fitrensemble
适合学习者的回归集合
语法
描述
Mdl= fitrensemble (TBL.,responsevarname.)Mdl),其中包含使用LSBoost和表中的预测器和响应数据增强100棵回归树的结果TBL..responsevarname.中是响应变量的名称吗TBL..
例子
火车回归合奏
创建一个回归集成,在给定气缸数量、气缸所取代的体积、马力和重量的情况下,预测汽车的燃油经济性。然后,使用较少的预测器训练另一个集合。比较集成的样本内预测精度。
加载Carsmall.数据集。将训练中使用的变量存储在一个表中。
负载Carsmall.台=表(汽缸、排量、马力、重量、MPG);
训练回归集合。
Mdl1 = fitrensemble(资源描述,“英里”);
Mdl1是一个RegressionEnsemble模型。一些显著的特点Mdl1是:
集成聚合算法为
“LSBoost”.由于集成聚合方法是一种增强算法,回归树最多允许10次分裂组成集成。
一百棵树组成一个整体。
因为英里/加仑是MATLAB®Workspace中的变量,可以通过输入
MDL1 = FITRESEMBLE(TBL,MPG);
使用训练过的回归集合来预测一辆排量为200立方英寸、马力为150马力、重量为3000磅的四缸汽车的燃油经济性。
pMPG = predict(Mdl1,[4 200 150 3000])
pMPG = 25.6467
使用中的所有预测器训练一个新的集合TBL.除了位移.
公式='MPG ~气缸+马力+重量';Mdl2 = fitrensemble(资源描述、公式);
比较两者的再取代mseMdl1和Mdl2.
mse1 = resubLoss (Mdl1)
mse1 = 0.3096
mse2 = resubLoss (Mdl2)
mse2 = 0.5861
所有预测因子列车的集合的样本MSE是较低的。
通过排放数字预测值值加速培训
使用培训促进回归树的集合fitrensemble.减少训练时间通过指定“NumBins”二进制数值预测器的名称-值对参数。在训练之后,您可以通过使用毕业生训练模型的性质和离散化函数。
生成一个样本数据集。
rng (“默认”)%的再现性n = 1E6;x1 = randi([ - 1,5],[n,1]);x2 = randi([5,10],[n,1]);x3 = randi([0,5],[n,1]);x4 = randi([1,10],[n,1]);x = [x1 x2 x3 x4];y = x1 + x2 + x3 + x4 + normrnd(0,1,[n,1]);
使用最小二乘增强来训练增强回归树集合(LSBoost,默认值)。为函数计时,以便进行比较。
tic Mdl1 = fitrensemble(X,y);TOC.
运行时间为78.662954秒。
通过使用加速培训“NumBins”名称-值对的论点。如果您指定了“NumBins”值作为一个正整数标量,然后软件将每个数值预测器放入指定数量的等概率容器中,然后在容器指数上生长树,而不是原始数据。该软件不会分类预测。
tic Mdl2 = fitrensemble(X,y,“NumBins”,50);TOC.
运行时间为43.353208秒。
当您使用装箱的数据而不是原始数据时,这个过程要快两倍。请注意,运行时间可能因操作系统而异。
比较回归误差的重新替代。
rsLoss = resubLoss (Mdl1)
RSLOSS = 1.0134.
rsLoss2 = resubLoss (Mdl2)
rsLoss2 = 1.0133
在该示例中,分纳预测值值可降低培训时间而无需显着损失准确性。通常,当您在此示例中具有像这样的大数据设置时,使用分箱选项速度升级培训,但导致精度降低。如果要进一步降低培训时间,请指定较少数量的垃圾箱。
通过使用使用的重现Binned预测测量数据毕业生训练模型的性质和离散化函数。
x = mdl2.x;%预测仪数据xbinned = zeros(尺寸(x));边缘= mdl2.binedges;找到被分类的预测器的指数。idxNumeric =找到(~ cellfun (@isempty边缘));如果iscolumn(idxNumeric) idxNumeric = idxNumeric';结尾为j = idxNumeric x = x (:,j);%如果x是一个表,则将x转换为数组。如果istable(x)x = table2array(x);结尾使用离散函数将%组X进入箱。xbinned =离散化(x,[无穷;边缘{};正]);Xbinned (:, j) = Xbinned;结尾
Xbinned包含单位,范围为1到箱数,用于数字预测器。Xbinned价值是0分类预测。如果X包含南S,然后对应的Xbinned价值是南年代。
估计增强系综的泛化误差
估计增强回归树集合的泛化误差。
加载Carsmall.数据集。选择气缸的数量,由气缸取代的体积,马力,和重量作为燃料经济性的预测。
负载Carsmall.x = [气瓶位移马力重量];
使用10倍交叉验证交叉验证回归树的集合。使用决策树模板,指定每棵树只应为拆分一次。
rng (1);%的再现性t = templatetree(“MaxNumSplits”,1);mdl = fitrensemble(x,mpg,“学习者”t“CrossVal”,'在');
Mdl是一个RegressionPartitionedEnsemble模型。
绘制累积的、10倍交叉验证的均方误差(MSE)。显示估计的集合泛化误差。
kflc = kfoldLoss (Mdl,“模式”,'累积');图;情节(kflc);ylabel (“旨在MSE 10倍”);Xlabel(“学习周期”);

estGenError = kflc(结束)
estGenError = 26.2356
kfoldLoss默认情况下返回泛化错误。但是,绘制累积损失使您可以监控随着弱学习器在集成中积累而发生的损失变化。
在积累了大约30个弱学习者后,该集成的MSE达到了23.5左右。
如果您对集合的泛化误差感到满意,那么,为了创建一个预测模型,使用除了交叉验证之外的所有设置再次训练集合。然而,调优超参数(如每棵树的最大决策分裂数和学习周期数)是一个很好的实践。
优化回归合奏
此示例显示如何自动优化超级参数fitrensemble.示例使用Carsmall.数据。
加载数据。
负载Carsmall.
通过使用自动超参数优化,可以找到最小化五倍交叉验证损失的超参数。
Mdl = fitrensemble (MPG(功率、重量),“OptimizeHyperparameters”,“汽车”)
在此示例中,为了重现性,设置随机种子并使用“expected-improvement-plus”采集功能。此外,为随机森林算法的再现性,指定“复制”名称 - 值对参数为真正的树的学习者。
rng (“默认”) t = templateTree(“复制”,真正的);Mdl = fitrensemble (MPG(功率、重量),“OptimizeHyperparameters”,“汽车”,“学习者”t...“HyperparameterOptimizationOptions”结构(“AcquisitionFunctionName”,“expected-improvement-plus”))
|===================================================================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | |方法NumLearningC - | LearnRate | MinLeafSize | | | |结果日志(1 +损失)运行时| |(观察)| (estim) | |永昌龙 | | | |===================================================================================================================================| | 最好1 | | 2.9718 | 9.4175 | 2.9718 | 2.9718 |包| 413 | - | 1|
|2 |接受|6.2619 |1.5813 |2.9718 |3.6127 |lsboost |57 |0.0016067 | 6 |
| 3 |接受| 2.9975 | 0.77235 | 2.9718 | 2.9847 |包| 32 | - | 2 |
| 4 |接受| 4.1897 | 1.2345 | 2.9718 | 2.9712 |包| 55 | - | 40 |
| 5 |接受| 6.3321 | 1.3497 | 2.9718 | 2.9707 | LSBoost | 55 | 0.001005 | 2 |
|6 |最好的2.9689 |0.88428 |2.9689 |2.9698 |袋子|39 |- | 1 |
| 7 |接受| 3.0113 | 0.53827 | 2.9689 | 2.9833 |包| 23 | - | 1 |
|8 |接受|2.9823 |10.275 |2.9689 |2.9832 |袋子|496 |- | 1 |
| 9 |接受| 4.1881 | 0.29182 | 2.9689 | 2.9833 | LSBoost | 12 | 0.883 | 50 |
| 10 |接受| 3.6685 | 8.304 | 2.9689 | 2.9832 | LSBoost | 398 | 0.97772 | 1 |
|11 |接受|3.4414 |0.36526 |2.9689 |2.9833 |lsboost |14 |0.13404 | 1 |
| 12 |接受| 4.1881 | 1.7024 | 2.9689 | 2.9832 | LSBoost | 84 | 0.079388 | 49 |
| 13 |接受| 5.6912 | 0.63921 | 2.9689 | 2.9832 | LSBoost | 27 | 0.014186 | 1 |
| 14 |接受| 3.5833 | 4.2041 | 2.9689 | 2.9831 | LSBoost | 198 | 0.29995 | 3 |
| 15 |接受| 5.7781 | 0.85679 | 2.9689 | 2.9829 | LSBoost | 37 | 0.010476 | 50 |
| 16 |接受| 6.4093 | 0.38185 | 2.9689 | 2.9828 | LSBoost | 18 | 0.0010034 | 50 |
| 17 |接受| 4.1881 | 2.0801 | 2.9689 | 2.9827 | LSBoost | 100 | 0.26658 | 50 |
| 18 |接受| 5.2307 | 0.30503 | 2.9689 | 2.983 | LSBoost | 12 | 0.051319 | 4 |
| 19 |接受| 5.9165 | 1.3811 | 2.9689 | 2.9835 | LSBoost | 59 | 0.0045433 | 1 |
|20 |接受|3.533 |1.3538 |2.9689 |2.9829 |lsboost |60 |0.3064 | 1 |
|===================================================================================================================================| | Iter | Eval |目的:|目标|Bestsofar |Bestsofar |方法|numlearningc- |学习|minleafsize || | result | log(1+loss) | runtime | (observed) | (estim.) | | ycles | | | |===================================================================================================================================| | 21 | Accept | 6.3754 | 0.27538 | 2.9689 | 2.9829 | LSBoost | 10 | 0.0037054 | 50 |
| 22 |接受| 5.7958 | 0.31299 | 2.9689 | 2.9827 | LSBoost | 13 | 0.028703 | 50 |
|23 |接受|3.2511 |0.5558 |2.9689 |2.9828 |lsboost |23 |0.57224 | 5 |
|24 |接受|3.5298 |7.504 |2.9689 |2.9726 |lsboost |367 |0.56349 | 1 |
| 25 |最佳| 2.9188 | 4.3433 | 2.9188 | 2.9219 |包| 216 | - | 2 |
| 26 |接受| 3.5858 | 0.25552 | 2.9188 | 2.9586 | LSBoost | 10 | 0.67582 | 1 |
| 27 |接受| 2.9384 | 10.206 | 2.9188 | 2.9444 |包| 500 | - | 2 |
| 28 |接受| 2.9322 | 11.78 | 2.9188 | 2.939 |包| 499 | - | 2 |
| 29 |接受| 2.937 | 11.726 | 2.9188 | 2.9378 |包| 498 | - | 2 |
|30 |接受|3.6531 |0.31678 |2.9188 |2.9379 |lsboost |11 |0.13843 | 11 |

__________________________________________________________ 优化完成。maxobjective达到30个。总函数计算:30总运行时间:141.9069秒。总目标函数评价时间:95.1937方法NumLearningCycles LearnRate MinLeafSize ______ _________________ _________ ___________ Bag 216 NaN 2观测目标函数值= 2.9188估计目标函数值= 2.9466函数评估时间= 4.3433最佳估计可行点(根据模型):方法NumLearningCycles LearnRate MinLeafSize ______ _________________ _________ ___________ Bag 500 NaN 2估计目标函数值= 2.9379估计函数评估时间= 11.0122
Mdl = RegressionBaggedEnsemble ResponseName:‘Y’CategoricalPredictors: [] ResponseTransform:“没有一个”NumObservations: 94 HyperparameterOptimizationResults:[1×1 BayesianOptimization] NumTrained: 500方法:“袋子”LearnerNames:{‘树’}ReasonForTermination:“终止通常在完成训练周期的请求的数量。FitInfo: [] FitInfoDescription: 'None'正则化:[]FResample: 1 Replace: 1 UseObsForLearner: [94×500 logical]属性,方法
优化搜索了回归的方法(袋和LSBoost),在NumLearningCycles,在学习为LSBoost,和树之上的学习者MinLeafSize.输出是具有最小交叉验证损失估计的集成回归。
使用交叉验证优化回归集合
创建具有令人满意的预测性能的提升回归树的合奏的一种方法是使用交叉验证调整决策树复杂程度。在寻找最佳复杂性级别的同时,调整学习速率,以最小化学习周期的数量。
这个示例通过使用交叉验证选项“KFold”名称值对参数)和kfoldLoss函数。或者,您可以使用“OptimizeHyperparameters”名称-值对参数自动优化超参数。看到优化回归合奏.
加载Carsmall.数据集。选择气缸的数量,由气缸取代的体积,马力,和重量作为燃料经济性的预测。
负载Carsmall.台=表(汽缸、排量、马力、重量、MPG);
用于升压回归树的树深度控制器的默认值是:
10为MaxNumSplits.5为MinLeafSize10为MinParentSize
为了寻找最优的树复杂度水平:
交叉验证一组集成。指数级增加后续集成的树复杂度,从决策树桩(一次拆分)到最多n- 1分裂。n为样本量。另外,每个集合的学习率在0.1到1之间变化。
估计每个集合的交叉验证均方误差(MSE)。
用于树木复杂度水平 , ,通过绘制它们与学习周期数的关系,比较集成的累积的、交叉验证的MSE。在同一个图上为每个学习率绘制单独的曲线。
选择实现最小MSE的曲线,并注意相应的学习周期和学习率。
交叉验证一个深度回归树和一个树桩。因为数据包含丢失的值,所以使用代理分割。这些回归树可以作为基准。
rng (1)%的再现性MdlDeep = fitrtree(资源描述,“英里”,“CrossVal”,'在','mergeleaves','离开',...'迷人',1,'代理','在');MdlStump = fitrtree(资源描述,“英里”,“MaxNumSplits”,1,“CrossVal”,'在',...'代理','在');
使用5倍交叉验证对150棵增强回归树进行交叉验证。使用树模板:
使用序列中的值改变分割的最大数目 .米是这样的, 不比n- 1。
打开代理劈叉。
对于每个变量,使用集合{0.1,0.25,0.5,1}中的每个值来调整学习率。
n =大小(1台);M =底(log2(n - 1));learnRate = [0.1 0.25 0.5 1];numLR =元素个数(learnRate);maxNumSplits = 2。^ (0:m);numMNS =元素个数(maxNumSplits);numTrees = 150;Mdl =细胞(numMNS numLR);为k = 1: numLR为j = 1:nummns t = templatetree(“MaxNumSplits”maxNumSplits (j),'代理','在');mdl {j,k} = fitrensemble(tbl,“英里”,“NumLearningCycles”,numtrees,...“学习者”t“KFold”5,“LearnRate”, learnRate (k));结尾结尾
估计每个集合的累积的、交叉验证的MSE。
kflall = @(x)kfoldloss(x,“模式”,'累积');errorCell = cellfun (Mdl kflAll,'制服'、假);[numTrees nummel (maxnumsplit) nummel (learnRate)]);errorDeep = kfoldLoss (MdlDeep);errorStump = kfoldLoss (MdlStump);
绘制交叉验证的MSE在集合中树的数量增加时的行为。在同一图上绘制关于学习率的曲线,并根据不同的树复杂度水平绘制不同的图。选择要绘制的树复杂度级别的子集。
mnsPlot = [1 round(nummel (maxnumsplents)/2) nummel (maxnumsplents)];图;为k = 1:3次要情节(2 2 k)情节(挤压(错误(:,mnsPlot (k):)),'行宽'2)轴紧的持有在甘氨胆酸h =;情节(h。XLim,[errorDeep errorDeep],“。b”,'行宽', 2)情节(h。XLim,[errorStump errorStump],'-.r','行宽',2)绘图(H.xlim,min(min(error(错误(minsplot(k),:))))。* [1 1],“——k”)H.YLIM = [10 50];Xlabel('树的数量') ylabel (“旨在MSE”)标题(Sprintf(“MaxNumSplits = % 0.3 g”maxNumSplits (mnsPlot (k))))从结尾hL =传奇([cellstr num2str (learnRate ','学习率= %0.2f'));...'深树';“树桩”;'闵。MSE']);hL.Position (1) = 0.6;
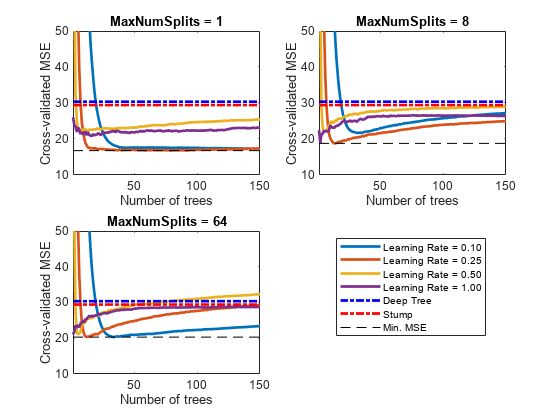
每个曲线包含在集合中最佳树木的最佳交叉验证的MSE。
确定总体上最低MSE的最大分裂数,树木数量和学习率。
[minErr, minErrIdxLin] = min(错误(:));[idxNumTrees, idxMNS idxLR] = ind2sub(大小(错误),minErrIdxLin);流(“\ nMin。MSE = % 0.5 f ',Minerr)
闵。MSE = 16.77593
流(“\ nOptimal参数值:\ nNum。树= % d ', idxNumTrees);
最优参数值:Num. Trees = 78
流('\ nmaxnumpartitions = %d\nLearning Rate = %0.2f\n',...maxNumSplits (idxMNS) learnRate (idxLR))
maxnumsplits = 1学习率= 0.25
建立一个基于最优超参数和整个训练集的预测集成。
tFinal = templateTree (“MaxNumSplits”maxNumSplits (idxMNS),'代理','在');MdlFinal = fitrensemble(资源描述,“英里”,“NumLearningCycles”idxNumTrees,...“学习者”,tfinal,“LearnRate”learnRate (idxLR))
MdlFinal = RegressionEnsemble PredictorNames: {' cylinder ' ' 'Displacement' ' '马力' '重量'}ResponseName: 'MPG' CategoricalPredictors: [] ResponseTransform: 'none' NumObservations: 94 NumTrained: 78 Method: 'LSBoost' LearnerNames: {'Tree'} ReasonForTermination: '在完成请求的训练周期数后正常终止。'FitInfo: [78×1 double] FitInfoDescription: {2×1 cell}正则化:[]属性,方法
MdlFinal是一个RegressionEnsemble.要预测一辆汽车的燃油经济性,根据它的汽缸数量,汽缸所取代的体积,马力和重量,你可以通过预测数据和MdlFinal来预测.
而不是使用交叉验证选项手动搜索最佳值(“KFold”)和kfoldLoss函数,则可以使用“OptimizeHyperparameters”名称-值对的论点。当您指定时“OptimizeHyperparameters”,软件使用贝叶斯优化自动查找最佳参数。通过使用获得的最佳值“OptimizeHyperparameters”可以不同于使用手动搜索获得的。
t = templatetree('代理','在');mdl = fitrensemble(资源描述,“英里”,“学习者”t...“OptimizeHyperparameters”, {“NumLearningCycles”,“LearnRate”,“MaxNumSplits”})
|====================================================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | NumLearningC - | LearnRate | MaxNumSplits | | | |结果日志(1 +损失)运行时| |(观察)| (estim) |永昌龙 | | | |====================================================================================================================| | 最好1 | | 3.3974 | 0.67187 | 3.3974 | 3.3974 | 26 | 0.072054 | 3 |
| 2 |接受| 6.0976 | 4.2306 | 3.3974 | 3.5568 | 170 | 0.0010295 | 70 |
| 3 |最佳| 3.2885 | 6.5786 | 3.2885 | 3.2887 | 273 | 0.61026 | 6 |
| 4 |接受| 6.1839 | 1.8593 | 3.2885 | 3.2885 | 80 | 0.0016871 | 1 |
| 5 | Best | 3.1395 | 0.26569 | 3.1395 | 3.1394 | 10 | 0.21358 | 2 |
|6 |接受|3.5817 |0.28615 |3.1395 |3.303 |10 |0.1666 |1 |
|7 |最好的3.1268 |0.31144 |3.1268 |3.2143 |10 |0.99816 |3 |
|8 |最好的3.0582 |0.31361 |3.0582 |3.0927 |10 |0.97817 |3 |
| 9 | Best | 3.0005 | 0.3115 | 3.0005 | 3.0084 | 10 | 0.38895 | 3 |
| 10 | Best | 2.9744 | 0.29252 | 2.9744 | 2.9894 | 10 | 0.39702 | 3 |
| 11 |最佳| 2.9704 | 0.26561 | 2.9704 | 2.9873 | 10 | 0.34289 | 5 |
| 12 |接受| 3.2964 | 0.27885 | 2.9704 | 2.9628 | 10 | 0.91391 | 98 |
| 13 |接受| 3.2164 | 0.32053 | 2.9704 | 2.9629 | 10 | 0.20551 | 20 |
| 14 |接受| 3.2572 | 0.30051 | 2.9704 | 2.9883 | 10 | 0.95514 | 13 |
| 15 |最佳| 2.9374 | 0.28596 | 2.9374 | 2.9544 | 10 | 0.28703 | 5 |
|16 |接受|2.9642 |0.26404 |2.9374 |2.9571 |10 |0.26332 |5 |
|17 |接受|2.9396 |0.34495 |2.9374 |2.9528 |10 |0.28684 |5 |
|18 |接受|2.9659 |0.29281 |2.9374 |2.9549 |10 |0.25925 |5 |
| 19 |接受| 2.9378 | 0.29386 | 2.9374 | 2.9532 | 10 | 0.34163 | 4 |
| 20 |接受| 5.8728 | 0.33079 | 2.9374 | 2.9514 | 10 | 0.028687 | 98 |
|====================================================================================================================| | Iter | Eval |目的:| |目的BestSoFar | BestSoFar | NumLearningC - | LearnRate | MaxNumSplits | | | |结果日志(1 +损失)运行时| |(观察)| (estim) |永昌龙 | | | |====================================================================================================================| | 21日|接受| 3.1123 | 0.30967 | 2.9374 | 2.951 | 10 | 0.95322 | 1 |
| 22 |接受| 3.1405 | 0.27687 | 2.9374 | 2.9423 | 10 | 0.20618 | 6 |
| 23 |接受| 2.9494 | 0.59109 | 2.9374 | 2.9415 | 24 | 0.30598 | 5 |
| 24 | Best | 2.906 | 0.28183 | 2.906 | 2.9064 | 10 | 0.32881 | 1 |
| 25 |接受| 2.9436 | 0.30565 | 2.906 | 2.9222 | 10 | 0.31006 | 2 |
| 26 |最佳| 2.8822 | 0.25146 | 2.8822 | 2.8912 | 10 | 0.36677 | 1 |
|27 |接受|2.9123 |0.29838 |2.8822 |2.8952 |10 |0.39598 |1 |
| 28 |接受| 4.6089 | 0.28759 | 2.8822 | 2.901 | 10 | 0.093135 | 98 |
|29 |接受|2.8917 |0.37785 |2.8822 |2.9009 |15 |0.33056 |1 |
| 30 |接受| 2.9289 | 1.1702 | 2.8822 | 2.9008 | 50 | 0.14154 | 1 |

__________________________________________________________ 优化完成。maxobjective达到30个。总功能评估:全部30次零售时间:60.5324秒。客观总函数评估时间:22.2498最佳观察到的可行点:Num / interningCycles LableRate MaxnumSplits _________ _____________ 10 0.36677 1观察到的目标函数值= 2.8822估计目标函数值= 2.9008函数评估时间= 0.25146最佳估计可行点(根据型号)MaxnumSplits _________________ _________ _____________ 10 0.36677 1估计目标函数值= 2.9008估计函数评估时间= 0.291
mdl = RegressionEnsemble PredictorNames: {'Cylinders' ' 'Displacement' ' '马力' 'Weight'} ResponseName: 'MPG' CategoricalPredictors: [] ResponseTransform: 'none' NumObservations: 94 HyperparameterOptimizationResults: [1×1 bayesanoptimization] NumTrained: 10 Method: 'LSBoost' LearnerNames: {'Tree'} ReasonForTermination:“在完成要求的培训周期数后正常终止。”FitInfo: [10×1 double] FitInfoDescription: {2×1 cell}正则化:[]属性,方法
输入参数
输出参数
提示
NumLearningCycles从几十个到几千个不等。通常,一个具有良好预测能力的集成需要几百到几千个较弱的学习者。然而,您不需要一次训练那么多周期的合奏。你可以从培养几十个学习者开始,检查合奏表演,然后,如果有必要的话,用它来训练更多的弱学习者的简历.合奏性能取决于集合设置和弱学习者的设置。也就是说,如果使用默认参数指定弱的学习者,则集合可以表现不佳。因此,与集合设置一样,使用模板调整弱学习者的参数是好的做法,并选择最小化泛化误差的值。
如果指定要使用重新采用
重新取样,则对整个数据集进行重新采样是一种良好的实践。也就是说,使用默认设置1为Fresample..在训练模型之后,您可以生成C/ c++代码来预测对新数据的响应。生成C/ c++代码需要MATLAB编码器™.有关详细信息,请参见代码生成简介.
算法
集成聚合算法的详细信息请参见整体算法.
如果您指定
'方法','lsboost',然后软件会在默认情况下生成浅决策树。属性可以调整树的深度MaxNumSplits,MinLeafSize,MinParentSize名称-值对参数使用templateTree.对于双核系统及以上,
fitrensemble使用英特尔并行训练®线程构建块(TBB)。关于Intel TBB的详细介绍请参见https://software.intel.com/en-us/intel-tbb..
参考文献
[1] Breiman, L.《套袋预测》。机器学习.卷。26,pp。123-140,1996。
[2]布雷曼,L.《随机森林》。机器学习.第45卷,第5-32页,2001。
弗洛因德,Y.和R. E. Schapire。在线学习的决策理论推广及其在助推中的应用J.计算机与系统科学,第55卷,119-139页,1997。
[4]弗里德曼,J。“贪婪函数近似:梯度升压机。”统计数据,第29卷,第5期,第1189-1232页,2001。
Hastie, T., R. Tibshirani, J. Friedman。统计学习的要素第2008年纽约Springer,纽约赛版。
扩展功能
您还可以从以下列表中选择一个网站:
