分类GydF4y2Ba
使用判别分析对观察结果进行分类GydF4y2Ba
语法GydF4y2Ba
描述GydF4y2Ba
笔记GydF4y2Ba
fitcdiscrGydF4y2Ba和GydF4y2Ba预测GydF4y2Ba建议在GydF4y2Ba分类GydF4y2Ba用于训练判别分析分类器和预测标签。GydF4y2BafitcdiscrGydF4y2Ba金宝app支持交叉验证和超参数优化,并且不需要每次做出新的预测或更改先验概率时都适合分类器。GydF4y2Ba
班GydF4y2Ba=分类(GydF4y2Ba样品GydF4y2Ba,GydF4y2Ba训练GydF4y2Ba,GydF4y2Ba集团GydF4y2Ba)GydF4y2Ba样品GydF4y2Ba将数据放入其中一个组中GydF4y2Ba训练GydF4y2Ba属于。用于GydF4y2Ba训练GydF4y2Ba是指定的GydF4y2Ba集团GydF4y2Ba。函数返回GydF4y2Ba班GydF4y2Ba,其中包含为每一行分配的组GydF4y2Ba样品GydF4y2Ba.GydF4y2Ba
班GydF4y2Ba=分类(GydF4y2Ba样品GydF4y2Ba,GydF4y2Ba训练GydF4y2Ba,GydF4y2Ba集团GydF4y2Ba,GydF4y2Ba类型GydF4y2Ba,GydF4y2Ba先前的GydF4y2Ba)GydF4y2Ba类型GydF4y2Ba判别函数,和GydF4y2Ba先前的GydF4y2Ba每组的概率。GydF4y2Ba
[GydF4y2Ba也返回明显错误率(GydF4y2Ba班GydF4y2Ba,GydF4y2Ba犯错误GydF4y2Ba,GydF4y2Ba后面的GydF4y2Ba,GydF4y2BalogpGydF4y2Ba,GydF4y2Ba多项式系数GydF4y2Ba]=分类(GydF4y2Ba___GydF4y2Ba)GydF4y2Ba犯错误GydF4y2Ba),训练观察的后验概率(GydF4y2Ba后面的GydF4y2Ba),样本观测的无条件概率密度的对数(GydF4y2BalogpGydF4y2Ba),以及边界曲线的系数(GydF4y2Ba多项式系数GydF4y2Ba),使用前面语法中的任何输入参数组合。GydF4y2Ba
例子GydF4y2Ba
使用线性判别分析进行分类GydF4y2Ba
加载GydF4y2Ba鱼腥草GydF4y2Ba数据集。创建GydF4y2Ba集团GydF4y2Ba作为包含虹膜物种的字符向量的细胞阵列。GydF4y2Ba
负载GydF4y2Ba鱼腥草GydF4y2Ba组=物种;GydF4y2Ba
这个GydF4y2Ba量GydF4y2Ba矩阵包含四个花瓣尺寸为150个鸢尾。将观察数据随机划分为训练集(GydF4y2BatrainingDataGydF4y2Ba)及样本集(GydF4y2Ba样本数据GydF4y2Ba)与分层,利用群体信息GydF4y2Ba集团GydF4y2Ba.指定40%的抵抗样本GydF4y2Ba样本数据GydF4y2Ba.GydF4y2Ba
rng (GydF4y2Ba“默认”GydF4y2Ba)GydF4y2Ba%的再现性GydF4y2Ba简历= cvpartition(集团GydF4y2Ba“坚持”GydF4y2Ba, 0.40);trainInds =培训(简历);sampleInds =测试(简历);trainingData =量(trainInds:);sampleData =量(sampleInds:);GydF4y2Ba
分类GydF4y2Ba样本数据GydF4y2Ba使用线性判别分析,并从真实标签中创建一个混淆图GydF4y2Ba集团GydF4y2Ba以及预测中的标签GydF4y2Ba班GydF4y2Ba.GydF4y2Ba
类=分类(sampleData, trainingData、组(trainInds));厘米= confusionchart(集团(sampleInds)类);GydF4y2Ba
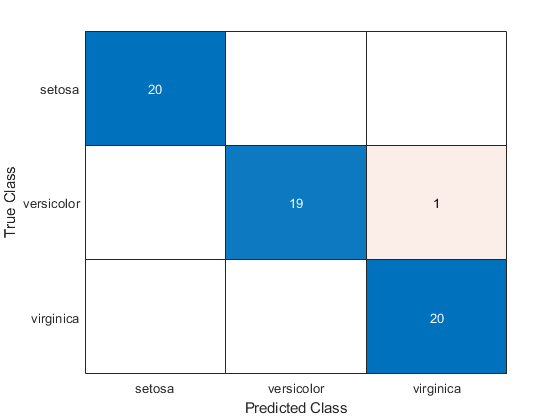
这个GydF4y2Ba分类GydF4y2Ba函数将样本数据集中的一个花斑虹膜误分类为virginica。GydF4y2Ba
二次判别分析分类及决策边界可视化GydF4y2Ba
使用二次判别分析对测量网格(样本数据)中的数据点进行分类。然后,可视化样本数据、训练数据和决策边界。GydF4y2Ba
加载GydF4y2Ba鱼腥草GydF4y2Ba数据集。创建GydF4y2Ba集团GydF4y2Ba作为包含虹膜物种的字符向量的细胞阵列。GydF4y2Ba
负载GydF4y2Ba鱼腥草GydF4y2Ba组=物种(51:结束);GydF4y2Ba
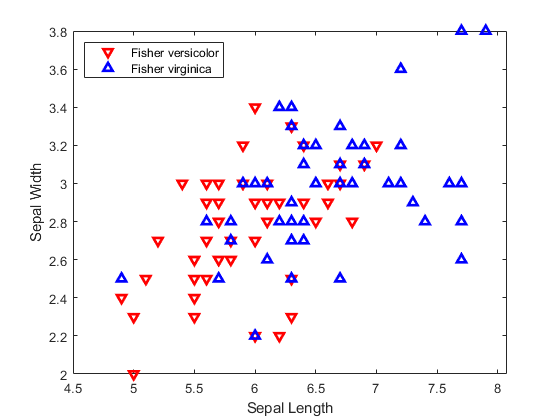
图中萼片长度(GydF4y2BaSLGydF4y2Ba)及宽度(GydF4y2Ba西南GydF4y2Ba)云芝和弗吉尼亚鸢尾属物种的测量。GydF4y2Ba
SL=meas(51:end,1);SW=meas(51:end,2);h1=gscatter(SL,SW,组,GydF4y2Barb的GydF4y2Ba,GydF4y2Ba"v^"GydF4y2Ba,[],GydF4y2Ba“关闭”GydF4y2Ba);h1(1)。L我NeWidth = 2; h1(2).LineWidth = 2; legend(“费希尔花色”GydF4y2Ba,GydF4y2Ba“费希尔·维吉尼亚”GydF4y2Ba,GydF4y2Ba“位置”GydF4y2Ba,GydF4y2Ba“西北”GydF4y2Ba)包含(GydF4y2Ba“花萼长度”GydF4y2Ba) ylabel (GydF4y2Ba“萼片宽度”GydF4y2Ba)GydF4y2Ba
创建GydF4y2Ba样本数据GydF4y2Ba作为一个包含测量网格的数值矩阵。创建GydF4y2BatrainingDataGydF4y2Ba作为一个数字矩阵,其中包含鸢尾花色和弗吉尼亚种萼片长度和宽度的测量值。GydF4y2Ba
(X, Y) = meshgrid (linspace (4.5 8), linspace(2、4));X = X (:);Y = Y (:);采样数据= [X Y];训练数据= [SL SW];GydF4y2Ba
分类GydF4y2Ba样本数据GydF4y2Ba使用二次判别分析。GydF4y2Ba
[C犯错后,logp,多项式系数]=分类(sampleData trainingData,集团GydF4y2Ba“二次”GydF4y2Ba);GydF4y2Ba
检索系数GydF4y2BaKGydF4y2Ba,GydF4y2BaLGydF4y2Ba,GydF4y2BaMGydF4y2Ba求这两个类之间的二次边界。GydF4y2Ba
K=系数(1,2).常数;L=系数(1,2).线性;Q =多项式系数(1、2).quadratic;GydF4y2Ba
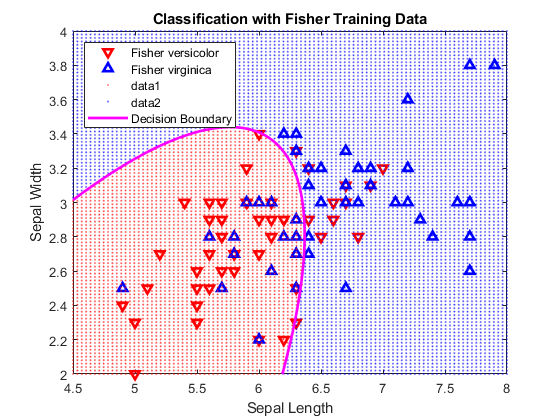
分隔这两个类别的曲线由以下等式定义:GydF4y2Ba
可视化判别分类。GydF4y2Ba
持有GydF4y2Ba在GydF4y2Bah2=gscatter(X,Y,C,GydF4y2Barb的GydF4y2Ba,GydF4y2Ba'.'GydF4y2Ba, 1GydF4y2Ba“关闭”GydF4y2Ba);f = @(x,y) K + L(1)*x + L(2)*y + Q(1,1)*x。* x + (Q(1、2)+ Q (2,1)) * x。* y + Q (2, 2) * y。* y;H3 = fimplicit(f,[4.5 8 2 4]);h3。颜色=GydF4y2Ba“米”GydF4y2Ba;h3.LineWidth=2;h3.DisplayName=GydF4y2Ba“决策边界”GydF4y2Ba;持有GydF4y2Ba关GydF4y2Ba轴GydF4y2Ba紧GydF4y2Ba包含(GydF4y2Ba“花萼长度”GydF4y2Ba) ylabel (GydF4y2Ba“萼片宽度”GydF4y2Ba)标题(GydF4y2Ba“使用Fisher训练数据进行分类”GydF4y2Ba)GydF4y2Ba
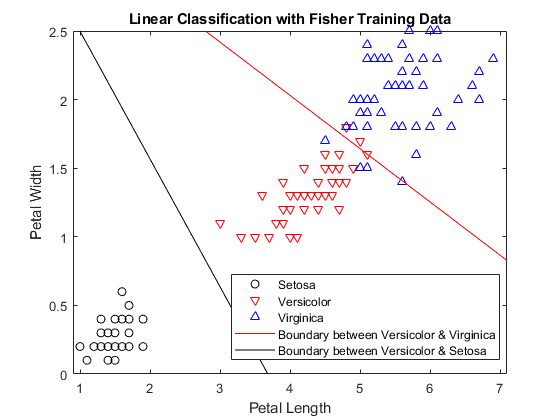
可视化线性判别分析的分类边界GydF4y2Ba
将数据集划分为样本和训练数据,并利用线性判别分析对样本数据进行分类。然后,可视化决策边界。GydF4y2Ba
加载GydF4y2Ba鱼腥草GydF4y2Ba数据集。创建GydF4y2Ba集团GydF4y2Ba作为包含虹膜物种的字符向量的细胞阵列。创建GydF4y2BaPLGydF4y2Ba和GydF4y2BaPWGydF4y2Ba作为数字向量,分别包含花瓣的长度和宽度测量值。GydF4y2Ba
负载GydF4y2Ba鱼腥草GydF4y2Ba组=物种;PL =量(:3);PW =量(:4);GydF4y2Ba
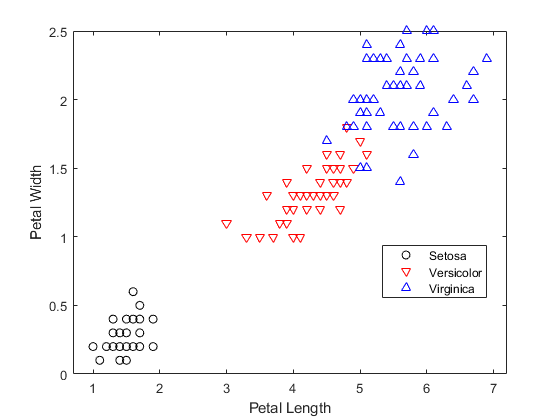
图中萼片长度(GydF4y2BaPLGydF4y2Ba)及宽度(GydF4y2BaPWGydF4y2Ba)刚毛鸢尾、杂色鸢尾和弗吉尼亚鸢尾的测量。GydF4y2Ba
h1=gscatter(PL,PW,物种,GydF4y2Ba“、”GydF4y2Ba,GydF4y2Ba“ov ^”GydF4y2Ba,[],GydF4y2Ba“关闭”GydF4y2Ba);传奇(GydF4y2Ba“Setosa”GydF4y2Ba,GydF4y2Ba“花色”GydF4y2Ba,GydF4y2Ba“维吉尼亚”GydF4y2Ba,GydF4y2Ba“位置”GydF4y2Ba,GydF4y2Ba“最佳”GydF4y2Ba)包含(GydF4y2Ba“花瓣长度”GydF4y2Ba) ylabel (GydF4y2Ba“花瓣宽度”GydF4y2Ba)GydF4y2Ba
将观察数据随机划分为训练集(GydF4y2BatrainingDataGydF4y2Ba)及样本集(GydF4y2Ba样本数据GydF4y2Ba)与分层,利用群体信息GydF4y2Ba集团GydF4y2Ba.指定10%的抵抗样本GydF4y2Ba样本数据GydF4y2Ba.GydF4y2Ba
rng (GydF4y2Ba“默认”GydF4y2Ba)GydF4y2Ba%的再现性GydF4y2Ba简历= cvpartition(集团GydF4y2Ba“坚持”GydF4y2Ba, 0.10);trainInds =培训(简历);sampleInds =测试(简历);trainingData = [PL(trainInds) PW(trainInds)];sampleData = [PL(sampleInds) PW(sampleInds)];GydF4y2Ba
分类GydF4y2Ba样本数据GydF4y2Ba采用线性判别分析。GydF4y2Ba
[类、犯错后,logp,多项式系数]=分类(sampleData、trainingData组(trainInds));GydF4y2Ba
检索系数GydF4y2BaKGydF4y2Ba和GydF4y2BaLGydF4y2Ba对于第二类和第三类之间的线性边界。GydF4y2Ba
K =多项式系数(2、3).const;L =多项式系数(2、3).linear;GydF4y2Ba
第二类和第三类的分界线是由这个方程定义的GydF4y2Ba .绘制第二和第三类之间的分界线。GydF4y2Ba
f = @(x1,x2) K + L(1)*x1 + L(2)*x2;持有GydF4y2Ba在GydF4y2Bah2 = fimplicit (f。9 7.1 0 2.5]);h2。颜色=GydF4y2Ba“r”GydF4y2Ba;h2.DisplayName=GydF4y2Ba“Versicolor与Virginica的界限”GydF4y2Ba;GydF4y2Ba

检索系数GydF4y2BaKGydF4y2Ba和GydF4y2BaLGydF4y2Ba对于第一类和第二类之间的线性边界。GydF4y2Ba
K=系数(1,2).常数;L=系数(1,2).线性;GydF4y2Ba
画出第一个类和第二个类之间的线。GydF4y2Ba
f = @(x1,x2) K + L(1)*x1 + L(2)*x2;h3 = fimplicit (f。9 7.1 0 2.5]);持有GydF4y2Ba关GydF4y2Bah3。颜色=GydF4y2Ba“k”GydF4y2Ba;h3.DisplayName=GydF4y2Ba“Versicolor与Setosa之间的界限”GydF4y2Ba;轴GydF4y2Ba紧GydF4y2Ba标题(GydF4y2Ba“使用Fisher训练数据的线性分类”GydF4y2Ba)GydF4y2Ba
输入参数GydF4y2Ba
输出参数GydF4y2Ba
选择功能GydF4y2Ba
这个GydF4y2BafitcdiscrGydF4y2Ba函数还执行判别分析GydF4y2BafitcdiscrGydF4y2Ba函数并预测新数据的标签GydF4y2Ba预测GydF4y2Ba函数。这个GydF4y2BafitcdiscrGydF4y2Ba该函数支持交叉验证金宝app和超参数优化,并且不需要每次进行新预测或更改先验概率时都对分类器进行拟合。GydF4y2Ba
参考文献GydF4y2Ba
[1] Krzanowski,Wojtek.J。GydF4y2Ba多元分析原理:用户的视角GydF4y2Ba.纽约:牛津大学出版社,1988。GydF4y2Ba
乔治·a·F·塞伯GydF4y2Ba多变量的观察GydF4y2Ba.《中国科学院大学学报(自然科学版)》,1984。GydF4y2Ba
另见GydF4y2Ba
泰姬陵GydF4y2Ba|GydF4y2Ba菲茨特里GydF4y2Ba|GydF4y2BaClassificationDiscriminantGydF4y2Ba|GydF4y2Ba预测GydF4y2Ba|GydF4y2BafitcdiscrGydF4y2Ba|GydF4y2BafitcnbGydF4y2Ba
选择一个网站GydF4y2Ba
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:GydF4y2Ba.GydF4y2Ba
选择GydF4y2Ba网站GydF4y2Ba你也可以从以下列表中选择一个网站:GydF4y2Ba
美洲GydF4y2Ba
- 美国拉丁GydF4y2Ba(西班牙语)GydF4y2Ba
- 加拿大GydF4y2Ba(英语)GydF4y2Ba
- 美国GydF4y2Ba(英语)GydF4y2Ba
欧洲GydF4y2Ba
- 比利时GydF4y2Ba(英语)GydF4y2Ba
- 丹麦GydF4y2Ba(英语)GydF4y2Ba
- 德国GydF4y2Ba(德语)GydF4y2Ba
- 埃斯帕尼亚GydF4y2Ba(西班牙语)GydF4y2Ba
- 芬兰GydF4y2Ba(英语)GydF4y2Ba
- 法国GydF4y2Ba(法兰西)GydF4y2Ba
- 爱尔兰GydF4y2Ba(英语)GydF4y2Ba
- 意大利GydF4y2Ba(意大利语)GydF4y2Ba
- 卢森堡GydF4y2Ba(英语)GydF4y2Ba
- 荷兰GydF4y2Ba(英语)GydF4y2Ba
- 挪威GydF4y2Ba(英语)GydF4y2Ba
- ÖsterreichGydF4y2Ba(德语)GydF4y2Ba
- 葡萄牙GydF4y2Ba(英语)GydF4y2Ba
- 瑞典GydF4y2Ba(英语)GydF4y2Ba
- 瑞士GydF4y2Ba
- 联合王国GydF4y2Ba(英语)GydF4y2Ba
亚太地区GydF4y2Ba
- 澳大利亚GydF4y2Ba(英语)GydF4y2Ba
- 印度GydF4y2Ba(英语)GydF4y2Ba
- 新西兰GydF4y2Ba(英语)GydF4y2Ba
- 中国GydF4y2Ba
- 日本GydF4y2Ba(日本語)GydF4y2Ba
- 한국GydF4y2Ba(한국어)GydF4y2Ba
