fitcnb
训练多类朴素贝叶斯模型
语法
描述
Mdl= fitcnb (资源描述,ResponseVarName)Mdl),由表中预测者训练资源描述和变量中的类标签资源描述。ResponseVarName.
例子
训练朴素贝叶斯分类器
载入费雪的虹膜数据集。
负载fisheririsX =量(:,3:4);Y =物种;汇总(Y)
价值计数百分比刚毛50 33.33%杂色50 33.33%维吉尼亚50 33.33%
该软件可以使用朴素贝叶斯方法对两个以上类的数据进行分类。
训练朴素贝叶斯分类器。最好的做法是指定类的顺序。
Mdl = fitcnb (X, Y,“类名”, {“塞托萨”,“多色的”,“维吉尼亚”})
Mdl=ClassificationNaiveBayes ResponseName:'Y'分类预测值:[]类名:{'setosa''versicolor''virginica'}ScoreTransform:'none'NumObservations:150个分发名:{'normal''normal'}分发参数:{3x2 cell}属性、方法
Mdl是一个培训分类朴素贝叶斯分类器。
默认情况下,软件使用具有一些平均值和标准偏差的高斯分布对每个类别内的预测分布进行建模。使用点符号显示特定高斯拟合的参数,例如,显示类别内第一个特征的拟合setosa.
(Mdl setosaIndex =比较字符串。一会,“塞托萨”);估计= Mdl。DistributionParameters {setosaIndex 1}
估计=2×11.4620 - 0.1737
的意思是1.4620标准差是0.1737.
绘制高斯曲线。
图gscatter (X (: 1), (:, 2), Y);甘氨胆酸h =;cxlim = h.XLim;cylim = h.YLim;持有在Params = cell2mat (Mdl.DistributionParameters);μ= Params (2 * (1:3) 1, 1:2);提取平均值σ= 0 (2,2,3);为Sigma(:,:,j) = diag(Params(2*j,:)).^2;%创建对角协方差矩阵xlim = Mu(j,1) + 4*[-1 1]*根号(Sigma(1,1,j));ylim = Mu(j,2) + 4*[-1 1]*√(Sigma(2,2,j));f = @ (x, y) arrayfun (@ (x0, y0) mvnpdf (x0 y0,μ(j,:),σ(:,:,j)), x, y);fcontour (f, [xlim ylim])%绘制多元正态分布的轮廓结束h、 XLim=cxlim;h.YLim=cylim;标题(朴素贝叶斯分类器- Fisher虹膜数据)包含(“花瓣长度(厘米)”) ylabel (“花瓣宽度(cm)”)传奇(“塞托萨”,“多色的”,“维吉尼亚”)举行从
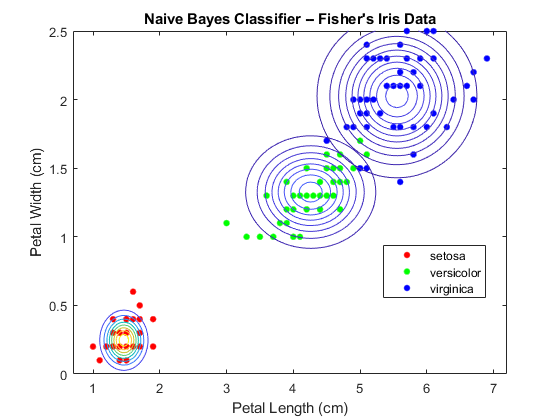
您可以使用名称-值对参数更改默认发行版“DistributionNames”.例如,如果一些预测因子是分类的,那么您可以使用“DistributionNames”、“mvmn”.
在训练朴素贝叶斯分类器时指定先验概率
为费雪的虹膜数据集构造朴素贝叶斯分类器。此外,指定训练期间的先验概率。
载入费雪的虹膜数据集。
负载fisheririsX =量;Y =物种;一会= {“塞托萨”,“多色的”,“维吉尼亚”};%课堂秩序
X是一个数字矩阵,包含四个花瓣测量150鸢尾。Y是包含相应虹膜种类的字符向量的细胞阵列。
默认情况下,先验类概率分布是数据集中类的相对频率分布。在这种情况下,每种物种的先验概率是33%。然而,假设你知道在种群中有50%的鸢尾是刚毛鸢尾,20%是花斑鸢尾,30%是弗吉尼亚鸢尾。您可以通过在训练期间指定此分布为先验概率来合并此信息。
训练朴素贝叶斯分类器。指定类的顺序和先验类的概率分布。
Prior = [0.5 0.2 0.3];Mdl = fitcnb (X, Y,“类名”一会,“之前”之前,)
Mdl = ClassificationNaiveBayes ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'setosa' 'versicolor' 'virginica'} ScoreTransform: 'none' NumObservations: 150 DistributionNames: {'normal' ' 'normal' ' 'normal'} DistributionParameters: {3x4 cell}属性,方法
Mdl是一个培训分类朴素贝叶斯分类器及其某些属性将显示在命令窗口中。软件将预测值视为独立的给定类别,默认情况下,使用正态分布拟合预测值。
朴素贝叶斯算法在训练过程中不使用先验类概率。因此,您可以在训练后使用点符号指定先前的类概率。例如,假设您想要查看使用默认先验类概率的模型和使用不同的模型之间的性能差异之前.
建立一个新的朴素贝叶斯模型基于Mdl,并规定先验类概率分布为经验类分布。
defaultPriorMdl = Mdl;FreqDist = cell2table(汇总(Y));defaultPriorMdl。之前=FreqDist{:,3};
软件将先验类的概率归一化求和为1.
用10倍交叉验证估计两个模型的交叉验证误差。
rng (1);%为了再现性defaultCVMdl=crossval(defaultPriorMdl);defaultLoss=kfoldLoss(defaultCVMdl)
defaultLoss = 0.0533
CVMdl = crossval (Mdl);损失= kfoldLoss (CVMdl)
损失=0.0340
Mdl性能优于defaultPriorMdl.
为朴素贝叶斯分类器指定预测器分布
载入费雪的虹膜数据集。
负载fisheririsX =量;Y =物种;
使用每个预测器训练朴素贝叶斯分类器。最好的做法是指定类的顺序。
Mdl1=fitcnb(X,Y,...“类名”, {“塞托萨”,“多色的”,“维吉尼亚”})
Mdl1=ClassificationNaiveBayes ResponseName:'Y'分类预测值:[]类名:{'setosa''versicolor''virginica'}ScoreTransform:'none'NumObservations:150个分布名:{'normal''normal''normal''normal'}分布参数:{3x4 cell}属性、方法
Mdl1。DistributionParameters
ans =3×4单元阵列{2x1 double}{2x1 double}{2x1 double}{2x1 double}{2x1 double}{2x1 double}{2x1 double}{2x1 double}{2x1 double}{2x1 double}{2x1 double}
Mdl1。DistributionParameters {1,2}
ans =2×13.4280 - 0.3791
默认情况下,软件将预测值在每个类别中的分布建模为高斯分布,具有一定的平均值和标准偏差。有四个预测值和三个类别级别。每个单元格位于Mdl1。DistributionParameters对应一个数值向量,其中包含各分布的均值和标准差,如刚毛鸢尾萼片宽度的均值和标准差为3.4280和0.3791,分别。
估计混淆矩阵Mdl1.
isLabels1 = resubPredict (Mdl1);ConfusionMat1 = confusionchart (Y, isLabels1);
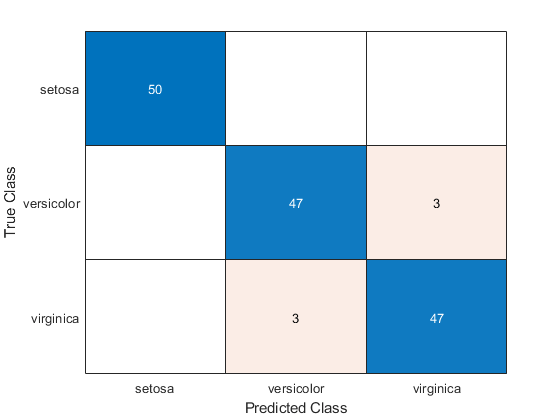
元素(j,k)的混淆矩阵图表示该软件分类的观察结果的数量k,但他们确实在课堂上j根据数据。
使用预测因子1和2(萼片长度和宽度)的高斯分布和预测因子3和4(花瓣长度和宽度)的默认正态核密度重新训练分类器。
Mdl2 = fitcnb (X, Y,...“DistributionNames”, {“正常”,“正常”,“内核”,“内核”},...“类名”, {“塞托萨”,“多色的”,“维吉尼亚”});Mdl2.分布参数{1,2}
ans =2×13.4280 - 0.3791
软件不会根据内核密度训练参数。相反,软件会选择一个最佳宽度。属性指定宽度“宽度”名称-值对的论点。
估计混淆矩阵Mdl2.
isLabels2 = resubPredict (Mdl2);ConfusionMat2 = confusionchart (Y, isLabels2);
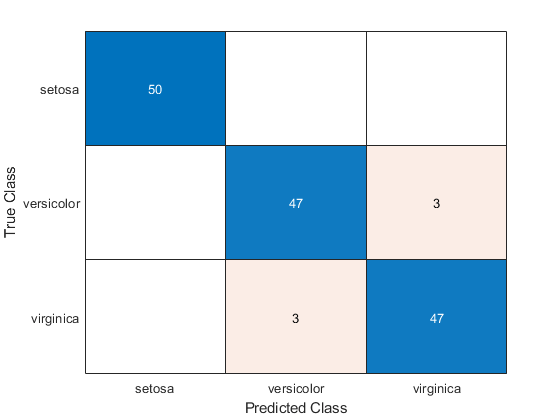
基于混淆矩阵,这两个分类器在训练样本中表现相似。
使用交叉验证比较分类器
载入费雪的虹膜数据集。
负载fisheririsX =量;Y =物种;rng (1);%为了再现性
使用默认选项和交叉验证朴素贝叶斯分类器k倍交叉验证。最好的做法是指定类的顺序。
CVMdl1 = fitcnb (X, Y,...“类名”, {“塞托萨”,“多色的”,“维吉尼亚”},...“CrossVal”,“上”);
默认情况下,软件将每个类中的预测器分布建模为带有一些均值和标准偏差的高斯分布。CVMdl1是一个ClassificationPartitionedModel模型。
创建一个默认的朴素贝叶斯二进制分类器模板,并训练一个纠错、输出代码的多类模型。
t=模板NaiveBayes();CVMdl2=FITCECOCC(X,Y,“CrossVal”,“上”,“学习者”t);
CVMdl2是一个ClassificationPartitionedECOC模型。可以使用与for相同的名称-值对参数为朴素贝叶斯二进制学习器指定选项fitcnb.
比较样本外k-折叠分类错误(误分类观察的比例)。
classErr1 = kfoldLoss (CVMdl1,“LossFun”,“ClassifErr”)
classErr1 = 0.0533
classErr2 = kfoldLoss (CVMdl2,“LossFun”,“ClassifErr”)
classErr2 = 0.0467
Mdl2具有较低的泛化误差。
使用多项式预测器训练朴素贝叶斯分类器
一些垃圾邮件过滤器根据单词或标点符号(称为令牌)在电子邮件中出现的次数将传入的电子邮件分类为垃圾邮件。预测因素是电子邮件中特定单词或标点符号的频率。因此,预测因子构成多项随机变量。
这个例子说明了使用朴素贝叶斯和多项式预测器进行分类。
创建培训数据
假设您观察了1000封电子邮件,并将它们分类为垃圾邮件或非垃圾邮件。通过将-1或1随机赋给y对于每一个电子邮件。
n = 1000;%样本大小rng (1);%为了再现性Y = randsample([-1 1],n,true);%随机标签
要构建预测数据,假设词汇表中有五个标记,每封电子邮件有20个观察到的标记。通过绘制随机的多项式偏差,从这五个标记生成预测数据。与垃圾邮件相对应的标记的相对频率应与非垃圾邮件不同。
tokenProbs = [0.2 0.3 0.1 0.15 0.25;...0.4 0.1 0.3 0.05 0.15];令牌相对频率tokensPerEmail = 20;%为方便起见,固定X=零(n,5);X(Y==1,:)=mnrnd(tokensPerEmail,tokenProbs(1,:),sum(Y==1));X(Y=-1,:)=mnrnd(tokensPerEmail,tokenProbs(2,:),sum(Y=-1));
训练分类器
训练朴素贝叶斯分类器。指定预测器是多项式的。
Mdl = fitcnb (X, Y,“DistributionNames”,“锰”);
Mdl是一个培训分类朴素贝叶斯分类器。
评估样品内的性能Mdl通过估计误分类误差。
isGenRate = resubLoss (Mdl,“LossFun”,“ClassifErr”)
isGenRate = 0.0200
样本内误分类率为2%。
创建新的数据
随机生成代表新一批邮件的偏差。
newN=500;newY=randsample([-1],newN,true);newX=zero(newN,5);newX(newY==1,:)=mnrnd(tokensPerEmail,tokenProbs(1,:),...sum(newY==1);newX(newY==1,:)=mnrnd(tokensPerEmail,tokenProbs(2,:),...总和(newY = = 1));
评估分类器的性能
使用训练有素的朴素贝叶斯分类器对新邮件进行分类Mdl,确定算法是否泛化。
oosGenRate =损失(Mdl newX newY)
oosGenRate = 0.0261
样本外误分类率为2.6%,说明该分类器具有较好的泛化能力。
优化朴素贝叶斯分类器
此示例显示如何使用OptimizeHyperparameters使用名称-值对最小化朴素贝叶斯分类器中的交叉验证损失fitcnb.这个例子使用了Fisher的虹膜数据。
载入费雪的虹膜数据。
负载fisheririsX =量;Y =物种;一会= {“塞托萨”,“多色的”,“维吉尼亚”};
使用“auto”参数优化分类。
为了重现性,设置随机种子并使用“预期改善加成”采集功能。
rng默认的Mdl = fitcnb (X, Y,“类名”一会,“OptimizeHyperparameters”,“汽车”,...“HyperparameterOptimizationOptions”结构(“AcquisitionFunctionName”,...“预期改善加成”))
警告:建议您在优化朴素贝叶斯“宽度”参数时首先标准化所有数值预测器。如果您已经这样做了,请忽略此警告。
|=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar |分布宽度——| | | | |结果运行时| |(观察)| (estim)名字| | ||=====================================================================================================| | 最好1 | | 0.053333 | 0.49673 | 0.053333 | 0.053333正常| | - | | 2 |最好| 0.046667 | 0.77299 | 0.046667 | 0.049998 | 0.11903内核| | | 3 |接受| 0.053333 | 0.19879 | 0.046667 | 0.046667 |正常| - | | | 0.086667 | 4 |接受内核0.8573 | 0.046667 | 0.046668 | 2.4506 | | | 5 |接受| 0.046667 | 1.163 | 0.046667 | 0.046663 | 0.10449内核| | | 6 |接受| 0.073333 | 1.2136 | 0.046667 | 0.046665 | 0.025044内核| | | | 7日接受| 0.046667 | 0.97829 | 0.046667 | 0.046655 | 0.27647内核| | | 8 |接受| 0.046667 | 0.93511 | 0.046667 | 0.046647 | |内核0.2031 | | | 9日接受| 0.06 | 0.9873 | 0.046667 | 0.046658 | 0.44271内核| | | 10 |接受| 0.046667 | 0.7068 | 0.046667 | 0.046618 | 0.2412内核| | | | 11日接受| 0.046667 | 1.0452 | 0.046667 | 0.046619 | 0.071925内核| | | | 12日接受| 0.046667 | 0.58517 | 0.046667 | 0.046612 | 0.083459内核| | | | 13日接受| 0.046667 | 1.6218 |0.15661内核0.046667 | 0.046603 | | | | | 14日接受| 0.046667 | 0.83563 | 0.046667 | 0.046607 | 0.25613内核| | | 15 |接受| 0.046667 | 0.45013 | 0.046667 | 0.046606 | 0.17776内核| | | | 16日接受| 0.046667 | 0.55668 | 0.046667 | 0.046606 | 0.13632内核| | | | 17日接受| 0.046667 | 0.66138 | 0.046667 | 0.046606 | |内核18 0.077598 | | |接受| 0.046667 | 0.66761 | 0.046667 | 0.046626 | 0.25646内核| | | | 19日接受| 0.046667 | 1.0853 | 0.046667 | 0.046626 | 0.093584内核| | | 20 |接受| 0.046667 | 1.4829 | 0.046667 | 0.046627 | 0.061602内核| | |=====================================================================================================| |我ter | Eval | Objective | Objective | BestSoFar | BestSoFar | Distribution-| Width | | | result | | runtime | (observed) | (estim.) | Names | | |=====================================================================================================| | 21 | Accept | 0.046667 | 1.2761 | 0.046667 | 0.046627 | kernel | 0.066532 | | 22 | Accept | 0.093333 | 0.58556 | 0.046667 | 0.046618 | kernel | 5.8968 | | 23 | Accept | 0.046667 | 0.64275 | 0.046667 | 0.046619 | kernel | 0.067045 | | 24 | Accept | 0.046667 | 1.4991 | 0.046667 | 0.04663 | kernel | 0.25281 | | 25 | Accept | 0.046667 | 0.68537 | 0.046667 | 0.04663 | kernel | 0.1473 | | 26 | Accept | 0.046667 | 0.6169 | 0.046667 | 0.046631 | kernel | 0.17211 | | 27 | Accept | 0.046667 | 0.42397 | 0.046667 | 0.046631 | kernel | 0.12457 | | 28 | Accept | 0.046667 | 0.49855 | 0.046667 | 0.046631 | kernel | 0.066659 | | 29 | Accept | 0.046667 | 1.5052 | 0.046667 | 0.046631 | kernel | 0.1081 | | 30 | Accept | 0.08 | 0.79041 | 0.046667 | 0.046628 | kernel | 1.1048 |
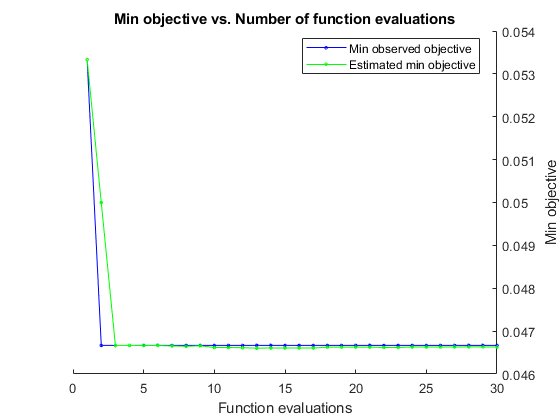
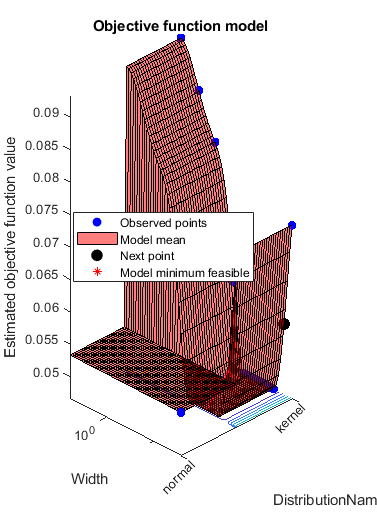
__________________________________________________________ 优化完成。maxobjective达到30个。总函数计算:30总运行时间:60.7285秒总目标函数计算时间:25.8256DistributionNames Width _________________ _______ kernel 0.11903 Observed objective function value = 0.046667 Estimated objective function value = 0.046667 function evaluation time = 0.77299 Best Estimated feasible point (according to models):DistributionNames Width _________________ _______ kernel 0.25613估计的目标函数值= 0.046628估计的函数求值时间= 0.8268
Mdl = ClassificationNaiveBayes ResponseName:‘Y’CategoricalPredictors:[]类名:{“setosa”“杂色的”“virginica”}ScoreTransform:“没有一个”NumObservations: 150 HyperparameterOptimizationResults: [1 x1 BayesianOptimization] DistributionNames: {1} x4细胞DistributionParameters: {} 3 x4细胞内核:{1}x4细胞支持:{1}x4细胞宽度:金宝app[3x4 double]属性,方法
输入参数
输出参数
更多关于
提示
用于对基于计数的数据进行分类,例如bag-of-tokens模型,使用多项分布(例如,集合
“DistributionNames”、“锰”).在训练模型之后,您可以生成C/ c++代码来预测新数据的标签。生成C/ c++代码需要MATLAB编码器™. 有关详细信息,请参阅代码生成简介.
算法
中频预测变量
j有条件正态分布(见分配名称软件通过计算特定类别的加权平均值和加权标准偏差的无偏估计值,将分布拟合到数据。每节课k:预测器的加权平均数j是
在哪里w我重量是用于观察的吗我.该软件将一个类中的权重标准化,这样它们的总和就等于该类的先验概率。
预测器加权标准差的无偏估计j是
在哪里z1 |k是类内权重的总和吗k和z2 |k是类中权重的平方和k.
如果所有预测变量组成条件多项式分布(您指定
“DistributionNames”、“锰”),该软件适合使用bag-of-tokens模型.软件存储该令牌的概率j出现在课堂上k在财产中DistributionParameters {.使用添加剂平滑[2],估计的概率是k,j}地点:
令牌的加权出现次数是多少j在课堂上k.
nk课堂上观察的次数是多少k.
重量是用于观察的吗我.该软件将一个类中的权重标准化,这样它们的总和就等于该类的先验概率。
哪个是类中所有令牌出现的加权总数k.
中频预测变量
j具有条件多元多项分布:该软件收集了一个独特的关卡列表,并将排序后的列表存储在其中
CategoricalLevels,并将每一层视为一个容器。每个预测器/类组合是一个独立的,独立的多项随机变量。为每一个类
k,该软件使用存储的列表计算每个类别级别的实例CategoricalLevels {.j}软件储存预测的概率
j,在课堂上k,水平l在财产中DistributionParameters {,为所有层次k,j}CategoricalLevels {.使用添加剂平滑[2],估计的概率是j}地点:
哪个是哪个预测值的观察值的加权数j=l在课堂上k.
nk课堂上观察的次数是多少k.
如果xij=l,否则为0。
重量是用于观察的吗我.该软件将一个类中的权重标准化,这样它们的总和就等于该类的先验概率。
米j预测器中不同水平的数量j.
米k是课堂上的加权观察数吗k.
参考文献
[1] 黑斯蒂、T、R.蒂布什拉尼和J.弗里德曼。统计学习的要素,第二版。纽约:施普林格,2008年。
扩展能力
你也可以从以下列表中选择一个网站:
