改进分类树和回归树
您可以通过设置名称值对来调谐树木fitctree和fitrtree。本节的其余部分介绍了如何确定树的质量,如何确定要设置的名称值对,以及如何控制树的大小。
检查重新提出错误
重新提交错误是响应训练数据与树的差异基于输入训练数据的响应的预测。如果重新提交错误很高,则无法期望树的预测是好的。但是,具有低重新提交错误并不能保证对新数据的良好预测。重新提交错误通常是对新数据上预测错误的过度乐观估计。
分类树重新提交错误
此示例显示如何检查分类树的重新提交错误。
负载Fisher的虹膜数据。
负载fisheriris
使用整个数据集训练一个默认的分类树。
MDL = FITCTREE(MEAS,物种);
检查重新提交错误。
Resuberror = Resubloss(MDL)
resuberror = 0.0200
这棵树几乎正确地分类了所有的Fisher虹膜数据。
交叉验证
为了更好地了解树形图对新数据的预测精度,交叉验证树形图。默认情况下,交叉验证将训练数据随机分成10个部分。它训练了10棵新树,每棵树对应9个数据部分。然后,它检查每棵新树对未包括在训练树中的数据的预测准确性。由于该方法在新数据上对新树进行了测试,因此对结果树的预测精度给出了较好的估计。
交叉验证了回归树
此示例显示了如何检查回归树的重新置特和交叉验证准确性,以基于以下的预测里程预测Carsmall.数据。
加载Carsmall.数据集。考虑加速,排量,马力和重量作为MPG的预测因子。
负载Carsmall.X = [加速位移马力重量];
使用所有观察来展现回归树。
rtree = fitrtree(x,mpg);
计算样本错误。
resuberror = resubLoss (rtree)
resuberror = 4.7188
回归树的重新提交损失是平均误差。生成的值表示树的典型预测误差是关于4.7的平方根,或者超过2的一点。
估计交叉验证MSE。
RNG.'默认';cvrtree = crossval(rtree);cvloss = kfoldloss(cvrtree)
cvloss = 23.5706.
交叉验证的损失几乎为25,这意味着在新数据上的树的典型预测误差约为5.这表明交叉验证的损失通常高于简单的resubStutitut损失。
选择分割预测器选择技术
标准CART算法倾向于选择具有多个层次的连续预测器。有时,这样的选择可能是虚假的,也可能掩盖更重要的预测,具有更少的级别,如分类预测。也就是说,每个节点上的预测器选择过程是有偏差的。此外,标准CART往往会忽略预测因子对和响应之间的重要交互作用。
为了减轻选择偏差并增加重要交互的检测,您可以使用曲率或交互测试的用法使用“PredictorSelection”名称-值对的论点。使用曲率或交互测试具有比标准CART产生更好的预测器重要性估计的额外优势。
该表总结了支持的预测器选择技术。金宝app
| 技术 | “PredictorSelection”价值 |
描述 | 训练速度 | 当指定 |
|---|---|---|---|---|
| 标准推车[1] | 默认 | 选择在所有预测器的所有可能分割中使拆分准则增益最大化的拆分预测器。 |
基线进行比较 | 指定其中任何条件是否为真:
|
| 曲率试验[2][3] | '曲率' |
选择最小化的分割预测器P.- 在每个预测器和响应之间的独立性的Chi-Square测试。 | 可与标准CART比较 | 指定其中任何条件是否为真:
|
| 交互测试[3] | “interaction-curvature” |
选择最小化的分裂预测器P.- 在每个预测器和响应之间的独立性的Chi-Square测试(即,进行曲率测试),并最小化P.每对预测因子和反应之间独立性卡方检验的-值。 | 比标准CART慢,特别是当数据集包含许多预测变量时。 | 指定其中任何条件是否为真:
|
有关预测器选择技术的更多细节:
有关分类树,请参见
PredictorSelection和节点拆分规则。对于回归树,看
PredictorSelection和节点拆分规则。
控制深度或“叶状积”
当您创建决策树时,请考虑它的简单性和预测能力。在训练数据上,有许多叶子的深树通常是非常精确的。然而,不能保证该树在独立测试集上显示相当的精度。一棵枝叶繁茂的树往往会过度训练(或过拟合),它的测试精度往往远远低于它的训练(再替换)精度。相比之下,浅树的训练精度不高。但浅树可能更健壮——它的训练精度可以接近一个代表性的测试集。而且,浅树很容易解释。如果没有足够的数据进行训练和测试,可以通过交叉验证来估计树的准确性。
fitctree和fitrtree有三个名称-值对参数来控制结果决策树的深度:
maxnumsplits.- 分支节点拆分的最大数量是maxnumsplits.每棵树。setmaxnumsplits.得到一棵深树。默认为尺寸(x,1) - 1。minleafsize.- 每个叶子至少有minleafsize.观察。设置小值minleafsize.得到深刻的树木。默认为1。蛋白化- 树中的每个分支节点至少有蛋白化观察。设置小值蛋白化得到深刻的树木。默认为10.。
如果您指定蛋白化和minleafsize.,学习者使用产生较大叶子的树(即较浅的树)的设置:
MinParent = max (MinParentSize 2 * MinLeafSize)
如果你提供maxnumsplits.,软件拆分一棵树,直到满足三个拆分标准之一。
有关控制树深度的替代方法,请参阅修剪。
选择合适的树深度
此示例显示如何控制决策树的深度,以及如何选择适当的深度。
加载电离层数据。
负载电离层
生成一组指数间隔的值10.通过100.表示每个叶节点的最小观察数。
树叶= logspace(1、2、10);
的交叉验证分类树电离层数据。指定使用最小叶子尺寸生长每棵树树叶。
RNG('默认')n = numel(叶);err = zeros(n,1);为t = fitctree(X,Y, Y)“CrossVal”那'上'那......“MinLeafSize”,叶子(n));err(n)= kfoldloss(t);结束情节(树叶、犯错);包含('min叶尺寸');ylabel('交叉验证错误');
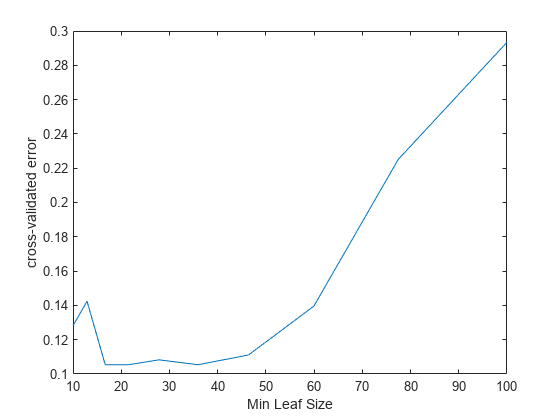
最好的叶子尺寸在约20.和50.每叶的观察。
至少比较近乎最佳树40每个叶子的观察与默认树一起使用10.每个父节点和1每叶观察。
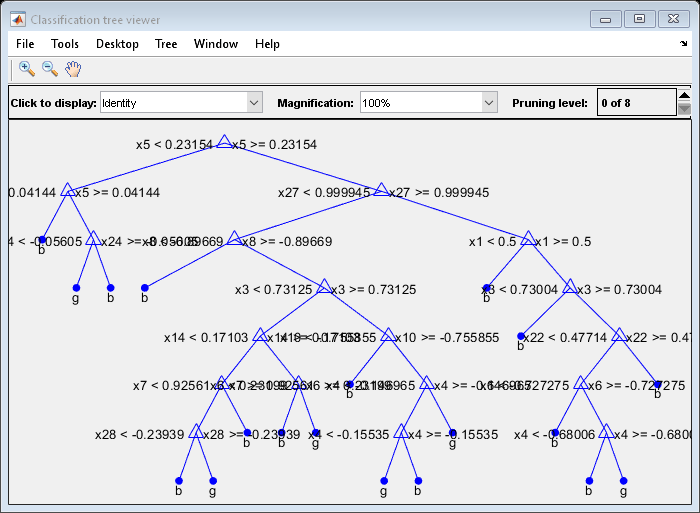
DefaultTree = fitctree (X, Y);视图(DefaultTree,'模式'那“图”)
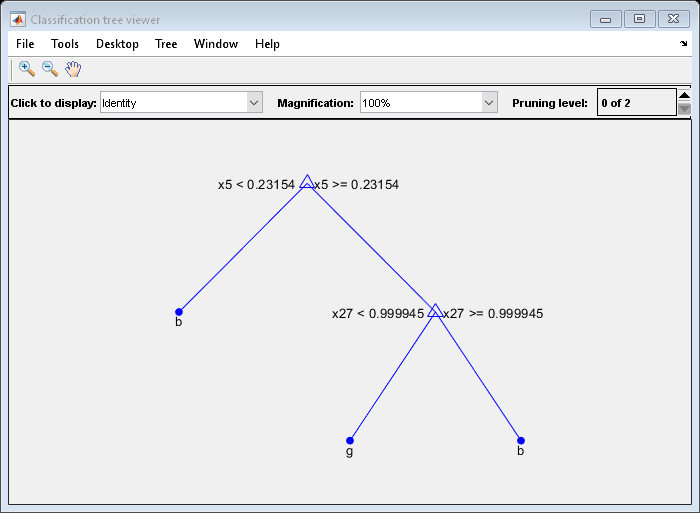
OptimalTree = FitCtree(X,Y,“MinLeafSize”,40);查看(最佳艺术,'模式'那“图”)
resubOpt = resubLoss (OptimalTree);lossOpt = kfoldLoss (crossval (OptimalTree));resubDefault = resubLoss (DefaultTree);lossDefault = kfoldLoss (crossval (DefaultTree));resubOpt、resubDefault lossOpt lossDefault
Resubopt = 0.0883.
重新提交= 0.0114.
LODEOPT = 0.1054.
LOSTDEFAULT = 0.1054.
近最优树要小得多,并提供更高的重新试业误差。然而,它为交叉验证数据提供了类似的准确性。
修剪
修剪通过在同一树枝上合并叶子来优化树深度(叶粉)。控制深度或“叶状积”描述一种选择树的最佳深度的方法。与该部分不同,您无需为每个节点大小生长新树。相反,长出深树,并将其修剪到您选择的级别。
使用命令行的修剪树修剪方法(分类)或修剪方法(回归)。或者,与树查看器交互式修剪树:
查看(树,'模式','图')
要修剪树,树必须包含修剪序列。默认情况下,两者都是fitctree和fitrtree在施工期间计算树的修剪序列。如果你用的树“删除”名称 - 值对设置为'离开',或者如果将树修剪到较小的级别,则树不包含完整的修剪序列。用中生成完整的修剪序列修剪方法(分类)或修剪方法(回归)。
修剪分类树
此示例为该示例创建一个分类树电离层数据,并将其修剪到良好的水平。
加载电离层数据:
负载电离层
构建数据的默认分类树:
树= fitctree(x,y);
在交互式查看器中查看树:
查看(树,'模式'那“图”)
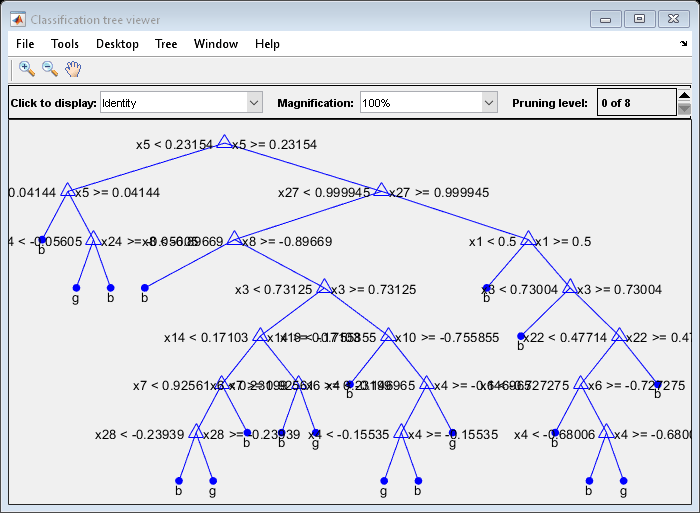
通过最大限度地减少交叉验证损失来找到最佳修剪水平:
[〜,〜,〜,bestlevel] = cvloss(树,......“子树”那“所有”那“TreeSize”那“最小值”)
Bestlevel = 6.
将树修剪到水平6.:
查看(树,'模式'那“图”那“删除”6)
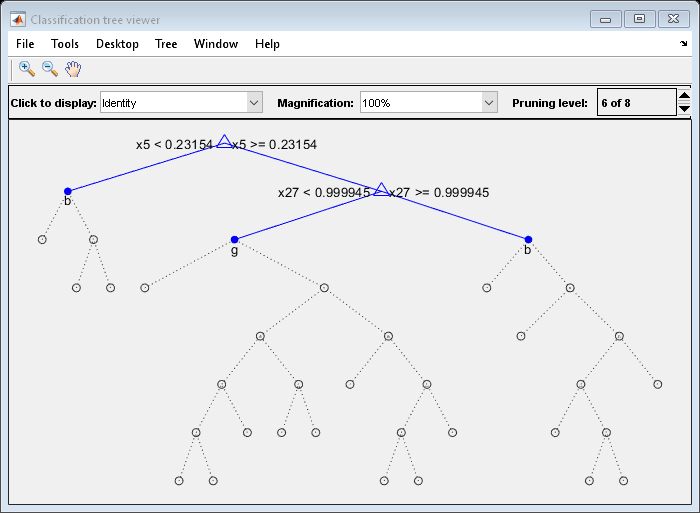
或者,使用交互式窗口修剪树木。
修剪树与“选择适当的树深度”示例中的近最佳树相同。
放“TreeSize”至'se'(默认值)找到树错误从最佳级别不超过错误的最大修剪级别加上一个标准偏差:
[〜,〜,〜,bestlevel] = cvloss(树,“子树”那“所有”)
Bestlevel = 6.
在这种情况下,级别对于任何一个设置都是相同的“TreeSize”。
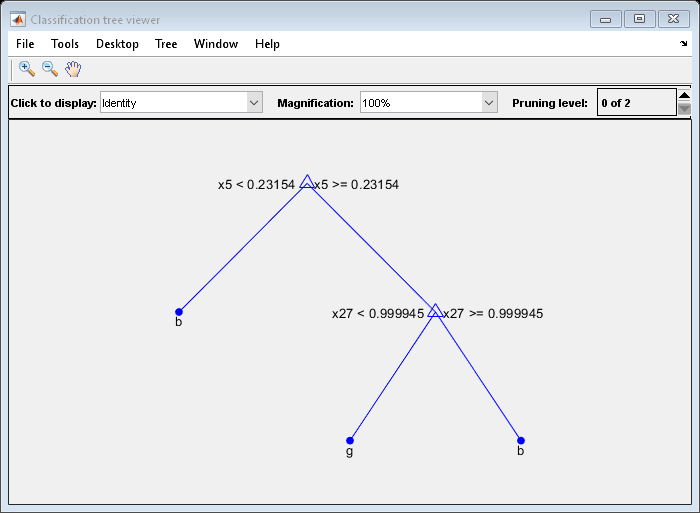
修剪树木以作其他用途:
树= prune(树,'等级'6);查看(树,'模式'那“图”)
参考
布莱曼,L. J. H.弗里德曼,R. A.奥尔申,C. J.斯通。分类和回归树。Boca Raton,FL:Chapman&Hall,1984年。
[2] LOH,W.Y.和Y.S.Shih。“分类树的分离选择方法。”STATISTICA SINICA.,第7卷,1997年,第815-840页。
[3] LOH,W.Y.“具有无偏的变量选择和相互作用检测的回归树。”STATISTICA SINICA.,卷。12,2002,第361-386页。
也可以看看
ClassificationTree.|fitctree|fitrtree|预测(CompactClassificationTree)|预测(Compactregressiontree)|修剪(ClassificationTree)|修剪(回归植物)|回归植物
相关话题
您还可以从以下列表中选择一个网站:
