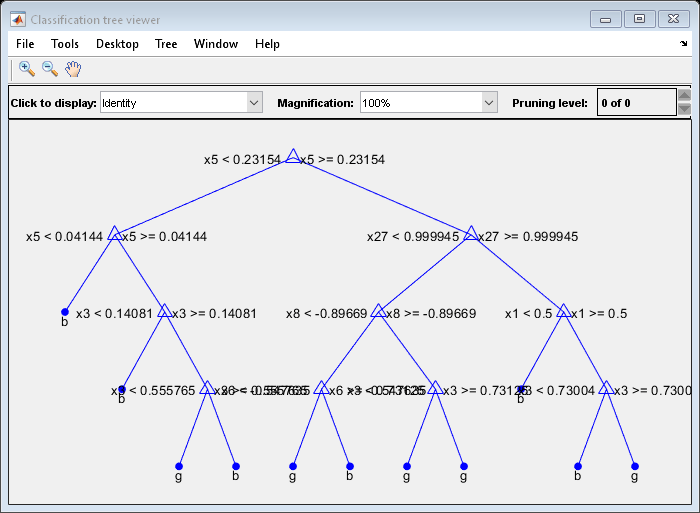
默认情况下,fitcensemble种植浅的树木,以增强树木的整体效果。
预测的平均值的标签X.
predMeanX =预测(Mdl,意味着(X))
predMeanX =1x1单元阵列{'g'}
提示
对于分类树的集合训练有素的的属性实体储存裸体的紧凑分类模型的-by-1细胞向量。用于树的文本或图形显示t在细胞向量中,输入:
视图(欧洲标准){用于使用LogitBoost或GentleBoost聚合的集成。t} .CompactRegressionLearner)视图(欧洲标准){用于所有其他聚合方法。t})
扩展功能
你也可以从以下列表中选择一个网站:
