fitrtree
拟合二叉决策树进行回归
语法
描述
树= fitrtree (资源描述,ResponseVarName)资源描述中包含的输出(响应)资源描述。ResponseVarName。返回的树二叉树的每个分支节点是根据列的值分割的吗资源描述。
例子
构建回归树
加载示例数据。
负载carsmall
使用样本数据构建回归树。响应变量是每加仑英里数,即MPG。
tree = fitrtree([重量,气缸],MPG,…“CategoricalPredictors”2,“MinParentSize”, 20岁,…“PredictorNames”, {' W ',“C”})
tree = RegressionTree PredictorNames: {'W' 'C'} ResponseName: 'Y' CategoricalPredictors: 2 ResponseTransform: 'none' NumObservations: 94属性,方法
预测4、6、8缸4000磅重汽车的行驶里程。
MPG4Kpred = predict(tree,[4000];4000 6;4000 8])
MPG4Kpred =3×119.2778 19.2778 14.3889
控制回归树深度
fitrtree默认情况下生长深度决策树。您可以种植较浅的树以降低模型复杂性或计算时间。控件来控制树的深度“MaxNumSplits”,“MinLeafSize”,或“MinParentSize”名称-值对参数。
加载carsmall数据集。考虑位移,马力,重量作为反应的预测者英里/加仑。
负载carsmallX =[排量马力重量];
用于生长回归树的树深度控制器的默认值为:
N - 1为MaxNumSplits。n为训练样本大小。1为MinLeafSize。10为MinParentSize。
对于较大的训练样本量,这些默认值倾向于生长深树。
使用树深度控制的默认值训练回归树。使用10倍交叉验证对模型进行交叉验证。
rng (1);%为了重现性MdlDefault = fitrtree(X,MPG,“CrossVal”,“上”);
画一个直方图,表示强加在树上的裂缝数量。强制分裂的次数比叶子的数量少一次。另外,查看其中一棵树。
numBranches = @(x)sum(x. isbranch);mdldefaultnumsplit = cellfun(numBranches, MdlDefault.Trained);图;直方图(mdlDefaultNumSplits)

视图(MdlDefault。训练有素的{1},“模式”,“图”)

平均分裂次数在14到15次之间。
假设您想要一个不像使用默认分割数训练的回归树那么复杂(深度)的回归树。训练另一棵回归树,但将拆分的最大数量设置为7,这大约是默认回归树拆分的平均数量的一半。使用10倍交叉验证对模型进行交叉验证。
md17 = fitrtree(X,MPG,“MaxNumSplits”7“CrossVal”,“上”);视图(Mdl7。Trained{1},“模式”,“图”)

比较交叉验证模型的均方误差(MSEs)。
mseDefault = kfoldLoss(MdlDefault)
mseDefault = 25.7383
mse7 = kfoldLoss(md17)
Mse7 = 26.5748
Mdl7要简单得多,性能也只比MdlDefault。
优化回归树
自动优化超参数fitrtree。
加载carsmall数据集。
负载carsmall
使用重量和马力作为预测者英里/加仑。通过使用自动超参数优化,找到最小化五倍交叉验证损失的超参数。
为了再现性,设置随机种子并使用“expected-improvement-plus”采集功能。
X =[重量,马力];Y = mpg;rng默认的Mdl = fittrtree (X,Y,“OptimizeHyperparameters”,“汽车”,…“HyperparameterOptimizationOptions”结构(“AcquisitionFunctionName”,…“expected-improvement-plus”))
|======================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | MinLeafSize | | | |结果日志(1 +损失)运行时| | | (estim(观察) .) | | |======================================================================================| | 最好1 | | 3.2818 | 0.23977 | 3.2818 | 3.2818 | 28 |
| 2 |接收| 3.4183 | 0.06584 | 3.2818 | 3.2888 | 1 |
| |最佳| 3.1457 | 0.048394 | 3.1457 | 3.1628 | 4 |
| 4 |最佳| 2.9885 | 0.052701 | 2.9885 | 2.9885 | 9 |
| 5 |接收| 2.9978 | 0.069199 | 2.9885 | 2.9885 | 7 |
| 6 |接收| 3.0203 | 0.049133 | 2.9885 | 3.0013 | 8 |
| 7 |接收| 2.9885 | 0.05291 | 2.9885 | 2.9981 | 9 |
| 8 |最佳| 2.9589 | 0.041088 | 2.9589 | 2.9589 | 10 |
| 9 |接收| 3.078 | 0.033971 | 2.9589 | 2.9888 | 13 |
| 10 |接收| 4.1881 | 0.06277 | 2.9589 | 2.9592 | 50 |
| 11 |接收| 3.4182 | 0.056473 | 2.9589 | 2.9592 | 2 |
| 12 |接收| 3.0376 | 0.043713 | 2.9589 | 2.9591 | 6 |
| 13 |接收| 3.1453 | 0.059096 | 2.9589 | 2.9591 | 20 |
| 14 |接收| 2.9589 | 0.04608 | 2.9589 | 2.959 | 10 |
| 15 |接收| 3.0123 | 0.037637 | 2.9589 | 2.9728 | 11 |
| 16 |接收| 2.9589 | 0.049064 | 2.9589 | 2.9593 | 10 |
| 17 |接收| 3.3055 | 0.042526 | 2.9589 | 2.9593 | 3 |
| 18 |接收| 2.9589 | 0.043994 | 2.9589 | 2.9592 | 10 |
| 19 |接收| 3.4577 | 0.033968 | 2.9589 | 2.9591 | 37 |
| 20 |接收| 3.2166 | 0.045131 | 2.9589 | 2.959 | 16 |
|======================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | MinLeafSize | | | |结果日志(1 +损失)运行时| | | (estim(观察) .) | | |======================================================================================| | 21日|接受| 3.107 | 0.04289 | 2.9589 | 2.9591 | 5 |
| 22 |接受| 3.2818 | 0.031364 | 2.9589 | 2.959 | 24 |
| 23 |接收| 3.3226 | 0.042712 | 2.9589 | 2.959 | 32 |
| 24 |接收| 4.1881 | 0.03763 | 2.9589 | 2.9589 | 43 |
| 25 |接受| 3.1789 | 0.035856 | 2.9589 | 2.9589 | 18 |
| 26 |接收| 3.0992 | 0.09437 | 2.9589 | 2.9589 | 14 |
| 27 |接收| 3.0556 | 0.061199 | 2.9589 | 2.9589 | 22 |
| 28 |接收| 3.0459 | 0.045581 | 2.9589 | 2.9589 | 12 |
| 29 |接收| 3.2818 | 0.036777 | 2.9589 | 2.9589 | 26 |
| 30 |接收| 3.4361 | 0.055666 | 2.9589 | 2.9589 | 34 |


__________________________________________________________ 优化完成。达到30分的评价。总函数评估:30总运行时间:26.7915秒总目标函数评估时间:1.6575最佳观察可行点:MinLeafSize ___________ 10目标函数观察值= 2.9589目标函数估计值= 2.9589函数评估时间= 0.041088最佳估计可行点(根据模型):MinLeafSize ___________ 10目标函数估计值= 2.9589函数评估估计时间= 0.050022
Mdl = RegressionTree responsenname: 'Y' CategoricalPredictors: [] ResponseTransform: 'none' NumObservations: 94 HyperparameterOptimizationResults: [1x1贝叶斯优化]属性,方法
无偏预测器重要性估计
加载carsmall数据集。考虑一个模型,该模型预测给定加速度、气缸数量、发动机排量、马力、制造商、型号年份和重量的汽车的平均燃油经济性。考虑气缸,制造行业,Model_Year作为分类变量。
负载carsmall柱体=分类(柱体);Mfg = categorical(cellstr(Mfg));Model_Year = categorical(Model_Year);X =表(加速度,气缸,排量,马力,制造商,…Model_Year、重量、MPG);
显示分类变量中表示的类别数量。
numCylinders = nummel (categories(Cylinders))
numCylinders = 3
numMfg = nummel (categories(Mfg))
numMfg = 28
numModelYear = nummel (categories(Model_Year))
numModelYear = 3
因为只有3个类别气缸和Model_Year,标准的CART,预测分割算法更倾向于在这两个变量上分割连续预测器。
使用整个数据集训练回归树。要生长无偏树,请指定使用曲率检验来分割预测器。因为数据中有缺失的值,所以指定使用代理分割。
Mdl = fitrtree(X,“英里”,“PredictorSelection”,“弯曲”,“代孕”,“上”);
通过将每个预测器上的分裂导致的风险变化加起来,并将总和除以分支节点的数量,来估计预测器的重要性值。使用条形图比较估算值。
imp = predictorImportance(Mdl);图;酒吧(imp);标题(“预测重要性估计”);ylabel (“估计”);包含(“预测”);H = gca;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;
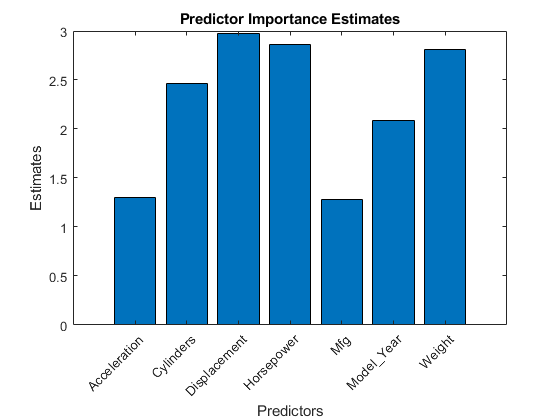
在这种情况下,位移最重要的预测因素是什么马力。
在Tall数组上控制最大树深度
fitrtree默认情况下生长深度决策树。构建一个较浅的树,它需要较少的遍历高数组。使用“MaxDepth”名称-值对参数来控制最大树深度。
当您在高数组上执行计算时,MATLAB®使用并行池(如果您有并行计算工具箱™,则默认为并行池)或本地MATLAB会话。如果您希望在使用并行计算工具箱时使用本地MATLAB会话运行示例,则可以通过使用mapreduce函数。
加载carsmall数据集。考虑位移,马力,重量作为反应的预测者英里/加仑。
负载carsmallX =[排量马力重量];
转换内存中的数组X和英里/加仑到高数组。
tx = tall(X);
使用“本地”配置文件启动并行池(parpool)…连接到并行池(工人数量:6)。
ty = tall(MPG);
使用所有的观测值生长一个回归树。让树长到最大可能的深度。
为了再现性,设置使用的随机数生成器的种子rng和tallrng。结果可能因工作线程的数量和tall数组的执行环境而异。有关详情,请参阅控制代码运行的位置。
rng (“默认”) tallrng (“默认”) Mdl = fitrtree(tx,ty);
评估高表达式使用并行池“当地”:——通过1 2:在3.3秒完成,通过2 2:在1秒完成评估在6.8秒完成评估高表达式使用并行池“当地”:——通过1 6:在1.4秒完成,通过2 6:在0.41秒完成,通过3 6:在2.3秒完成,通过4 6:在3.6秒完成,通过5 6:在1.5秒完成,通过6 6:在2.9秒完成评估在14秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.45秒完成,通过2 7:在0.36秒完成,通过3 7:在1.2秒完成,通过4 7:在2.5秒完成,通过5 7:在0.85秒完成,通过6 7:在1.4秒完成,通过7 7:在2.2秒完成评估在10秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.45秒完成,通过2 7:在0.36秒完成,通过3 7:在1.1秒完成,通过4 7:在2.6秒完成,通过5 7:在1秒完成,通过6 7:在1.5秒完成,通过7 7:在3.2秒完成评估在12秒完成评估高表达使用并行池“当地”:——通过1 7:在0.43秒完成,通过2 7:在0.38秒完成,通过3 7:在1.6秒完成,通过4 7:在2.6秒完成,通过5 7:完成0.89秒-通过6 7:在1.2秒完成,通过7 7:在2.3秒完成评估在11秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.47秒完成,通过2 7:在0.38秒完成,通过3 7:在1.1秒完成,通过4 7:在2秒完成,通过5 7:在0.76秒完成,通过6 7:在1.2秒完成,通过7 7:在2.4秒完成评估在9.5秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.42秒完成,通过2 7:在0.33秒完成,通过3 7:在1.2秒完成,通过4 7:在2.2秒完成,通过5 7:在0.82秒完成,通过6 7:在1.3秒完成,通过7 7:在2.2秒完成评估在9.7秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.49秒完成,通过2 7:在0.36秒完成,通过3 7:在1.1秒完成,通过4 7:在2.8秒完成,通过5 7:在1.2秒完成,通过6 7:在1.1秒完成,通过7 7:在2.3秒完成评估在10秒完成评估高表达使用并行池“当地”:——通过1 7:在0.5秒完成,通过2 7:在0.34秒完成,通过3 7:在1.1秒完成,通过4 7:在1.8秒完成,通过5 7:在0.75秒内完成-通过7中的6:在1.1秒内完成-通过7中的7:在1.8秒内完成评估在8.5秒内完成
查看训练树Mdl。
视图(Mdl,“模式”,“图”)

Mdl树有深度吗8。
估计样本内均方误差。
MSE_Mdl = collect (loss(Mdl,tx,ty))
使用并行池'local'计算tall表达式:-通过1 / 1:在3.1秒内完成评估在3.7秒内完成
MSE_Mdl = 4.9078
使用所有的观测值生长一个回归树。通过指定最大树深度来限制树深度4。
Mdl2 = fitrtree(tx,ty,“MaxDepth”4);
评估高表达式使用并行池“当地”:——通过1 2:在0.38秒完成,通过2 2:在0.35秒完成评估在1.2秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.42秒完成,通过2 7:在0.35秒完成,通过3 7:在1.2秒完成,通过4 7:在1.9秒完成,通过5 7:在0.73秒完成,通过6 7:在1.2秒完成,通过7 7:在2.1秒完成评估在8.9秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.44秒完成,通过2 7:在0.39秒完成,通过3 7:在1.1秒完成,通过4 7:在2.1秒完成,通过5 7:在0.74秒完成,通过6 7:在1.1秒完成,通过7 7:在2.7秒完成评估在9.7秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.46秒完成,通过2 7:在0.37秒完成,通过3 7:在1.1秒完成,通过4 7:在1.9秒完成,通过5 7:在0.79秒完成,通过6 7:在1.1秒完成,通过7 7:在2.3秒完成评估在9.1秒完成评估高表达使用并行池“当地”:——通过1 7:在0.43秒完成,通过2 7:在0.41秒完成,通过3 7:在1.1秒完成,通过4 7:在1.9秒完成,通过5 7:在0.72秒内完成-通过7中的6:在1秒内完成-通过7中的7:在2.2秒内完成评估在8.9秒内完成
查看训练树Mdl2。
视图(Mdl2,“模式”,“图”)

估计样本内均方误差。
MSE_Mdl2 = collect (loss(Mdl2,tx,ty))
使用并行池'local'计算tall表达式:-通过1 / 1:在0.86秒内完成评估在1.3秒内完成
MSE_Mdl2 = 9.3903
Mdl2深度为4且样本内均方误差高于均方误差的较不复杂的树是否Mdl。
在Tall数组上优化回归树
使用tall数组自动优化回归树的超参数。样本数据集为carsmall数据集。本例将数据集转换为tall数组,并使用它来运行优化过程。
当您在高数组上执行计算时,MATLAB®使用并行池(如果您有并行计算工具箱™,则默认为并行池)或本地MATLAB会话。如果您希望在使用并行计算工具箱时使用本地MATLAB会话运行示例,则可以通过使用mapreduce函数。
加载carsmall数据集。考虑位移,马力,重量作为反应的预测者英里/加仑。
负载carsmallX =[排量马力重量];
转换内存中的数组X和英里/加仑到高数组。
tx = tall(X);
使用“本地”配置文件启动并行池(parpool)…连接到并行池(工人数量:6)。
ty = tall(MPG);
方法自动优化超参数“OptimizeHyperparameters”名称-值对参数。找到最优“MinLeafSize”最大限度地减少保留交叉验证损失的值。(指定“汽车”使用“MinLeafSize”.)为了再现性,请使用“expected-improvement-plus”采集函数和设置种子的随机数生成器使用rng和tallrng。结果可能因工作线程的数量和tall数组的执行环境而异。有关详情,请参阅控制代码运行的位置。
rng (“默认”) tallrng (“默认”) [Mdl,FitInfo,HyperparameterOptimizationResults] = fittrtree (tx,ty,…“OptimizeHyperparameters”,“汽车”,…“HyperparameterOptimizationOptions”结构(“坚持”, 0.3,…“AcquisitionFunctionName”,“expected-improvement-plus”))
评估高表达式使用并行池“当地”:通过1对1:在4.4秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.97秒完成,通过2 4:在1.6秒完成,通过3 4:在3.6秒完成,通过4 4:在2.4秒完成评估在9.8秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.55秒完成,通过2 4:完成1.3秒-通过3 4:在2.7秒完成,通过4 4:在1.9秒完成评估在7.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.52秒完成,通过2 4:在1.3秒完成,通过3 4:完成在3秒-通过4 4:在2秒完成评估在8.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.55秒完成,通过2 4:完成1.4秒-通过3 4:在2.6秒完成,通过4 4:在2秒完成评估在7.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.61秒完成,通过2 4:在1.2秒完成,通过3 4:在2.1秒完成,通过4 4:在1.7秒完成评估在6.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.53秒完成,通过2 4:在1.2秒内完成-通过4个中的3个:在2.4秒内完成-通过4个中的4个:在1.6秒内完成评估在6.6秒内完成使用并行池'local'评估tall表达式:-通过1个中的1个:在1.4秒内完成评估在1.7秒内完成|======================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | MinLeafSize | | | |结果日志(1 +损失)运行时| | | (estim(观察) .) | | |======================================================================================| | 最好1 | | 3.2007 | 69.013 | 3.2007 | 3.2007 | 2 |
评估高表达式使用并行池“当地”:通过1对1:在0.52秒完成评估在0.83秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.65秒完成,通过2 4:在1.2秒完成,通过3 4:完成在3秒-通过4 4:在2秒完成评估在8.3秒完成评估高表达式使用并行池“当地”:-通过1的1:在0.79秒内完成评估在1秒内完成| |错误| NaN | 13.772 | NaN | 3.2007 | 46 |
评估高表达式使用并行池“当地”:通过1对1:在0.52秒完成评估在0.81秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.57秒完成,通过2 4:在1.3秒完成,通过3 4:在2.2秒完成,通过4 4:在1.7秒完成评估在6.6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:完成1.2秒-通过3 4:在2.7秒完成,通过4 4:在1.7秒完成评估在6.9秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒完成,通过3 4:在2.1秒完成,通过4 4:在1.9秒完成评估在6.4秒完成评估高表达式使用并行池“当地”:-通过1的1:0.72秒完成评估0.99秒完成最佳| 3.1876 | 29.091 | 3.1876 | 3.1884 | 18 |
评估高表达式使用并行池“当地”:通过1对1:在0.48秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:在1.2秒完成,通过3 4:在1.9秒完成,通过4 4:在1.4秒完成评估在5.8秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:完成1.1秒-通过3 4:完成2秒-通过4 4:在1.5秒完成评估在5.8秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.54秒完成,通过2 4:在1.1秒完成,通过3 4:在1.9秒完成,通过4 4:在1.4秒完成评估在5.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.1秒内完成-通过3 / 4:在1.8秒内完成-通过4 / 4:在1.4秒内完成评估在5.5秒内完成评估使用并行池'local'的tall表达式:-通过1 / 1:在0.64秒内完成评估在0.92秒内完成| 4 |最佳| 2.9048 | 33.465 | 2.9048 | 2.9537 | 6 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.71秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.1秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在5.9秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:完成1.1秒-通过3 4:在1.9秒完成,通过4 4:在1.5秒完成评估在5.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒完成,通过3 4:在1.9秒完成,通过4 4:在1.4秒完成评估在5.6秒完成评估高表达式使用并行池“当地”:-通过1的1:在0.66秒内完成评估在0.92秒内完成| 5 |接受| 3.2895 | 25.902 | 2.9048 | 2.9048 | 15 |
评估高表达式使用并行池“当地”:通过1对1:在0.54秒完成评估在0.82秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.53秒完成,通过2 4:在1.2秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:完成1.1秒-通过3 4:在2.1秒完成,通过4 4:在1.9秒完成评估在6.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.49秒完成,通过2 4:在1.1秒完成,通过3 4:在1.9秒完成,通过4 4:在2秒完成评估在6.6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒内完成-通过4次中的3次:在2秒内完成-通过4次中的4次:在1.4秒内完成评估在5.8秒内完成使用并行池'local'评估tall表达式:-通过1次中的1次:在0.68秒内完成评估在0.99秒内完成|0 |接受| 3.1641 | 35.522 | 2.9048 | 3.1493 | |
评估高表达式使用并行池“当地”:通过1对1:在0.51秒完成评估在0.79秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.67秒完成,通过2 4:在1.3秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:完成1.1秒-通过3 4:在1.9秒完成,通过4 4:在1.4秒完成评估在5.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.4秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.8秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.1秒内完成-通过3 / 4:在1.8秒内完成-通过4 / 4:在1.4秒内完成评估在5.6秒内完成使用并行池'local'评估tall表达式:-通过1 / 1:在0.63秒内完成评估在0.89秒内完成|0 |接受| 2.9048 | 33.755 | 2.9048 | 2.9048 | 6 |
评估高表达式使用并行池“当地”:通过1对1:在0.45秒完成评估在0.75秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.51秒完成,通过2 4:在1.2秒完成,通过3 4:在2.2秒完成,通过4 4:在1.5秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.49秒完成,通过2 4:完成1.1秒-通过3 4:在1.9秒完成,通过4 4:在1.4秒完成评估在5.6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒内完成-通过4次中的3次:在1.8秒内完成-通过4次中的4次:在1.3秒内完成评估在5.4秒内完成使用并行池'local'评估tall表达式:-通过1次中的1次:在0.68秒内完成评估在0.97秒内完成bbb80 |接受| 2.9522 | 33.362 | 2.9048 | 2.9048 | 7 |
评估高表达式使用并行池“当地”:通过1对1:在0.42秒完成评估在0.71秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:在1.1秒完成,通过3 4:在1.9秒完成,通过4 4:在1.5秒完成评估在5.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.49秒完成,通过2 4:在1.1秒内完成-通过4次中的3次:在1.8秒内完成-通过4次中的4次:在1.4秒内完成评估在5.5秒内完成使用并行池'local'评估tall表达式:-通过1次中的1次:在0.64秒内完成评估在0.9秒内完成bbb90 |接受| 2.9985 | 32.674 | 2.9048 | 2.9048 | 8 |
评估高表达式使用并行池“当地”:通过1对1:在0.43秒完成评估在0.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.56秒完成,通过2 4:完成1.2秒-通过3 4:完成2秒-通过4 4:在1.4秒完成评估在6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.5秒完成评估在5.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒内完成-通过4次中的3次:在1.8秒内完成-通过4次中的4次:在1.6秒内完成评估在5.8秒内完成使用并行池'local'评估tall表达式:-通过1次中的1次:在0.88秒内完成评估在1.2秒内完成| 10 |接受| 3.0185 | 33.922 | 2.9048 | 2.9048 | 10 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.74秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.2秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:完成1.2秒-通过3 4:完成2秒-通过4 4:在1.6秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.73秒完成,通过2 4:在1.2秒完成,通过3 4:完成2秒-通过4 4:在1.5秒完成评估在6.2秒完成评估高表达式使用并行池“当地”:-通过1的1:在0.63秒内完成评估在0.88秒内完成| 11 |接受| 3.2895 | 26.625 | 2.9048 | 2.9048 | 14 |
评估高表达式使用并行池“当地”:通过1对1:在0.48秒完成评估在0.78秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.51秒完成,通过2 4:在1.2秒完成,通过3 4:在1.9秒完成,通过4 4:在1.3秒完成评估在5.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.2秒内完成-通过4次中的3次:在1.8秒内完成-通过4次中的4次:在1.4秒内完成评估在5.5秒内完成使用并行池'local'评估tall表达式:-通过1次中的1次:在0.65秒内完成评估在0.9秒内完成| 12 |接受| 3.4798 | 18.111 | 2.9048 | 2.9049 | 31 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.71秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.43秒完成,通过2 4:在1.2秒内完成-通过4中的3:在2秒内完成-通过4中的4:在1.4秒内完成评估在5.7秒内完成使用并行池'local'评估tall表达式:-通过1中的1:在0.64秒内完成评估在0.91秒内完成| 13 |接受| 3.2248 | 47.436 | 2.9048 | 2.9048 | 1 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.74秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.6秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.57秒完成,通过2 4:在1.1秒完成,通过3 4:在2.6秒完成,通过4 4:在1.6秒完成评估在6.6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.62秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.6秒完成评估在6.1秒完成评估高表达式使用并行池“当地”:-通过1的1:在0.61秒内完成评估在0.88秒内完成| 14 |接受| 3.1498 | 42.062 | 2.9048 | 2.9048 | 3 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.67秒完成,通过2 4:在1.3秒完成,通过3 4:在2.3秒完成,通过4 4:在2.2秒完成评估在7.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒内完成-通过4中的3:在1.8秒内完成-通过4中的4:在1.4秒内完成评估在5.4秒内完成使用并行池'local'评估tall表达式:-通过1中的1:在0.6秒内完成评估在0.86秒内完成| 15 |接受| 2.9048 | 34.3 | 2.9048 | 2.9048 | 6 |
评估高表达式使用并行池“当地”:通过1对1:在0.48秒完成评估在0.78秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:完成1.2秒-通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.43秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒内完成-通过4中的3:在2秒内完成-通过4中的4:在1.4秒内完成评估在5.7秒内完成使用并行池'local'评估tall表达式:-通过1中的1:在0.62秒内完成评估在0.88秒内完成| 16 |接受| 2.9048 | 32.97 | 2.9048 | 2.9048 | 6 |
评估高表达式使用并行池“当地”:通过1对1:在0.43秒完成评估在0.73秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.43秒完成,通过2 4:在1.1秒内完成-通过4次中的3次:在1.8秒内完成-通过4次中的4次:在1.3秒内完成评估在5.5秒内完成使用并行池'local'评估tall表达式:-通过1次中的1次:在0.62秒内完成评估在0.9秒内完成| 17 |接受| 3.1847 | 17.47 | 2.9048 | 2.9048 | 23 |
评估高表达式使用并行池“当地”:通过1对1:在0.43秒完成评估在0.72秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.7秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.68秒完成,通过2 4:完成1.4秒-通过3 4:在1.9秒完成,通过4 4:在1.4秒完成评估在6.3秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒内完成-通过4中的3:在1.8秒内完成-通过4中的4:在1.4秒内完成评估在5.4秒内完成使用并行池'local'评估tall表达式:-通过1中的1:在0.62秒内完成评估在0.93秒内完成| 18 |接受| 3.1817 | 33.346 | 2.9048 | 2.9048 | 4 |
评估高表达式使用并行池“当地”:通过1对1:在0.43秒完成评估在0.72秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:-通过1的1:在0.62秒内完成评估在0.86秒内完成| 19 |错误| NaN | 10.235 | 2.9048 | 2.9048 | 38 |
评估高表达式使用并行池“当地”:通过1对1:在0.47秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.2秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒完成,通过3 4:在1.9秒完成,通过4 4:在1.3秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.43秒完成,通过2 4:在1.1秒内完成-通过4中的3:在1.8秒内完成-通过4中的4:在1.4秒内完成评估在5.5秒内完成使用并行池'local'评估tall表达式:-通过1中的1:在0.63秒内完成评估在0.89秒内完成| 20 |接受| 3.0628 | 32.459 | 2.9048 | 2.9048 | 12 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.48秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.68秒完成,通过2 4:在1.7秒内完成-通过4个中的3个:在2.1秒内完成-通过4个中的4个:在1.4秒内完成评估在6.8秒内完成使用并行池'local'评估tall表达式:-通过1个中的1个:在0.64秒内完成评估在0.9秒内完成|======================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | MinLeafSize | | | |结果日志(1 +损失)运行时| | | (estim(观察) .) | | |======================================================================================| | 21日|接受| 3.1847 | 19.02 | 2.9048 | 2.9048 | | 27岁
评估高表达式使用并行池“当地”:通过1对1:在0.45秒完成评估在0.75秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.47秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.6秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.5秒完成,通过2 4:在1.6秒完成,通过3 4:在2.4秒完成,通过4 4:在1.5秒完成评估在6.8秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒内完成-通过3 / 4:在1.8秒内完成-通过4 / 4:在1.5秒内完成评估在5.6秒内完成使用并行池'local'评估tall表达式:-通过1 / 1:在0.63秒内完成评估在0.89秒内完成| 22 |接受| 3.0185 | 33.933 | 2.9048 | 2.9048 | 9 |
评估高表达式使用并行池“当地”:通过1对1:在0.46秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.43秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:-通过1的1:在0.64秒内完成评估在0.89秒内完成| 23 |接受| 3.0749 | 25.147 | 2.9048 | 2.9048 | 20 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.73秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.42秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.43秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.53秒完成,通过2 4:在1.4秒完成,通过3 4:在1.9秒完成,通过4 4:在1.4秒完成评估在5.9秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒内完成-通过3 / 4:在1.8秒内完成-通过4 / 4:在1.4秒内完成评估在5.5秒内完成使用并行池'local'评估tall表达式:-通过1 / 1:在0.62秒内完成评估在0.88秒内完成| 24 |接受| 3.0628 | 32.764 | 2.9048 | 2.9048 | 11 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.73秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.2秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:-通过1的1:在0.61秒内完成评估在0.87秒内完成| 25 |错误| NaN | 10.294 | 2.9048 | 2.9048 | 34 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.73秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.43秒完成,通过2 4:在1.1秒内完成-通过4次中的3次:在1.8秒内完成-通过4次中的4次:在1.3秒内完成评估在5.4秒内完成使用并行池'local'评估tall表达式:-通过1次中的1次:在0.62秒内完成评估在0.87秒内完成| 26 |接受| 3.1847 | 17.587 | 2.9048 | 2.9048 | 25 |
评估高表达式使用并行池“当地”:通过1对1:在0.45秒完成评估在0.73秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.43秒完成,通过2 4:在1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.3秒完成评估高表达式使用并行池“当地”:-通过1的1:在0.66秒内完成评估在0.96秒内完成| 27 |接受| 3.2895 | 24.867 | 2.9048 | 2.9048 | 16 |
评估高表达式使用并行池“当地”:通过1对1:在0.44秒完成评估在0.74秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.43秒完成,通过2 4:完成1.1秒-通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.5秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.4秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:-通过1的1:在0.6秒内完成评估在0.88秒内完成| 28 |接受| 3.2135 | 24.928 | 2.9048 | 2.9048 | 13 |
评估高表达式使用并行池“当地”:通过1对1:在0.47秒完成评估在0.76秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.45秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.46秒完成,通过2 4:在1.1秒内完成-通过4次中的3次:在1.8秒内完成-通过4次中的4次:在1.3秒内完成评估在5.5秒内完成使用并行池'local'评估tall表达式:-通过1次中的1次:在0.62秒内完成评估在0.87秒内完成| 29 |接受| 3.1847 | 17.582 | 2.9048 | 2.9048 | 21 |
评估高表达式使用并行池“当地”:通过1对1:在0.53秒完成评估在0.81秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.44秒完成,通过2 4:在1.1秒完成,通过3 4:在1.8秒完成,通过4 4:在1.3秒完成评估在5.4秒完成评估高表达式使用并行池“当地”:——通过1 4:在0.43秒完成,通过2 4:在1.1秒内完成-通过4中的3:在1.8秒内完成-通过4中的4:在1.3秒内完成评估在5.4秒内完成使用并行池'local'评估tall表达式:-通过1中的1:在0.63秒内完成评估在0.88秒内完成| 30 |接受| 3.1827 | 17.597 | 2.9048 | 2.9122 | 29 |


__________________________________________________________ 优化完成。达到30分的评价。总函数求值:30总运行时间:882.5668秒。总目标函数评价时间:859.2122最佳观测可行点:MinLeafSize ___________ 6观测目标函数值= 2.9048估计目标函数值= 2.9122函数评价时间= 33.4655最佳估计可行点(根据模型):MinLeafSize ___________ 6估计目标函数值= 2.9122估计函数评价时间= 33.6594使用并行池“local”评价tall表达式:-通过2中的1:在0.26秒完成,通过2 2:在0.26秒完成评估在0.84秒完成评估高表达使用并行池“当地”:——通过1 7:在0.31秒完成,通过2 7:在0.25秒完成,通过3 7:在0.75秒完成,通过4 7:在1.2秒完成,通过5 7:在0.45秒完成,通过6 7:在0.69秒完成,通过7 7:在1.2秒完成评估在5.7秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.28秒完成,通过2 7:在0.24秒完成,通过3 7:在0.75秒完成,通过4 7:在1.2秒完成,通过5 7:在0.46秒完成,通过6 7:在0.67秒完成,通过7 7:在1.2秒完成评估在5.6秒完成评估高表达式使用并行池“当地”:——通过1 7:在0.32秒完成,通过2 7:在0.25秒完成,通过3 7:在0.71秒完成,通过4 7:在1.2秒完成,通过5 7:在0.47秒完成,通过6 7:在0.66秒完成,通过7 7:在1.2秒完成评估在5.6秒完成评估高表达使用并行池“当地”:——通过1 7:在0.29秒完成,通过2 7:在0.25秒完成,通过3 7:在0.73秒完成,通过4 7:在1.2秒完成,通过5 7:在0.46秒完成,通过6 7:在0.68秒完成,通过7 7:在1.2秒完成评估在5.5秒完成评估高表达使用并行池“当地”:——通过1 7:在0.27秒完成,通过2 7:在0.25秒完成,通过3 7:在0.75秒完成,通过4 7:在1.2秒完成,通过5 7:在0.47秒完成,通过6 7:在0.69秒完成,通过7 7:在1.2秒完成评估在5.6秒完成
Mdl = CompactRegressionTree ResponseName: 'Y' CategoricalPredictors: [] ResponseTransform: 'none'属性,方法
FitInfo =结构,没有字段。
HyperparameterOptimizationResults = bayesanoptimization with properties: ObjectiveFcn: @createObjFcn/tallObjFcn变量描述:[3×1 optimizableVariable]选项:[1×1 struct] MinObjective: 2.9048 XAtMinObjective: [1×1 table] minestimatedobjobjective: 2.9122 xatminestimatedobjobjective: [1×1 table] NumObjectiveEvaluations: 30 TotalElapsedTime: 882.5668 NextPoint: [1×1 table] XTrace: [30×1 table] ObjectiveTrace: [30×1 double] ConstraintsTrace: [] UserDataTrace:{30×1细胞}ObjectiveEvaluationTimeTrace:[30×1双]IterationTimeTrace:[30×1双]ErrorTrace:[30×1双]FeasibilityTrace:[30×1逻辑]FeasibilityProbabilityTrace:[30×1双]IndexOfMinimumTrace:[30×1双]ObjectiveMinimumTrace:[30×1双]EstimatedObjectiveMinimumTrace:[30×1双)
输入参数
输出参数
更多关于
提示
算法
参考文献
[1] Breiman, L., J. Friedman, R. Olshen和C. Stone。分类与回归树。博卡拉顿,佛罗里达州:CRC出版社,1984。
[10]陆炜英,“基于无偏变量选择和交互检测的回归树”。Statistica中央研究院, 2002年第12卷,第361-386页。
[3] Loh, W.Y.和Y.S. Shih。分类树的拆分选择方法。Statistica中央研究院, 1997年第7卷,第815-840页。
