fitcdiscr
拟合判别分析分类器
语法
描述
MDL.= fitcdiscr(TBL.那responsevarname.)TBL.和输出(响应或标签)包含在内responsevarname..
例子
火车判别分析模型
装载Fisher的Iris数据集。
加载渔民
使用整个数据集训练判别分析模型。
MDL = fitcdiscr(MEAS,物种)
MDL = ClassificationDiscriminant ResponseName: 'Y' CategoricalPredictors:[]类名:{ 'setosa' '云芝' '锦葵'} ScoreTransform: '无' NumObservations:150 DiscrimType: '线性' 穆:[3x4的双] Coeffs:[3×3结构]属性,方法
MDL.是一个ClassificationDiscriminant模型。要访问其属性,请使用点表示法。例如,显示每个预测器的组手段。
Mdl.Mu
ans =.3×4.5.0060 3.4280 1.4620 0.2460 5.9360 2.7700 4.2600 1.3260 6.5880 2.9740 5.5520 2.0260
预测新的观察标签,合格MDL.并预测数据预测.
优化判别分析模型
此示例显示如何自动优化超级参数fitcdiscr.该示例使用Fisher的虹膜数据。
加载数据。
加载渔民
找到通过使用自动封路计优化来最小化五倍交叉验证损耗的高参数。
为了再现性,设置随机种子并使用“预期改善加成”采集功能。
rng(1) Mdl = fitcdiscr(meas,species,'OptimizeHyperparameters'那'汽车'那...“HyperparameterOptimizationOptions”那...struct('获取功能名称'那“预期改善加成”)))
|=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFarδ|γ| | | | |结果运行时| | | (estim(观察) .) | | | |=====================================================================================================| | 1 |最好| 0.66667 | 0.55533 | 0.66667 | 0.66667 | 13.261 | 0.25218 | | 2 |最好| 0.02 | 0.16727 | 0.02 | 0.064227 | 2.7404 e-05 | 0.073264 | | 3 |接受| 0.04 | 0.11506 | 0.02 | 0.020084 | 3.2455 e-06 | 0.46974 | | 4 |接受| 0.66667 | 0.18438 | 0.02 | 0.020118 | 14.879 | 0.98622 | | 5 |接受| 0.046667 | 0.32438 | 0.02 | 0.019907 | 0.00031449 |0.97362 | | 6 |接受| 0.04 | 0.12075 | 0.02 | 0.028438 | 4.5092 e-05 | 0.43616 | | | 7日接受| 0.046667 | 0.29976 | 0.02 | 0.031424 | 2.0973 e-05 | 0.9942 | | 8 |接受| 0.02 | 0.1413 | 0.02 | 0.022424 | 1.0554 e-06 | 0.0024286 | | | 9日接受| 0.02 | 0.093792 | 0.02 | 0.021105 | 1.1232 e-06 | 0.00014039 | | |接受10 | 0.02 | 0.11764 | 0.02 |0.020948 | 0.00011837 | 0.0032994 | | | 11日接受| 0.02 | 0.093061 | 0.02 | 0.020172 | 1.0292 e-06 | 0.027725 | | | 12日接受| 0.02 | 0.14814 | 0.02 | 0.020105 | 9.7792 e-05 | 0.0022817 | | | 13日接受| 0.02 | 0.093105 | 0.02 | 0.020038 | 0.00036014 | 0.0015136 | | | 14日接受| 0.02 | 0.11795 | 0.02 | 0.019597 | 0.00021059 | 0.0044789 | | 15 |接受| 0.02 | 0.12956 | 0.02 | 0.019461 | 1.1911 e-05 | 0.0010135 | | | 16日接受| 0.02 | 0.12873 | 0.02 | 0.01993 | 0.0017896 | 0.00071115 | | | 17日接受| 0.02 | 0.14435 | 0.02 | 0.019551 | 0.00073745 | 0.0066899 | | | 18日接受| 0.02 | 0.10022 | 0.02 | 0.019776 | 0.00079304 | 0.00011509 | | | 19日接受| 0.02 | 0.13593 | 0.02 | 0.019678 |0.007292 | 0.0007911 | | 20 |接受| 0.046667 | 0.13776 | 0.02 | 0.019785 | 0.0074408 | 0.99945 | |=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar |δ|γ| | |结果| | |运行时(观察)| (estim) | | ||=====================================================================================================| | 21日|接受| 0.02 | 0.095239 | 0.02 | 0.019043 | 0.0036004 | 0.0024547 | | | 22日接受| 0.02 | 0.09429 | 0.02 | 0.019755 | 2.5238 e-05 | 0.0015542 | | | 23日接受| 0.02 | 0.20405 | 0.02 | 0.0191 | 1.5478 e-05 | 0.0026899 | | | 24日接受| 0.02|0.。21602 | 0.02 | 0.019081 | 0.0040557 | 0.00046815 | | 25 | Accept | 0.02 | 0.12796 | 0.02 | 0.019333 | 2.959e-05 | 0.0011358 | | 26 | Accept | 0.02 | 0.15358 | 0.02 | 0.019369 | 2.3111e-06 | 0.0029205 | | 27 | Accept | 0.02 | 0.15441 | 0.02 | 0.019455 | 3.8898e-05 | 0.0011665 | | 28 | Accept | 0.02 | 0.12762 | 0.02 | 0.019449 | 0.0035925 | 0.0020278 | | 29 | Accept | 0.66667 | 0.37787 | 0.02 | 0.019479 | 998.93 | 0.064276 | | 30 | Accept | 0.02 | 0.25714 | 0.02 | 0.01947 | 8.1557e-06 | 0.0008004 |
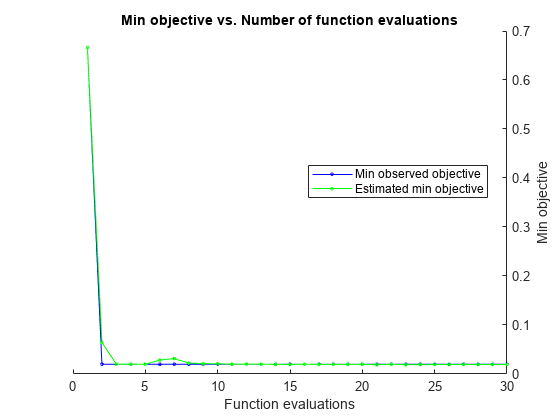
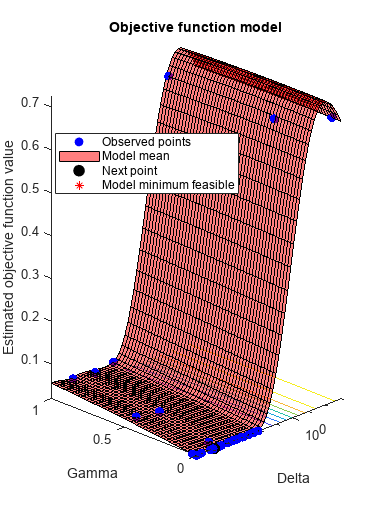
__________________________________________________________ 优化完成。maxobjective达到30个。总功能评价:30总的经过时间:55.176秒总目标函数评估时间:5.1566最佳观察到的可行点:德尔塔伽玛__________ ________ 2.7404e-05 0.073264观测目标函数值= 0.02。估价目标函数值= 0.022693函数求时间= 0.16727最佳(根据型号)估计可行点:德尔塔伽玛__________ _________ 2.5238e-05 0.0015542估计目标函数值= 0.01947估计函数评估时间= 0.14522
mdl = classificationd discriminant racatectename:'y'pationoricalpricictors:[] classnames:{'setosa''versicolor''virginica'} scoreTransform:'none'numobservations:150 hyperameteroptimationresults:[1x1 bayesianoptimization] strictimype:'linear'mu:[3x4 double]COEFFS:[3x3结构]属性,方法
适用于默认的5倍交叉验证达到约2%的损失。
高阵判别分析模型的优化
此示例示出了如何自动使用高阵列优化判别分析模型的超参数。样本数据集Airlinesmall.csv.是一个大型数据集,其中包含航空公司航班数据的表格文件。这个示例创建了一个包含数据的高表,并使用它来运行优化过程。
当您在高大的阵列进行计算,MATLAB®使用使用并行池(默认情况下,如果您有并行计算工具箱™)或本地MATLAB会话。如果你想使用时,你有并行计算工具箱本地MATLAB会话运行示例,您可以通过使用改变全球执行环境mapreduce函数。
创建数据存储引用的数据的文件夹位置。选择变量的一个子集一起工作,和治疗'na'值丢失的数据,以便数据存储取代他们南价值观。创建一个包含数据存储中的数据的高表。
ds =数据存储(“airlinesmall.csv”);ds.selectedvariablenames = {'月'那“DayofMonth”那“星期几”那...'deptime'那“延迟”那'距离'那'depdelay'};ds.TreatAsMissing ='na';TT =高(DS)%高表
使用“本地”配置文件启动并行池(Parpool)连接到并行池(工人数:6)。TT = M×7高大表月DAYOFMONTH DAYOFWEEK DepTime ArrDelay距离DepDelay _____ __________ _________ _______ ________ ________ ________ 10 21 3 642 8 308 12 10 26 1 1021 8 296 1 10 23 5 2055 21 480 20 10 23 5 1332 13 296 12 1022 4 629 4 373 10 -1 28 3 1446 59 308 63 10 8 4 928 3 447 10 -2 10 6 859 11 954 -1::::::::::::::
确定通过定义一个逻辑变量,一个迟到的飞行是真的迟到了10分钟以上的航班。此变量包含类的标签。这个变量的预览包括前几行。
Y = tt。DepDelay > 10%类标签
Y = M×1 tall logical array 1 0 1 1 0 1 0 0::
为预测器数据创建高阵列。
X=tt{,1:end-1}%的预测数据
X = M×6高,双矩阵10 21 3 642 8 308 10 2 23 5 2055 2 23 10 23 5 133213 23 10 23 5 13329 4 3230 23 5 1329 4 3231 10 23 3 1446 59 3030 8 4 928 3 44710 10 10 6 859 11 954 ::::::::::::::::::::::::::::::::::::::::::
删除行中X和y包含缺失数据。
r = rmmissing([x y]);%删除缺失条目的数据x = r(:,1:结束-1);Y = R(:,结束);
标准化预测变量。
Z = zscore (X);
方法自动优化超参数'OptimizeHyperparameters'名称-值对的论点。找到最佳“DiscrimType”最大限度地减少拒绝交叉验证损失的值。(指定'汽车'使用“DiscrimType”.)为了再现性,请使用“预期改善加成”获取函数,并使用RNG.和tallrng.结果可以根据工人数量和高大阵列的执行环境而有所不同。有关详细信息,请参见控制代码运行的位置.
rng ('默认') tallrng ('默认')[mdl,fitinfo,hyperparameteroptimationresults] = fitcdiscr(z,y,...'OptimizeHyperparameters'那'汽车'那...“HyperparameterOptimizationOptions”,struct(“坚持”,0.3,...'获取功能名称'那“预期改善加成”)))
using the Parallel Pool 'local': - Pass 1 of 2:在5.7 sec内完成- Pass 2 of 2:在4.3 sec内完成在2.5秒完成评估在2.8秒完成 |======================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar | DiscrimType | | |结果| | |运行时(观察)| (estim) | ||======================================================================================| | 最好1 | | 0.11354 | 25.315 | 0.11354 | 0.11354 |二次|
使用并行池“本地”评估高表达: - 通过1:在1.5秒评估中完成的1.5秒评估,使用并行池“本地”评估高表达式: - 通过1:1:在1.4秒评估中完成的1/1:完成1.6秒|2 |接受|0.11354 |7.9367 |0.11354 |0.11354 |Pseudoquadra |
评估使用并行池“本地”高表达: - 的1遍1:在0.87秒评价完成在2秒完成评估使用并行池“本地”高表达: - 的1遍1:在0.78秒评价完成在完成0.91秒|3 |接受|0.12869 |6.5057 |0.11354 |0.11859 |拟线性|
评估使用并行池“本地”高表达: - 的1遍1:在0.9秒评价完成在1.7秒完成评估使用并行池“本地”高表达: - 的1遍1:在1.3秒评价完成在完成1.4秒|4 |接受|0.12745 |6.4167 |0.11354 |0.1208 |diagLinear |
使用并行池“本地”评估高表达: - 通过1:0.85秒的评估中已完成,在1.7秒的评估中完成使用并行池“本地”评估高表达: - PASS 1,共1分:在0.8秒评估中完成0.93秒|5 |接受|0.12869 |6.1236 |0.11354 |0.12238 |线性|
使用并行池“本地”评估高表达: - 通过1:在0.85秒的评估中完成,在1.5秒评估高度表达式中,使用并行池“本地”评估: - PASS 1为1:0.75秒评估完成0.9秒|6 |最好的0.11301 |5.4147 |0.11301 |0.12082 |diagquadrati |
使用并行池“本地”评估高表达: - 通过1/1:在0.82秒的评估中完成,在1.5秒评估高度表达式中,使用并行池“本地”评估: - PASS 1为1:在0.77秒内完成的评估0.89秒|7 |接受|0.11301 |5.297 |0.11301 |0.11301 |diagquadrati |
使用并行池“本地”评估tall表达式:-通过1/1:在0.84秒内完成评估在1.5秒内完成使用并行池“本地”评估tall表达式:-通过1/1:在0.8秒内完成评估在0.93秒内完成| 8 |接受| 0.11301 | 5.6152 | 0.11301 | 0.11301 | Diagquarti|
使用并行池“本地”评估高表达: - 通过1:1:在1.3秒评估中完成,在2.1秒的评估中完成使用并行池“本地”评估高表达式: - PASS 1为1:在0.75秒的评估中完成0.88秒|9 |接受|0.11301 |5.9147 |0.11301 |0.11301 |diagquadrati |
评估高表达式使用并行池“当地”:通过1对1:在0.88秒完成评估在1.6秒完成评估高表达式使用并行池“当地”:通过1对1:在1.3秒完成评估完成1.4秒| 10 |接受| 0.11301 | 6.0504 | 0.11301 | 0.11301 | diagQuadrati |
评估高表达式使用并行池“当地”:通过1对1:在0.82秒完成评估在1.5秒完成评估高表达式使用并行池“当地”:通过1对1:在1.3秒完成评估完成1.4秒| | 11日接受| 0.11301 | 5.9595 | 0.11301 | 0.11301 | diagQuadrati |
评估使用并行池“本地”高表达: - 的1遍1:在0.86秒评价完成在1.6秒完成评估使用并行池“本地”高表达: - 的1遍1:在0.76秒评价完成在完成0.91秒|12 |接受|0.11301 |5.4266 |0.11301 |0.11301 |diagquadrati |
使用并行池“本地”评估高表达: - 通过1:在0.88秒的评估中完成,在1.6秒的评估中完成使用并行池“本地”评估高表达式: - PASS 1为1:在0.75秒的评估中完成0.87秒|13 |接受|0.11301 |5.3869 |0.11301 |0.11301 |diagquadrati |
使用并行池“本地”评估高表达: - 通过1:在0.83秒的评估中完成,在1.5秒的评估中完成,使用并行池“本地”评估高表达式: - PASS 1:在0.8秒评估中完成的第1条:完成0.97秒|14 |接受|0.11301 |5.4876 |0.11301 |0.11301 |diagquadrati |
评估高表达式使用并行池“当地”:通过1对1:在0.85秒完成评估在1.5秒完成评估高表达式使用并行池“当地”:通过1对1:在0.73秒完成评估在0.85秒完成15 | |接受| 0.11301 | 5.4052 | 0.11301 | 0.11301 | diagQuadrati |
使用并行池“本地”评估tall表达式:-通过1/1:在0.87秒内完成评估在1.5秒内完成使用并行池“本地”评估tall表达式:-通过1/1:在0.78秒内完成评估在0.9秒内完成| 16 |接受| 0.11301 | 5.4434 | 0.11301 | 0.11301 | Diagquarti|
评估高表达式使用并行池“当地”:通过1对1:在0.89秒完成评估在1.6秒完成评估高表达式使用并行池“当地”:通过1对1:在0.8秒完成评估在0.93秒完成17 | |接受| 0.11301 | 5.5804 | 0.11301 | 0.11301 | diagQuadrati |
评估使用并行池“本地”高表达: - 的1遍1:在0.94秒评价完成在1.6秒完成评估使用并行池“本地”高表达: - 的1遍1:在0.79秒评价完成在完成0.92秒|18 |接受|0.11354 |5.616 |0.11301 |0.11301 |Pseudoquadra |
评估高表达式使用并行池“当地”:通过1对1:在0.85秒完成评估在1.5秒完成评估高表达式使用并行池“当地”:通过1对1:在0.76秒完成评估完成0.88秒19 | |接受| 0.11301 | 5.4031 | 0.11301 | 0.11301 | diagQuadrati |
使用并行池“本地”评估高表达: - PASS 1:0.76秒的评估中完成的1.4秒评估使用并行池“本地”评估高表达式: - PASS 1为1:在0.75秒的评估中完成0.88秒|20 |接受|0.11301 |5.1974 |0.11301 |0.11301 |diagquadrati |
使用并行池“本地”评估高表达: - 通过1:在0.77秒的评估中完成的1.4秒评估,使用并行池“本地”评估高表达式: - PASS 1为1:在0.75秒的评估中完成0.87秒| ======================================================================================|磨练|eval |目标|目标|Bestsofar |Bestsofar |SCOLIMTYPE | | | result | | runtime | (observed) | (estim.) | | |======================================================================================| | 21 | Accept | 0.11301 | 5.1418 | 0.11301 | 0.11301 | diagQuadrati |
评估高表达式使用并行池“当地”:通过1对1:在1.3秒完成评估在2秒完成评估高表达式使用并行池“当地”:通过1对1:在0.73秒完成评估完成0.86秒| | 22日接受| 0.11301 | 5.9864 | 0.11301 | 0.11301 | diagQuadrati |
使用并行池“本地”评估高表达: - 通过1:在0.88秒的评估中完成的1.6秒评估,使用并行池“本地”评估高表达式: - PASS 1在0.78秒的评估中完成0.91秒|23 |接受|0.11354 |5.5656 |0.11301 |0.11301 |二次|
使用并行池“本地”评估tall表达式:-通过1/1:在0.82秒内完成评估在1.5秒内完成使用并行池“本地”评估tall表达式:-通过1/1:在0.77秒内完成评估在0.9秒内完成| 24 |接受| 0.11354 | 5.3012 | 0.11301 | 0.11301 |伪四边形|
评估高表达式使用并行池“当地”:通过1对1:在1.4秒完成评估在2.1秒完成评估高表达式使用并行池“当地”:通过1对1:在0.77秒完成评估在0.9秒完成25 | |接受| 0.11301 | 6.2276 | 0.11301 | 0.11301 | diagQuadrati |
评估使用并行池“本地”高表达: - 的1遍1:在0.86秒评价完成在1.6秒完成评估使用并行池“本地”高表达: - 的1遍1:在0.77秒评价完成在完成0.89秒|26 |接受|0.11301 |5.5308 |0.11301 |0.11301 |diagquadrati |
使用并行池“本地”评估高表达: - 通过1:0.92秒的评估中完成的1.6秒评估,使用并行池“本地”评估高表达式: - PASS 1为1:在0.88秒的评估中完成1秒|27 |接受|0.11301 |5.7396 |0.11301 |0.11301 |diagquadrati |
评估高表达式使用并行池“当地”:通过1对1:在0.83秒完成评估在1.5秒完成评估高表达式使用并行池“当地”:通过1对1:在0.78秒完成评估完成0.9秒| | 28日接受| 0.11354 | 5.4403 | 0.11301 | 0.11301 |二次|
评估高表达式使用并行池“当地”:通过1对1:在0.86秒完成评估在1.5秒完成评估高表达式使用并行池“当地”:通过1对1:在0.81秒完成评估完成0.93秒| | 29日接受| 0.11301 | 5.3572 | 0.11301 | 0.11301 | diagQuadrati |
使用并行池“本地”评估tall表达式:-通过1/1:在0.89秒内完成评估在1.6秒内完成使用并行池“本地”评估tall表达式:-通过1/1:在0.74秒内完成评估在0.85秒内完成| 30 |接受| 0.11354 | 5.2718 | 0.11301 | 0.11301 |二次|


__________________________________________________________ 优化完成。maxobjective达到30个。总函数计算:30总运行时间:229.5689秒。总目标函数评价时间:191.058最佳观测可行点:DiscrimType _____________ diag二次观测目标函数值= 0.11301估计目标函数值= 0.11301函数评价时间= 5.4147最佳估计可行点(根据模型):DiscrimType _____________ diag二次估计目标函数值= 0.11301估计函数评估时间= 5.784使用Parallel Pool 'local'评估tall表达式:- Pass 1 of 1: Completed in 0.76 sec评估在1.4秒内完成
Mdl = CompactClassificationDiscriminant PredictorNames: {'x1' 'x2' 'x3' 'x4' 'x5' 'x6'} ResponseName: 'Y' CategoricalPredictors: [] ClassNames: [0 1] ScoreTransform: 'none' DiscrimType: ' diag二次' Mu: [2×6 double] Coeffs: [2×2 struct]属性,方法
FitInfo =结构没有字段。
HyperParameterOptimizationResults =具有属性的贝叶斯optimization:ObjectFCN:@ CreateBjfcn / Tallobjfcn Variabledions:[1×1 oldizablevariable]选项:[1×1结构] minobjective:0.1130 Xatminobjective:[1×1表] minestimatedobive:0.1130 XATMineStimateGiple:[1×1表]numObjectiveEvaLuations:30总计迭代图中:[30×1双] errortrace:[30×1双]可行性议事:[30×1逻辑]可行性推动力:[30×1双]索引:[30×1双] objectivemimumimumImimumImimumimumimumImimumImimumimumImimumImimumimumImimumimumImumImimumImimumImimumImimumimumImimumImimumImimumImimumimumInum:[30×1双]
输入参数
输出参数
更多关于
提示
培训模型后,您可以生成C / C ++代码,该代码预测新数据的标签。生成C / C ++代码需要MATLAB编码器™. 有关详细信息,请参阅代码生成简介.
替代功能
扩展功能
您还可以从以下列表中选择一个网站:
