选择随机林的预测器
这个示例展示了如何在生长随机回归树森林时为您的数据集选择适当的分割预测器选择技术。这个示例还展示了如何决定在训练数据中包含哪些最重要的预测因子。
加载和预处理数据
加载carbig数据集。考虑一个模型,它可以根据汽缸数量、发动机排量、马力、重量、加速度、车型年份和原产国来预测汽车的燃油经济性。考虑气缸,车型年款, 和起源作为分类变量。
负载carbig汽缸=分类(圆柱);model_year =分类(model_year);来源=分类(Cellstr(origin));X =表(圆柱,位移,马力,重量,加速,型号,原点);
确定预测器中的水平
标准的CART算法倾向于将具有许多唯一值(层次)的预测器(例如,连续变量)与具有较少层次(例如,分类变量)的预测器分开。如果您的数据是异构的,或者您的预测变量在其级别的数量上差异很大,那么考虑使用曲率或交互测试来选择分裂预测器,而不是标准的CART。
对于每个预测器,确定数据中水平的数量。一种方法是定义一个匿名函数:
使用。将所有变量转换为类别数据类型
分类确定所有唯一类别,同时忽略缺失值
类别使用类别使用
元素个数
然后,使用函数将函数应用于每个变量varfun.
countlevels = @(x)numel(类别(分类(x)));numlevels = varfun(countlevels,x,“OutputFormat”,“统一”);
比较预测变量中的级别数量。
图酒吧(numLevels)标题('预测因子之间的水平数量')xlabel('predictor变量')ylabel(的层数)h=gca;h、 XTickLabel=X.Properties.VariableNames(1:end-1);h、 XTickLabelRotation=45;h、 滴答计=“没有”;
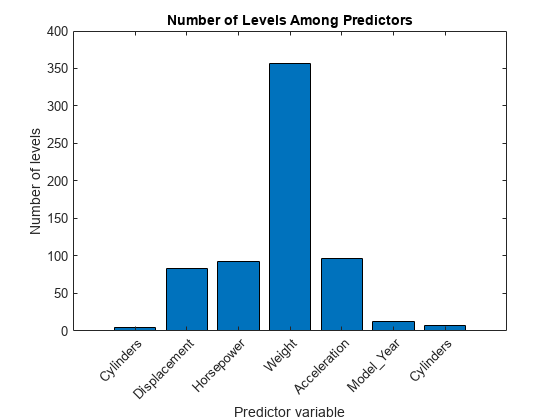
连续变量具有比分类变量更多的级别。因为预测器中的水平的数量变化如此多,所以使用标准购物车在随机林中的树木的每个节点处选择分割预测器,可以产生不准确的预测因素重要性估计。在这种情况下,使用曲率测试或相互作用测试。使用该算法指定算法'预测圈'名称值对参数。有关更多详细信息,请参阅选择分裂预测器选择技术.
套袋回归树系
培训一个袋装的200个回归树的合奏,以估计预测的重要价值。使用这些名称值对参数定义树立学习者:
“NumVariablesToSample”、“所有”—在每个节点使用所有预测变量,确保每棵树都使用所有预测变量。'预测圈','互动曲率'- 指定交互测试的用法选择分割预测器。'代理','上'-指定代理分割的用法,以提高准确性,因为数据集包含缺失的值。
t = templatetree(“NumVariablesToSample”,'全部',...'预测圈',“interaction-curvature”,“代孕”,“上”);rng (1);重复性的%mdl = fitrensemble(x,mpg,“方法”,'包',“NumLearningCycles”, 200,...“学习者”t);
MDL.是一个回归释迦缩短模型。
估计模型 使用袋子外的预测。
yHat=OOB预测(Mdl);R2=corr(Mdl.Y,yHat)^2
R2 = 0.8744
MDL.解释了87%的含义变异。
预测重点估计
通过禁用树木之间的袋子观测来估计预测值的重要性值。
Impoob = OobperMutedPredictorimportance(MDL);
impOOB1乘7的预测器重要性估计向量是否与中的预测器相对应mdl.predictornames..这些估计并不偏向于包含多个层次的预测指标。
比较预测器的重要性估计。
图酒吧(impOOB)标题('无偏见预测重点估计')xlabel('predictor变量')ylabel(“重要性”)H = GCA;h.xticklabel = mdl.predictornames;H.xticklabelrotation = 45;H.TicklabelInterpreter =.“没有”;
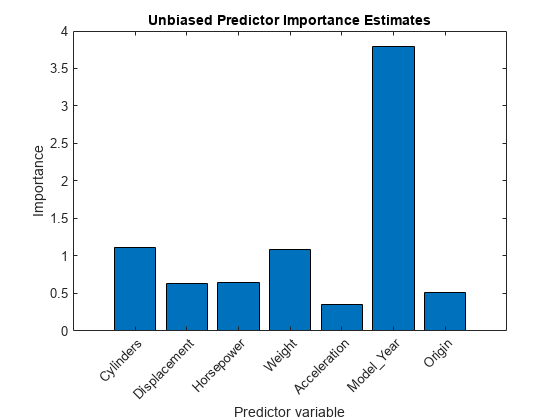
更重要的重要估计表明了更重要的预测因子。条形图表明车型年款最重要的预测因素是什么气缸和重量.的车型年款和气缸变量分别只有13和5个不同的层次,而重量变量超过300级。
通过禁用袋袋观测和通过在每个预测器上的分裂上的平均平均误差求和而获得的这些估计来比较预测测量的重要估计。此外,获得替代分裂估计的预测因子关联措施。
[Impgain,Predassociation] =预测测量值(MDL);图绘图(1:numel(mdl.predictornames),[Impoob'Impgain'])标题(“预测因子重要性估计比较”)xlabel('predictor变量')ylabel(“重要性”)H = GCA;h.xticklabel = mdl.predictornames;H.xticklabelrotation = 45;H.TicklabelInterpreter =.“没有”;传奇(“OOB排列的,“MSE改进”) 网格在
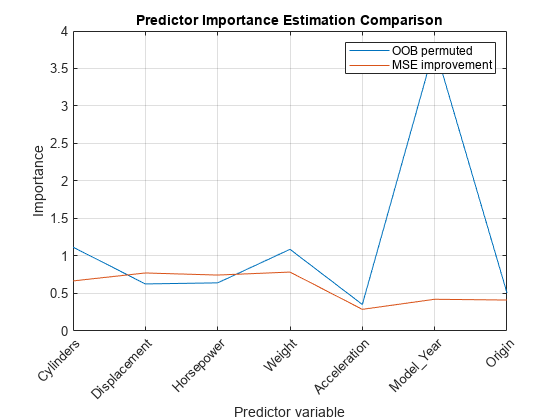
根据价值观冒险,变量位移,马力, 和重量似乎同样重要。
挖掘是一个7 × 7的预测器关联度量矩阵。行和列对应于mdl.predictornames..的预测措施是一个值,该值指示分割观察的决策规则之间的相似性。最好的代理决策分割产生最大的关联预测度量。使用的元素可以推断出对预测器之间关系的强度挖掘.数值越大表明预测因子的相关性越高。
图ImageC(Predassociation)标题('预测者协会估计')ColorBar H = GCA;h.xticklabel = mdl.predictornames;H.xticklabelrotation = 45;H.TicklabelInterpreter =.“没有”;h.YTickLabel = Mdl.PredictorNames;
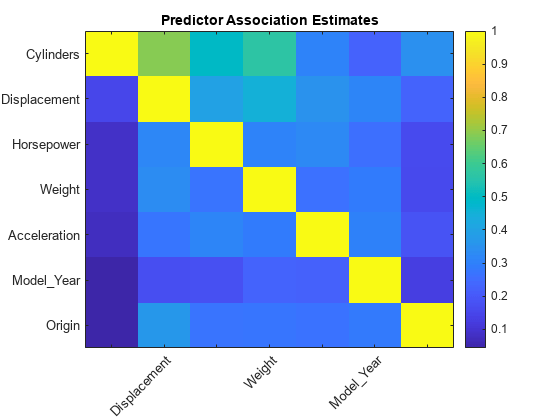
predassociation(1,2)
ans = 0.6871
最大的关联是气缸和位移,但该值不够高,以表明两个预测因子之间的牢固关系。
使用简化的预测器集生长随机森林
因为在随机森林中,预测时间随着预测器数量的增加而增加,一个好的实践是使用尽可能少的预测器创建模型。
只使用最好的两个预测器生长一个由200棵回归树组成的随机森林。默认的“NumVariablesToSample”的价值templateTree是回归的预测器数量的三分之一,所以fitrensemble.使用随机林算法。
t = templatetree('预测圈',“interaction-curvature”,“代孕”,“上”,...“复制”,真正的);%用于随机预测器选择的重现性MdlReduced = fitrensemble (X (: {'model_year''重量'}),MPG,“方法”,'包',...“NumLearningCycles”, 200,“学习者”t);
计算 简化模型。
yHatReduced=OOB预测(MDL预测);r2Reduced=corr(Mdl.Y,YHArtreduced)^2
r2Reduced = 0.8653
的 对于简化后的模型是接近于 完整的模型。该结果表明,降低的模型足以预测。
另请参阅
corr|fitrensemble.|oobPermutedPredictorImportance|oobPredict|predictorImportance|templateTree
相关话题
您还可以从以下列表中选择一个网站:
