oobPermutedPredictorImportance
通过对回归树随机森林的包外预测器观察的排列来估计预测器的重要性
描述
小鬼= oobPermutedPredictorImportance (Mdl)Mdl.Mdl必须是一个RegressionBaggedEnsemble模型对象。
输入参数
输出参数
例子
评估预测因素的重要性
加载carsmall数据集。考虑一个模型,它可以预测一辆汽车的平均燃油经济性,该模型给出了汽车的加速度、汽缸数、发动机排量、马力、制造商、车型年份和重量。考虑气缸,制造行业,Model_Year作为分类变量。
负载carsmall气缸=分类(缸);及时通知=分类(cellstr (Mfg));Model_Year =分类(Model_Year);X =表(加速、气缸、排量、马力、制造行业,...Model_Year、重量、MPG);
您可以使用整个数据集训练一个由500棵回归树组成的随机森林。
Mdl = fitrensemble (X,“英里”,“方法”,“包”,“NumLearningCycles”, 500);
fitrensemble使用默认的模板树对象templateTree ()作为一个弱学习者“方法”是“包”.在本例中,为了再现性,请指定“重现”,真的当你创建一个树模板对象,然后使用对象作为弱学习器。
rng (“默认”)%的再现性t = templateTree (“复制”,真正的);%用于随机预测器选择的重现性Mdl = fitrensemble (X,“英里”,“方法”,“包”,“NumLearningCycles”, 500,“学习者”t);
Mdl是一个RegressionBaggedEnsemble模型。
通过排列出包外的观察来估计预测器的重要性。用条形图比较估计值。
小鬼= oobPermutedPredictorImportance (Mdl);图;酒吧(imp);标题(“out - bag perised Predictor Importance Estimates”);ylabel (“估计”);包含(“预测”);甘氨胆酸h =;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;
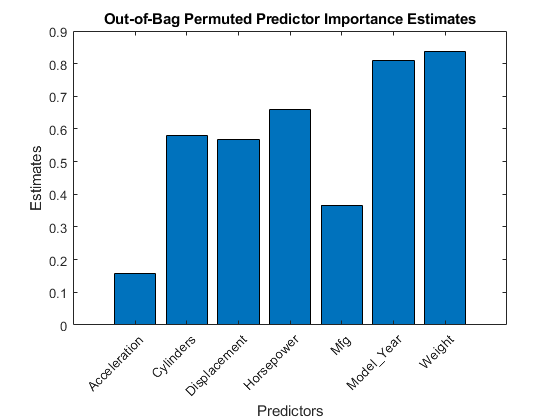
小鬼是预测器重要性估计的1 × 7向量。较大的值表示对预测有较大影响的预测器。在这种情况下,重量最重要的预测因素是什么Model_Year.
使用并行计算的预测器重要性的无偏估计
加载carsmall数据集。考虑一个模型,它可以预测一辆汽车的平均燃油经济性,该模型给出了汽车的加速度、汽缸数、发动机排量、马力、制造商、车型年份和重量。考虑气缸,制造行业,Model_Year作为分类变量。
负载carsmall气缸=分类(缸);及时通知=分类(cellstr (Mfg));Model_Year =分类(Model_Year);X =表(加速、气缸、排量、马力、制造行业,...Model_Year、重量、MPG);
显示类别变量中表示的类别数量。
numCylinders =元素个数(类别(气缸))
numCylinders = 3
numMfg =元素个数(类别(有限公司))
numMfg = 28
numModelYear =元素个数(类别(Model_Year))
numModelYear = 3
因为只有3个类别气缸和Model_Year在标准CART中,预测器分割算法更喜欢分割连续预测器而不是这两个变量。
使用整个数据集训练一个由500棵回归树组成的随机森林。要种植无偏的树,指定使用曲率测试的分裂预测器。由于数据中缺少值,请指定代理拆分的用法。为了重现随机的预测器选择,使用rng并指定“重现”,真的.
rng (“默认”);%的再现性t = templateTree (“PredictorSelection”,“弯曲”,“代孕”,“上”,...“复制”,真正的);%用于随机预测器选择的重现性Mdl = fitrensemble (X,“英里”,“方法”,“包”,“NumLearningCycles”, 500,...“学习者”t);
通过排列出包外的观察来估计预测器的重要性。并行执行计算。
选择= statset (“UseParallel”,真正的);小鬼= oobPermutedPredictorImportance (Mdl,“选项”、选择);
使用“local”配置文件启动并行池(parpool)…连接到并行池(工作人员数量:6)。
用条形图比较估计值。
图;酒吧(imp);标题(“out - bag perised Predictor Importance Estimates”);ylabel (“估计”);包含(“预测”);甘氨胆酸h =;h.XTickLabel = Mdl.PredictorNames;h.XTickLabelRotation = 45;h.TickLabelInterpreter =“没有”;

在这种情况下,Model_Year最重要的预测因素是什么气缸.将这些结果与评估预测因素的重要性.
更多关于
提示
当种植随机森林使用fitrensemble:
标准CART倾向于选择包含许多不同值(如连续变量)的分离预测因子,而不是包含很少不同值(如分类变量)的分离预测因子[3].如果预测器数据集是异构的,或者如果有比其他变量具有相对较少的不同值的预测器,那么考虑指定曲率或交互测试。
使用标准CART生长的树木对预测变量相互作用不敏感。此外,与交互测试的应用相比,在存在许多无关的预测因子时,这种树不太可能识别出重要的变量。因此,为了解释预测变量之间的交互作用,并在存在许多不相关变量的情况下识别重要变量,指定交互作用检验[2].
如果训练数据包含许多预测器,而您想要分析预测器的重要性,那么请指定
“NumVariablesToSample”的templateTree函数作为“所有”对于合奏的树型学习者。否则,软件可能不会选择一些预测因子,低估它们的重要性。
有关详细信息,请参见templateTree和选择分裂预测器选择技术.
参考文献
[1] Breiman, L., J. Friedman, R. Olshen, C. Stone。分类与回归树.佛罗里达州博卡拉顿:CRC出版社,1984。
[2] Loh, W.Y., <具有无偏变量选择和交互检测的回归树>Statistica中央研究院, 2002年第12卷,第361-386页。
Loh w.y y and Y.S. Shih分类树的分裂选择方法Statistica中央研究院, 1997年第7卷,第815-840页。
扩展功能
你也可以从以下列表中选择一个网站:
