石灰
局部可解释模型不可知解释(LIME)
描述
石灰通过查找重要的预测值并拟合简单的可解释模型,解释对查询点的机器学习模型(分类或回归)的预测。
您可以创建石灰对象与指定的查询点机器学习模型(查询点)和指定数量的重要预测(numImportantPredictors). 该软件生成一个合成数据集,并适合重要预测值的简单可解释模型,该模型可有效解释查询点周围合成数据的预测。简单模型可以是线性模型(默认)或决策树模型。
使用拟合的简单模型在指定的查询点处本地解释本地机器学习模型的预测。使用情节函数可视化LIME结果。根据局部的解释,你可以决定是否相信机器学习模型。
将新的简单模型用于另一个查询点适合函数。
创建
语法
描述
结果=石灰(黑盒子'CustomSyntheticData',customSyntheticData)石灰对象,使用预生成的自定义合成预测器数据集customSyntheticData. 这个石灰函数计算中样本的预测customSyntheticData.
结果=石灰(___“QueryPoint”,查询点“NumImportantPredictors”,numImportantPredictors)查询点. 您可以指定查询点和numImportantPredictors除了前面语法中的任何输入参数组合之外。
结果=石灰(___那名称,价值)“SimpleModelType”、“树”指定简单模型的类型为决策树模型。
输入参数
属性
例子
用决策树简单模型解释预测
培训分类模型并创建石灰使用决策树简单模型的对象。当你创造一个石灰对象,指定查询点和重要预测器的数量,以便软件生成合成数据集的样本,并为具有重要预测器的查询点拟合一个简单模型。然后利用目标函数在简单模型中显示估计的预测量的重要性情节.
加载CreditRating_Historical数据集。该数据集包含客户ID及其财务比率、行业标签和信用评级。
台= readtable ('信用_historical.dat');
显示表的前三行。
头(资源描述,3)
ans =.3×8表ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA行业评级 _____ _____ _____ _______ ________ _____ ________ ______ 62394 0.013 0.104 0.036 0.447 0.142 3{“BB”}48608 0.232 0.335 0.062 1.969 0.281 8 {A} 42444 0.311 0.367 0.074 1.935 0.366 1 {A}
通过删除客户id和评级列来创建一个预测器变量表tbl.
tblx = removevars(tbl,[“ID”那“评级”]);
通过使用培训Blackbox模型的信用评级模型fitcecoc.函数。
黑箱= fitcecoc (tblX,资源描述。评级,'pationoricalpricictors'那“行业”);
创建一个石灰对象,该对象使用决策树简单模型解释最后一次观察的预测。具体说明“NumImportantPredictors”至于最多6个重要预测因子。如果您指定了'QueryPoint'和“NumImportantPredictors”当您创建石灰对象,然后软件生成一个合成数据集的样本,并将一个简单的可解释模型适合于该合成数据集。你的结果可能与由于随机性所示的变化石灰.您可以设置一个随机种子使用RNG.用于再现性。
queryPoint=tblX(结束:)
查询点=1×6表WC_TA RE_TA EBIT_TA MVE_BVTD S_TA行业 _____ _____ _______ ________ ____ ________ 0.239 0.463 0.065 2.924 0.34 - 2
结果=石灰(黑盒,'QueryPoint'queryPoint,“NumImportantPredictors”6......'pationoricalpricictors'那“行业”那'simplemodeltype'那'树')
结果=石灰与属性:BlackboxModel:[1×1 ClassificationECOC] DataLocality: '全局' CategoricalPredictors:6类型: '分类' X:[3932×6表] QueryPoint:[1×6表] NumImportantPredictors:6个NumSyntheticData:5000 SyntheticData:[5000×6表]合身:{5000×1细胞} SimpleModel:[1×1 ClassificationTree] ImportantPredictors:[2 4] BlackboxFitted:{ 'AA'} SimpleModelFitted:{ 'AA'}
绘制石灰目的结果通过使用目标函数情节.要显示任何预测名称的现有下划线,改变ticklabelinterpreter.轴到的值'没有任何'.
f =情节(结果);f.CurrentAxes.TickLabelInterpreter ='没有任何';
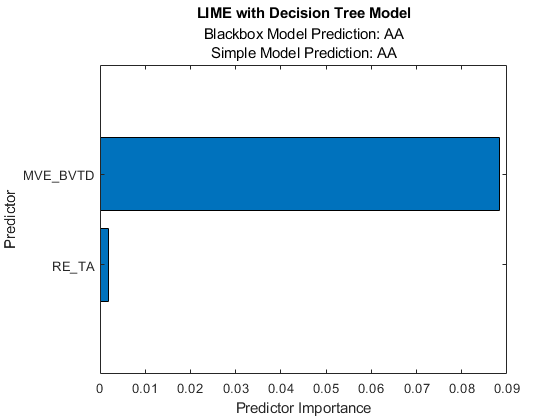
绘图显示查询点的两个预测,它们对应于黑匣子财产和简单模型性质结果.
水平条形图显示排序的预测值重要性值。石灰查找财务比率变量息税前利润和WC_TA作为查询点的重要预测器。
您可以通过使用数据提示或栏属性. 例如,您可以找到酒吧通过使用对象findobj函数,并在栏的末端添加标签文本函数。
B = findobj(F,“类型”那'酒吧');文本(b.YEndPoints + 0.001,b.XEndPoints,串(b.YData))
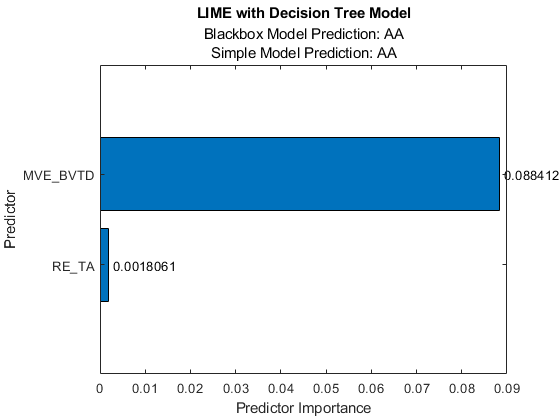
或者,您可以使用预测器变量名在表中显示系数值。
小鬼= b.YData;flipud (array2table(小鬼”,......“RowNames”f.CurrentAxes.YTickLabel,'VariableNames', {“预测的重要性”})))
ans =.2×1表预测的重要性 ____________________ MVE_BVTD 0.088695 RE_TA 0.0018228
解释预测与线性简单模型
训练回归模型并创建石灰对象,该对象使用线性简单模型。当你创造一个石灰对象,如果不指定查询点和重要的预测数,则该软件生成的合成数据集的样本,但是不符合一个简单的模型。使用对象功能适合以适应查询点的简单模型。然后用目标函数显示拟合的线性简单模型的系数情节.
加载carbig数据集,其中包含在上世纪70年代和80年代初制造的汽车的测量..
负载carbig
创建一个包含预测变量的表加速那气瓶,等等,以及响应变量MPG..
TBL =表(加速度,缸,排气量,马力,Model_Year,体重,MPG);
在训练组中删除丢失的值可以帮助减少内存消耗和加快培训菲特克内尔函数。删除tbl.
台= rmmissing(台);
通过删除响应变量来创建预测变量表tbl.
tblX = removevars(资源描述,'mpg');
列车的黑匣子模型MPG.通过使用菲特克内尔功能,并创建一个石灰对象。指定一个预测器数据集,因为mdl不包含预测数据。你的结果可能与由于随机性所示的变化菲特克内尔和石灰.您可以设置一个随机种子使用RNG.用于再现性。
mdl = fitrkernel (tblX,资源描述。英里/加仑,'pationoricalpricictors'[2 - 5]);结果=石灰(mdl tblX,'pationoricalpricictors',[2 5])
结果=石灰与属性:BlackboxModel:[1×1 RegressionKernel] DataLocality:“全球”CategoricalPredictors:[2 5]类型:“回归”X:[392×6表]QueryPoint: [] NumImportantPredictors: [] NumSyntheticData: 5000 SyntheticData:[5000×6表]安装:[5000×1双]SimpleModel: [] ImportantPredictors: [] BlackboxFitted:[] SimpleModelFitted: []
结果包含生成的合成数据集。这SimpleModel属性为空([]).
为第一次观测拟合线性简单模型tblx..指定要查找的重要预测器的数量为3。
queryPoint = tblX(1,:)
查询点=1×6表加速度油缸位移马力Model_Year重量____________ _________ ____________ __________ __________ ______ 12 8 307 130 70 3504
结果=拟合(结果,queryPoint,3);
绘制石灰目的结果通过使用目标函数情节.要显示任何预测名称的现有下划线,改变ticklabelinterpreter.轴到的值'没有任何'.
f =情节(结果);f.CurrentAxes.TickLabelInterpreter ='没有任何';
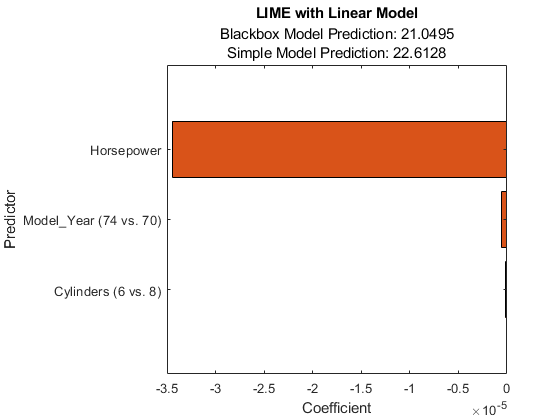
绘图显示查询点的两个预测,它们对应于黑匣子财产和简单模型性质结果.
水平条形图显示简单模型的系数值,按其绝对值排序。石灰发现马力那Model_Year,气瓶作为查询点的重要预测器。
对于多查询点飞度简单模型
培训分类模型并创建石灰使用决策树简单模型的对象。适合多个查询点的多种型号。
加载CreditRating_Historical数据集。该数据集包含客户ID及其财务比率、行业标签和信用评级。
台= readtable ('信用_historical.dat');
通过删除客户id和评级列来创建一个预测器变量表tbl.
tblx = removevars(tbl,[“ID”那“评级”]);
通过使用培训Blackbox模型的信用评级模型fitcecoc.函数。
黑箱= fitcecoc (tblX,资源描述。评级,'pationoricalpricictors'那“行业”)
blackbox = ClassificationECOC PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'} ResponseName: 'Y' CategoricalPredictors: 6 ClassNames: {'A' ' 'AA' ' 'AAA' ' 'B' ' 'BB' 'BBB' ' 'CCC'} ScoreTransform: 'none' BinaryLearners: {21×1 cell} CodingName: 'onevsone'属性,方法
创建一个石灰对象的黑盒子模型由于数据的随机性,您的结果可能与显示的结果不同石灰.您可以设置一个随机种子使用RNG.用于再现性。
结果=石灰(黑盒,'pationoricalpricictors'那“行业”);
发现两个查询点,其真实的评价值AAA和B., 分别。
queryPoint(1,:) = tblX(FIND(STRCMP(tbl.Rating,“AAA”), 1):);queryPoint (2) = tblX(找到(strcmp(资源描述。评级,'B'), 1),:)
查询点=2×6表WC_TA RE_TA EBIT_TA MVE_BVTD S_TA行业_____ _____ _______ ________ _____ ________ 0.121 0.413 0.057 3.647 0.466 0.019 12 0.009 0.042 0.257 0.119 1
适合第一个查询点的线性简单模型。将重要预测因子的数量设置为4。
newresults1 =适合(结果,queryPoint (1:), 4);
绘制LIME结果图新结果1第一个查询点。要显示任何预测名称的现有下划线,改变ticklabelinterpreter.轴到的值'没有任何'.
f1 =情节(newresults1);f1.CurrentAxes。TickLabelInterpreter ='没有任何';
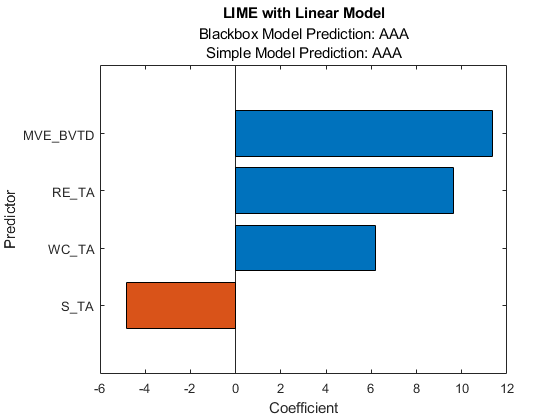
适用于第一个查询点的线性决策树模型。
newresults2 =适合(结果,queryPoint(1:), 6日'simplemodeltype'那'树');f2 =情节(newresults2);f2.CurrentAxes。TickLabelInterpreter ='没有任何';
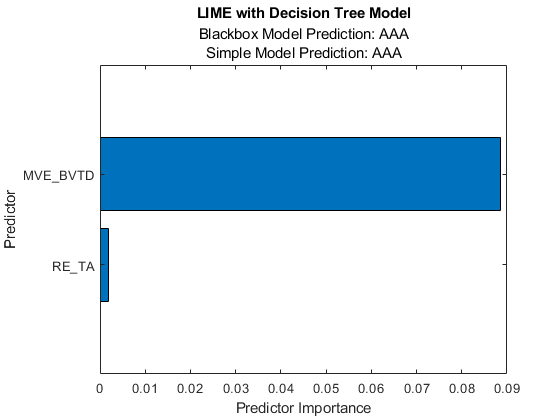
简单的模型新结果1和新结果2既找到MVE_BVTD和RE_TA作为重要的预测因子。
适用于第二个查询点的线性简单模型,并对第二个查询点绘制石灰结果。
newresults3=拟合(结果,查询点(2,:),4);f3=绘图(新结果3);f3.CurrentAxes.TickLabelInterpreter='没有任何';
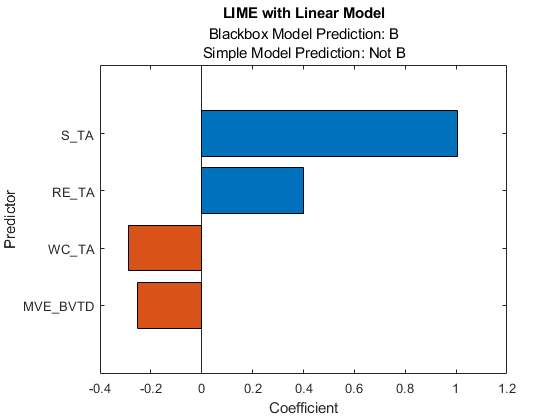
来自黑盒子模型是B.,但简单模型的预测则不然B..当两个预测是不一样的,你可以指定一个较小的'KernelWidth'价值。该软件使用更重要的权重拟合在查询点附近的样本上的权重。如果查询点是异常值或位于决策边界附近,那么即使指定小型,两个预测值也可以不同'KernelWidth'价值。在这种情况下,您可以更改其他名称 - 值对的参数。例如,您可以生成本地合成数据集(指定'datalocality'的石灰作为'当地的')对于查询点并增加样本的数量('NumSyntheticData'的石灰或适合)在合成数据集中。您还可以使用不同的距离度量(“距离”的石灰或适合).
适合线性简单模型,小'KernelWidth'价值。
newresults4 =适合(结果,queryPoint (2:), 4,'KernelWidth', 0.01);f4 =情节(newresults4);f4.CurrentAxes。TickLabelInterpreter ='没有任何';
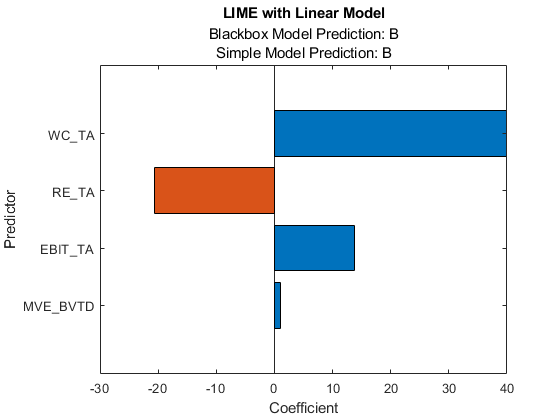
第一个和第二个查询点的信用评级是AAA和B., 分别。简单的模型新结果1和新结果4既找到MVE_BVTD那RE_TA,WC_TA作为重要的预测因子。但是,它们的系数值是不同的。图表显示,这些预测者的行为因信用评级的不同而不同。
更多关于
算法
工具书类
也可以看看
您还可以从以下列表中选择一个网站:
