主要内容
预测的重要性
对回归树预测的重要性估计
句法
Imp = predictorimportance(树)
输出参数
|
作为预测器(列)的数量相同数量的元素数量的行向量 |
例子
估计预测因素重要性
估计数据中所有预测变量的预测值重要性。
加载Carsmall.数据集。
加载Carsmall.
播出一个回归的树MPG.使用加速那气瓶那移位那马力那model_year., 和重量作为预测因素。
x = [加速缸位移马力型号_ year重量];树= fitrtree(x,mpg);
估计所有预测变量的预测值重要性。
Imp = predictorimportance(树)
Imp =1×6.0.0647 0.1068 0.1155 0.1411 0.3348 2.6565
重量是最后的预测因素对里程产生了最大影响。对制作预测的影响最小的预测器是第一个变量,即加速。
预测标志的重要性和代理分裂
估计数据中所有变量的预测值,以及回归树包含代理分割。
加载Carsmall.数据集。
加载Carsmall.
播出一个回归的树MPG.使用加速那气瓶那移位那马力那model_year., 和重量作为预测因素。指定识别代理分裂。
x = [加速缸位移马力型号_ year重量];树= fitrtree(x,mpg,'代理'那'上');
估计所有预测变量的预测值重要性。
Imp = predictorimportance(树)
Imp =1×6.1.0449 2.4560 2.5570 2.5788 2.0832 2.8938
比较偶尔结果估计预测因素重要性那重量仍然对里程产生了最大影响,但气瓶是第四个最重要的预测因素。
无偏见的预测性重视估计
加载Carsmall.数据集。考虑一种模型,该模型预测汽车的平均燃料经济性,仪式,气缸数量,发动机位移,马力,制造商,模型年和重量。考虑气瓶那MFG., 和model_year.作为分类变量。
加载Carsmall.汽缸=分类(圆柱);MFG =分类(CellStr(MFG));model_year =分类(model_year);X =表(加速,圆柱,位移,马力,MFG,......model_year,重量,mpg);
显示分类变量中表示的类别数。
num cinders = numel(类别(圆柱体))
numcylinders = 3
nummfg = numel(类别(MFG))
nummfg = 28.
nummodelyear = numel(类别(model_year))
nummodelyear = 3
因为只有3个类别气瓶和model_year.,标准推车,预测算法更喜欢在这两个变量上分割连续的预测器。
使用整个数据集列出回归树。为了种植无偏的树木,请指定用于分裂预测器的曲率测试的使用。由于数据中存在缺少值,因此指定代理分割的使用。
mdl = fitrtree(x,'mpg'那'预测圈'那'曲率'那'代理'那'上');
通过在每个预测器上求解风险的变化来估计预测值重要值,并将总和除以分支节点的数量。使用条形图比较估计值。
Imp = predictorimportance(mdl);数字;酒吧(IMP);标题('预测重点估计');ylabel('估计');Xlabel('预测器');H = GCA;h.xticklabel = mdl.predictornames;H.xticklabelrotation = 45;H.TicklabelInterpreter =.'没有任何';
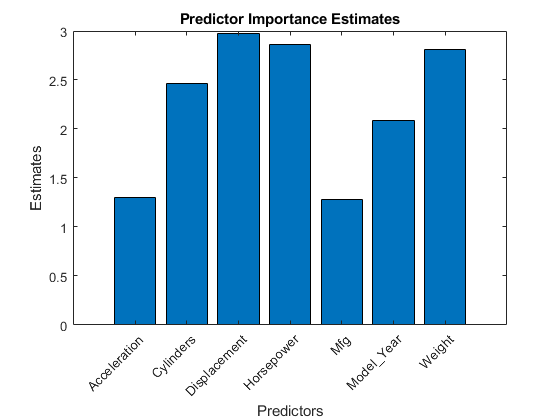
在这种情况下,移位是最重要的预测因素,其次是马力。
更多关于
您还可以从以下列表中选择一个网站:
