主要内容
预测
用判别分析分类模型预测标签
描述
输入参数
输出参数
例子
用判别分析模型预测类别标签
加载Fisher的iris数据集。确定样本大小。
负载fisheriris1) N =大小(量;
将数据划分为训练集和测试集。拿出10%的数据进行测试。
rng (1);%的再现性本量利= cvpartition (N,“坚持”, 0.1);idxTrn =培训(cvp);%训练集指标idxTest =测试(cvp);%测试集索引
将训练数据存储在一个表中。
tblTrn = array2table(量(idxTrn:));tblTrn。Y=species(idxTrn);
使用训练集和默认选项训练判别分析模型。
Mdl = fitcdiscr (tblTrn,“Y”);
预测测试集的标签。你训练Mdl使用数据表,但可以使用矩阵预测标签。
标签=预测(Mdl,meas(idxTest,:);
为测试集构造一个混淆矩阵。
confusionchart(物种(idxTest)、标签)
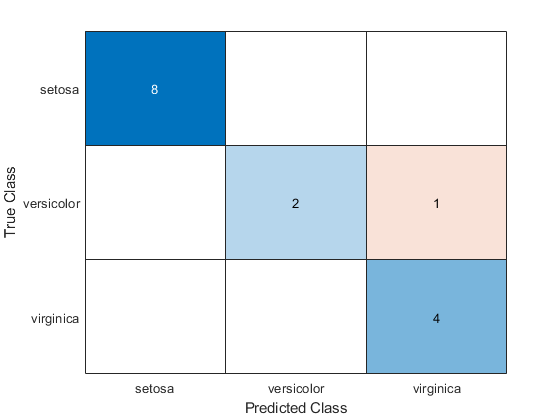
Mdl将测试集中的一个杂色虹膜误分类为virginica。
图类后验概率区域
载入费雪的虹膜数据集。只考虑使用花瓣的长度和宽度进行训练。
负载fisheririsX =量(:,3:4);
使用整个数据集训练二次判别分析模型。
Mdl=fitcdiscr(X,物种,“歧视型”,“二次”);
在观测的预测器空间中定义一个网格值。预测网格中每个实例的后验概率。
xMax = max (X);xMin = min (X);d = 0.01;[x1Grid, x2Grid] = meshgrid (xMin (1): d: xMax (1) xMin (2): d: xMax (2));[~,分数]=预测(Mdl [x1Grid (:), x2Grid (:)));Mdl.ClassNames
ans =3 x1细胞{'setosa'} {'versicolor'} {'virginica'}
分数是类后验概率矩阵。列对应于Mdl.ClassNames.例如,分数(j, 1)是观察到的后验概率吗j是鸢尾。
在网格中绘制每个观测的花色分类的后验概率,并绘制训练数据。
图;contourf (x1Grid x2Grid,重塑(分数(:,2),大小(x1Grid, 1),大小(x1Grid, 2)));h = colorbar;caxis ([0 1]);colormap喷气式飞机持有在…上gscatter (X (: 1) X(:, 2),物种,“麦基”,的方式来+);轴线紧头衔(“花斑的后验概率”);持有从
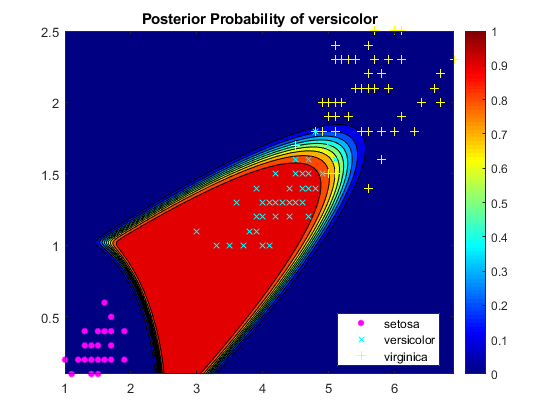
后验概率区域暴露了决策边界的一部分。
更多关于
扩展能力
介绍了R2011b
你也可以从以下列表中选择一个网站:
