Classificationedecoc.
支持向量机等分类器的交叉验证多类ECOC模型金宝app
描述
Classificationedecoc.是一组错误校正的输出代码(ECOC)模型,在交叉验证的折叠上培训。使用一个或多个“kfold”功能估算交叉验证分类的质量:kfoldPredict,kfoldLoss,Kfoldmargin.,kfoldEdge, 和kfoldfun..
每一种“kfold”方法都使用在训练折叠(内折叠)观测上训练的模型来预测验证折叠(外折叠)观测的响应。例如,假设您使用5倍交叉验证。在这种情况下,软件将每个观察结果随机分配到大小相同(大致)的五组。的训练折叠包含四个组(大约4/5的数据),以及验证褶皱包含其他组(大约1/5的数据)。在这种情况下,交叉验证进行如下:
软件训练第一个模型(存储在
cvmdl.tromed {1})通过在最后四组中使用观察,并保留第一组的观察结果进行验证。该软件列举了第二种模型(存储在
cvmdl.tromed {2})通过使用第一组和最后三组的观察。该软件储备在第二组中的观察结果进行验证。该软件以类似的方式进行第三,第四和第五型号。
如果使用使用kfoldPredict,该软件计算出对小组观测结果的预测我通过使用我模型。简而言之,该软件通过使用未经该观察而训练的模型来估计每个观察的响应。
创建
您可以创建Classificationedecoc.模型以两种方式:
属性
对象的功能
kfoldEdge |
交叉验证ECOC模型的分类边缘 |
kfoldLoss |
交叉验证ECOC模型的分类损失 |
Kfoldmargin. |
交叉验证ECOC模型的分类裕度 |
kfoldPredict |
在交叉验证的ECOC模型中对观测结果进行分类 |
kfoldfun. |
交叉验证功能使用交叉验证的ECOC模型 |
例子
交叉验证ECOC分类器
用支持向量机二值学习器交叉验证ECOC分类器,估计广义分类误差。
装载Fisher的Iris数据集。指定预测器数据X以及响应数据Y.
负载渔民X =量;Y =物种;rng (1);重复性的%
创建SVM模板,并标准化预测器。
t = templatesvm('标准化',真的)
t =适合分类支持向量机的模板。α:[0 x1双]BoxConstraint: [] CacheSize: [] CachingMethod:“ClipAlphas: [] DeltaGradientTolerance:[]ε:[]GapTolerance: [] KKTTolerance: [] IterationLimit: [] KernelFunction:“KernelScale: [] KernelOffset: [] KernelPolynomialOrder: [] NumPrint:[]ν:[]OutlierFraction: [] RemoveDuplicates: [] ShrinkagePeriod:[]解算器:"标准化数据:1 SaveSupportVector金宝apps: [] VerbosityLevel:[]版本:2方法:'SVM'类型:'分类'
t是一个支持向量机模板。大多数模板对象属性都是空的。在训练ECOC分类器时,软件将适用属性设置为默认值。
训练ECOC分类器,并指定类的顺序。
mdl = fitcecoc(x,y,“学习者”,t,......'classnames',{'setosa','versicolor','virginica'});
MDL.是一个ClassificationECOC分类器。您可以使用点表示法访问其属性。
旨在MDL.使用10倍交叉验证。
cvmdl = crossval(mdl);
cvmdl.是一个Classificationedecoc.旨在ECOC分类器。
估计广义分类错误。
genError = kfoldLoss (CVMdl)
genError = 0.0400
广义分类误差为4%,这表明ECOC分类器概括得很好。
使用bin和并行计算加速训练ECOC分类器
使用a列车一个与所有ecoc分类器GentleBoost决策树与代理分裂的集合。加快培训,箱数字预测器并使用并行计算。啤酒才有效fitcecoc.使用树学习者。训练后,使用10倍交叉验证估计分类误差。请注意,并行计算需要parallel computing Toolbox™。
加载示例数据
装入并检查心律失常数据集。
负载心律失常(氮、磷)大小(X) =
n = 452.
p = 279
isLabels =独特(Y);nLabels =元素个数(isLabels)
nLabels = 13
汇总(分类(Y))
值计数百分比1 245 54.20% 2 44 9.73% 3 15 3.32% 4 15 3.32% 5 13 2.88% 6 25 5.53% 73 0.66% 8 2 0.44% 99 1.99% 10 50 11.06% 14 4 0.88% 15 5 1.11% 16 22 4.87%
数据集包含279预测因素和样本量452.相对较小。在16个不同的标签中,只有13个在响应中表示(Y).每个标签描述了不同程度的心律失常,54.20%的观察是在课堂上进行的1.
训练一个对所有ECOC分类器
创建集成模板。您必须指定至少三个参数:方法、学习者的数量和学习者的类型。对于本例,请指定'温船'对于方法,100.对于学习者的数量,以及由于缺少观察结果而使用代理拆分的决策树模板。
ttree = templatetree(“代孕”,“上”);tEnsemble = templateEnsemble ('温船',100,TTREE);
tEnsemble是模板对象。它的大部分属性都是空的,但是软件在训练期间用它们的默认值填充它们。
使用决策树作为二进制学习者培训一个与之一体的ECOC分类器。加快培训,使用分箱和并行计算。
装箱(
“NumBins”,50岁) -当你有一个大的训练数据集时,你可以通过使用“NumBins”名称值对参数。此参数仅在何时有效fitcecoc.使用树学习者。如果您指定了“NumBins”值,然后将软件将每个数字预测器置于指定数量的eciprobable bins中,然后在箱上的树木上生长树木指数而不是原始数据。你可以试试“NumBins”,50岁先改,再改“NumBins”值取决于准确性和训练速度。并行计算(
'选项',statset('deverypallellel',true)) - 使用并行计算工具箱许可证,您可以使用并行计算加快计算,该控从每个二进制学习者向池中的工作人员发送。工作人员的数量取决于您的系统配置。当您为二元学习者使用决策树时,fitcecoc.使用英特尔®螺纹构建块(TBB)并联培训进行双核系统及以上。因此,指定“UseParallel”选项对单台计算机无济于事。在群集中使用此选项。
另外,指定先验概率为1/K,在那里K= 13是不同类的数量。
选项= statset(“UseParallel”,真的);mdl = fitcecoc(x,y,'编码',“onevsall”,“学习者”tEnsemble,......'事先的',“统一”,“NumBins”,50,“选项”,选项);
使用“local”配置文件启动并行池(parpool)…连接到并行池(工作人员数量:6)。
MDL.是一个ClassificationECOC模型。
交叉验证
使用10倍交叉验证交叉验证ECOC分类器。
CVMdl = crossval (Mdl,“选项”,选项);
警告:一个或多个折叠不包含所有组的点。
cvmdl.是一个Classificationedecoc.模型。警告表明,当软件训练至少一倍时,有些类没有表示。因此,这些折叠不能预测缺失类的标签。可以使用单元格索引和点表示法检查折叠的结果。例如,通过输入来访问第一次折叠的结果cvmdl.tromed {1}.
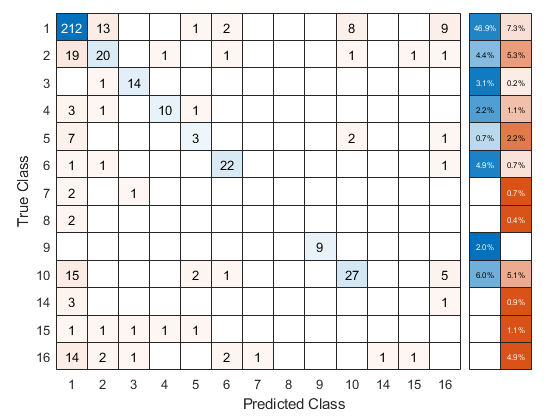
使用交叉验证的ECOC分类器预测验证折叠标签。您可以通过使用来计算混淆矩阵confusionchart.通过更改内部位置属性来移动和调整图表的大小,以确保百分比出现在行摘要中。
Ooflabel = kfoldpredict(cvmdl,“选项”,选项);Confmat = ConfusionChart(Y,Ooflabel,“RowSummary”,'总归一化');confmat.innerposition = [0.10 0.12 0.85 0.85];
再现Binned数据
通过使用使用的重现Binned预测测量数据毕业生培训模型的财产和离散化函数。
x = mdl.x;%的预测数据Xbinned = 0(大小(X));边缘= Mdl.BinEdges;%查找箱预测因子的指数。idxnumeric = find(〜cellfun(@ isempty,边));如果iscolumn(idxNumeric) idxNumeric = idxNumeric';结束为j = idxNumeric x = x (:,j);%如果x是一个表,则将x转换为数组。如果istable(x)x = table2array(x);结束%使用离散函数将x分组到bins中。xbinned =离散化(x,[ - inf;边缘{j}; inf]);Xbinned(:,j)= xbinned;结束
xbinned.包含单位,范围为1到箱数,用于数字预测器。xbinned.值是0对于分类预测器。如果X包含南S,然后对应的xbinned.值是南s。
您还可以从以下列表中选择一个网站:
